
ilovechoonsik
[STARTERS 4기 TIL] Python 시계열 #1 (230307) 본문

📖 오늘 내가 배운 것
1. Numpy
2. Pandas
3. 결측치 다루기
4. Groupby
5. 일반연산
6. 데이터 입출력
7. 시각화
1. Numpy
1.1 Numpy란?
NumPy는 파이썬을 위한 강력한 선형 대수 라이브러리! (배열로 저장된 대용량 데이터 처리에 용이)
📌 배워야 하는 이유?
1. PyData 생태계의 거의 모든 라이브러리 (Pandas, Scippy, Scikit-learn 등)가 NumPy를 주요 구성 요소 중 하나로 사용!
2. 분석 예제를 위한 데이터를 생성하는 데 사용
📌 강력한 점
NumPy는 또한 C 라이브러리와 바인딩을 가지고 있기 때문에 속도가 빠름
1.2 Numpy 배열
(1) 기존 값 넘파이 배열로 만들기
np.array(list)
(2) 넘파이 배열 직접 생성
np.arange(start,stop,int) : start - stop 까지 int(텀) 주면서 넘파이 배열 출력
zeros() : 인자 개수 만큼 0 들어가는 넘파이 배열 생성
ones() : 인자 개수 만큼 1 들어가는 넘파이 배열 생성
linspace(start, stop, len) : start-stop 사이의 임의의 숫자 len개 출력
eye() : 대각 행렬 생성
📌 Random
np.random.rand(행, 열) : 0~1 범위에서 균일한 분포를 갖는 수를 행, 열 형태로 출력
np.random.randn(행,열) : 평균 0, 표준편차 1의 정규분포 난수를 행, 열 형태로 출력
np.random.randint(min, max, n) : min 포함, max 제외한 범위에서 임의의 n개 정수 반환
np.random.seed() : 이전에 사용한 난수들을 다시 가져옴
(3) 넘파이 배열 -> 행,열 형태로 변환
넘파이배열..reshape(행,열) : 넘파이 배열을 행, 열 형태로 변환 (배열 요소가 행열 범위 초과 시 에러)
(4) 넘파이 배열 통계
넘파이배열.max() : 배열 요소 중 최댓값
넘파이배열.argmax() : 배열 요소 중 최댓값의 index
넘파이배열.min() : 배열 요소 중 최솟값
넘파이배열.argmin() : 배열 요소 중 최솟값의 index
(5) 배열 형태 확인 및 재정의
넘파이배열.shape : 배열 형태 확인
넘파이배열.reshape(행,열) : 배열 형태 행,열 인자로 재정의
(6) 배열 내 데이터 타입 확인
넘파이배열.dtype : 배열 요소 데이터 타입 확인
1.3 Numpy 인덱싱, 슬라이싱

(1) 인덱싱 : 1,2차원 배열에서 단일 요소 가져오기
넘파이배열[index] : 배열에서 해당 index값 리턴
📌 matrices(2차원 행 열) 인덱싱
arr_2d = np.array(([5,10,15],[20,25,30],[35,40,45]))
'''
array([[ 5, 10, 15],
[20, 25, 30],
[35, 40, 45]])
'''
#Indexing row
arr_2d[1]
# array([20, 25, 30])
#Format is arr_2d[row][col] or arr_2d[row,col]
#Getting individual element value
arr_2d[1][0]
# 20
# Getting individual element value
arr_2d[1,0]
# 20
(2) 슬라이싱 : 1,2차원 배열에서 요소 슬라이스, 청크 가져오기
넘파이배열[mini:maxi] : mini ~ maxi - 1 값 넘파이 배열로 리턴
📌 matrices(2차원 행열) 슬라이싱
arr_2d = np.array(([5,10,15],[20,25,30],[35,40,45]))
'''
array([[ 5, 10, 15],
[20, 25, 30],
[35, 40, 45]])
'''
# 2D array slicing
#Shape (2,2) from top right corner
arr_2d[:2,1:]
# array([[10, 15],
# [25, 30]])
#Shape bottom row
arr_2d[2]
# array([35, 40, 45])
arr_2d[2,:]
# array([35, 40, 45])
(3) 브로드캐스팅 : 넘파이는 파이썬 리스트와 다르게 함수와 연산을 브로드캐스트 할 수 있다.
ex) 배열 가져와서 모든 요소에 덧셈 가능
arr = np.arange(0,11)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
arr / 2
# array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5, 5. ])
arr[0:5]=100
arr
# array([100, 100, 100, 100, 100, 5, 6, 7, 8, 9, 10])📌 브로드캐스팅시 copy 사용 권장 : 원본 영향받지 않고 메모리 관리
(4) 조건부 선택 : boolean indexing - 비교 연산자 이용
arr = np.arange(1,11)
# array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
bool_arr = arr>4
bool_arr
# array([False, False, False, False, True, True, True, True, True, True])
arr[bool_arr]
# array([ 5, 6, 7, 8, 9, 10])
arr[arr>2]
# array([ 3, 4, 5, 6, 7, 8, 9, 10])
1.4 Numpy 연산
(1) 산수
arr = np.arange(0,10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr + arr
# array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
arr * arr
# array([0,1, 4, 9, 16, 25, 36, 49, 64, 81])
arr - arr
# array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
arr**3
# array([0,1,8,27,64, 125, 216, 343, 512, 729], dtype=int32)
# 0을 0으로 나누면 연산 결과는 NaN
arr/arr
array([nan, 1., 1., 1., 1., 1., 1., 1., 1., 1.])
# 연산 결과 무한대일 경우
1/arr
# array([inf, 1., 0.5, 0.33333333, 0.25, 0.2,0.16666667,0.14285714, 0.125,0.11111111])
(2) 범용
np.sqrt() : 제곱근
np.exp() : 자연상수 지수배 계산
np.sin() : 삼각함수
np.log() : 로그함수
(3) 요약
sum() : 배열 요소들 합
max() : 배열 요소 내 최댓값
mean() : 배열 요소들 평균
std(): 배열 요소들 표준편차
var(): 배열 요소들 분산
percentile() : 배열 사분위수
2. Pandas
📌 Numpy와 Python List의 차이
: Numpy는 요소별 브로드캐스팅 연산 능력 갖는다
📌 Numpy와 Pandas Series의 차이
: 구조는 같지만 Numpy는 인덱스가 숫자에 한정! 반면, Series는 문자열 인덱스 가능, 데이터 불러올 수 있다
-> 사람들이 인덱스에 대해 정수 보다는 범주와 이름 측면에서 잘 기억하기 때문에 Series가 나온 것!
2.1 Series
어떤 데이터 타입이든 보유할 수 있는 레이블(label)링된 1차원 배열
시리즈의 파라미터는 우측과 같다 (Shift + Tab으로 확인)
기본적으로 data, index 갖고 있으며
index에는 레이블 또는 이름 지정할 수 있음
(1) Series 생성
📌 list로 생성 (numpy array 가능)
pd.Series(data=[list or num_arr], index=[list])
📌 dict로 생성
pd.Series(data=[dict])
(2) 추출 및 연산
📌 추출
Series명[index] : 해당 index에 value 출력
📌 연산
ser1 = pd.Series([1,2,3,4],index = ['USA', 'Germany','USSR', 'Japan'])
ser2 = pd.Series([1,2,5,4],index = ['USA', 'Germany','Italy', 'Japan'])
ser1 + ser2
'''
Germany 4.0
Italy NaN
Japan 8.0
USA 2.0
USSR NaN
dtype: float64
'''index 일치하는 value만 연산 가능, 일치하지 않으면 NaN
Series의 병합

2.2 DataFrame
같은 인덱스를 공유하는 다수의 시리즈 집합! 테이블 형식의 데이터 집합
다수의 열과 인덱스를 갖는다.
(1) DataFrame 생성
우측과 같은 파라미터로 생성할 수 있음
df = pd.DataFrame(randn(5,4),index='A B C D E'.split(),columns='W X Y Z'.split())
df# '문자열'.split() 으로 빠르게 생성
📌 완성된 DataFrame
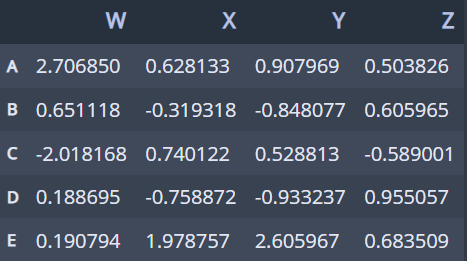
(2) 선택과 인덱싱
📌 컬럼 기준으로 가져오는 기본적인 방법
df['컬럼명']
df[['컬럼명','컬럼명']]
df.컬럼명 : 추천 x 메소드 체이닝 사용 시 가시성 떨어짐
📌 새로운 열 생성
df['컬럼명'] = 추가하고 싶은 조건
📌 열 삭제
df.drop('컬럼명', axis=1)
# 행은 df.drop('컬럼명', axis=0)
📌 행 가져오기
df.loc[인덱스이름]
df.iloc[행번호]
📌 행, 열 함께 가져오기
df.loc[행리스트,열리스트]
📌 boolean indexing
df[df 조건식] : 전부 가져오고 조건 해당하지 않으면 NaN으로
df[df[컬럼명] 조건식] : 조건 참인 df
df[df[컬럼명] 조건식][컬럼명] : 컬럼명 가져오기
df[df[컬럼명] 조건식][컬럼리스트] : 조건에 해당하는 컬럼 df
df[(df['W']>0) & (df['Y'] > 1)] : and 연산도 가능
(3) 인덱스 설정
📌 인덱스 초기화, 인덱스 설정
df.reset_index() : 현재 index를 컬럼으로, 새로운 index는 0부터 순차적으로 할당
df.set_index(컬럼명) : 컬럼을 index로
(4) 데이터 프레임 요약
describe() : 기술통계 한눈에
dtypes : 컬럼별 데이터 타입
info() : df 전반적 정보 제공
3. 결측치 다루기
📌 결측치? : 데이터에 값이 없다는 것!
📌 결측치 표현 : 공란, NA(Not Available), NaN(Not a Number), Null
📌 결측치 처리 : 상황에 따라 삭제, 대치
- 삭제
df.dropna() : 결측치 존재하는 행 or 열 삭제 # axis=0 : 행단위, axis=1 : 열단위
df.dropna(thresh=2) : NaN이 2개 이상 있어야 삭제한다~ thresh로 임계값 설정
- 대치
df.fillna(value=0) : 0으로 모든 결측치 대치
df.fiina(df.mean()) : 평균으로 대치
df['A'].fillna(value=df['A'].mean()) : 컬럼 'A' 평균으로 'A'의 NaN 대치
# 시계열 데이터에서의 결측치?
시계열 데이터에서는 보통 결측치가 많이 보이지 않는다~
시계열로 존재한다는 것은 웬만하면 실제로 표현할 데이터가 존재한다는 뜻이기 때문
4. Groupby
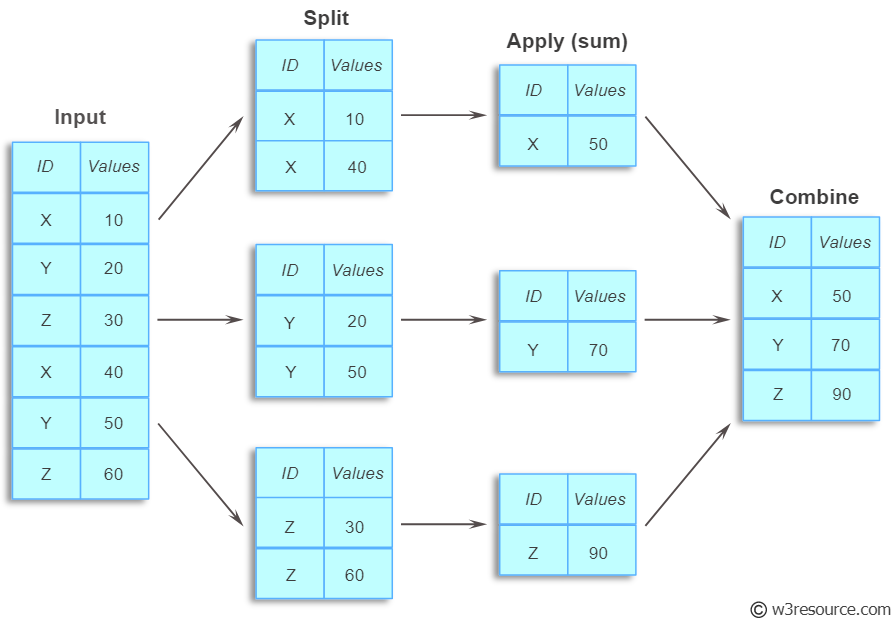
데이터를 그룹별로 분할하여 독립된 그룹에 대하여 별도로 데이터를 처리(혹은 적용)하거나 그룹별 통계량을 확인하고자 할 때 유용한 함수! 작동 원리는 위 사진과 같다
📌 사용법
df.groupby(컬럼).통계함수
df.groupby(컬럼리스트).통계함수
df.groupby(컬럼리스트)[컬럼].통계함수
df.groupby(컬럼리스트)[컬럼리스트].통계함수
# transpose() : 전치행렬함수! 행-열을 바꿔준다
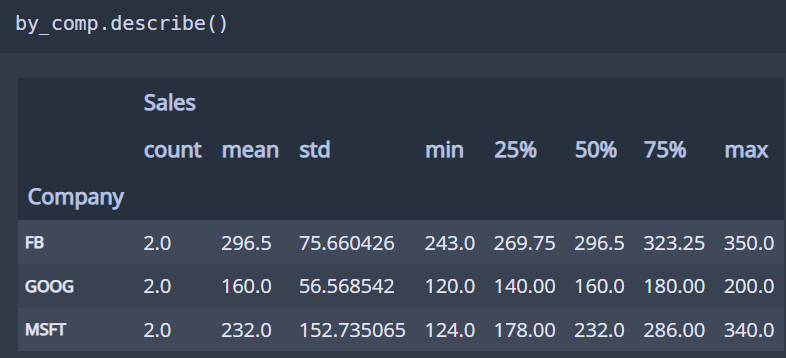
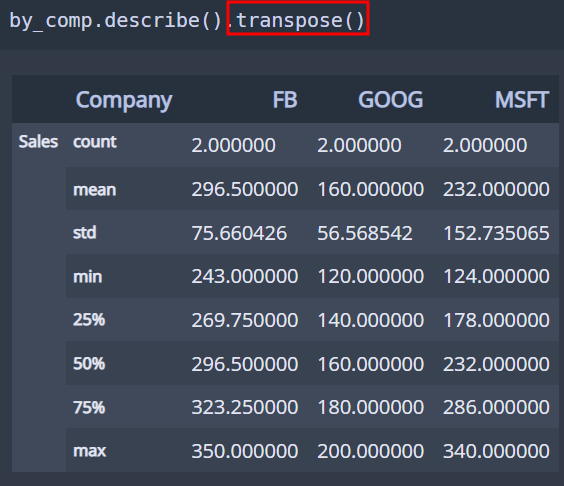
5. 일반연산
📌 Unique Value
unique() : 고윳값
nunique() : 고윳값
value_counts() : 각 고윳값의 총 개수
📌 함수 적용하기
.apply(함수) : 원하는 함수를 df에 적용할 수 있다. 전체 데이터, 특정 열 전부 가
📌 열 삭제
del df[컬럼명]
📌 정렬
df.sort_values(by='컬럼')
# by='컬럼' : 해당 컬럼 기준으로 정렬
# ascending=False : 내림차순
6. 데이터 입출력
📌 CSV
pd.read_csv('csv파일') : csv input
df.to_csv('csv 파일',index=False) : csv output
📌 Excel
pd.read_excel('Excel_Sample.xlsx',sheet_name='Sheet1') : excel input
df.to_excel('Excel_Sample.xlsx',sheet_name='Sheet1') : excel output
📌 HTML
pd.read_html('html파일') : html input
7. 시각화
📌 그래프 종류
df.plot.hist() histogram # bins= : 히스토그램 분포 조절은 bins 파라미터로!
df.plot.bar() bar chart # stacked=True : 바가 쌓이는 형태로 표현
df.plot.barh() horizontal bar chart
df.plot.line() line chart
df.plot.area() area chart
df.plot.scatter() scatter plot # c, s : 마커 색상과 크기 (크기는 * 연산으로 키울 수 있음)
df.plot.box() box plot
df.plot.kde() kde plot : 추정분포
df.plot.hexbin() hexagonal bin plot
df.plot.pie() pie chart
생소했던 파라미터
.autoscale(enable=True, axis='both', tight=True) : x,y축 끝단에 그래프 딱 떨어지게 만들기
📌 라인 스타일
| PROPERTY | CODE | VALUE | EFFECT |
| linestyle | ls | '-' | solid line (default) |
| linestyle | ls | '--' | dashed line |
| linestyle | ls | '-.' | dashed/dotted line |
| linestyle | ls | ':' | dotted line |
| color | c | string | |
| linewidth | lw | float |
📌 간단 plot
ax = df2.plot(figsize=(8,3))
ax.autoscale(axis='x',tight=True)
ax.legend(loc=3, bbox_to_anchor=(1.0,0.1));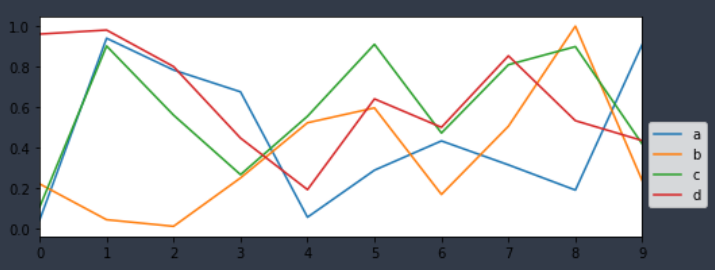
💪🏻 앞으로 개선해야 할 점 (추가로 배워야 할 점)
📌 판다스, 시각화는 이전에 배운 내용이라 복습할 겸 들을 수 있어서 좋았다!
처음 배워본 넘파이는 중요한 만큼 본격적으로 분석 들어가기 전에 복기해 보자~👻
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] 중간 평가 대비 Python, SQL 복습 (230309,10) (0) | 2023.03.10 |
|---|---|
| [STARTERS 4기 TIL] Python 시계열 #2 (230308) (0) | 2023.03.09 |
| [STARTERS 4기 TIL] Tableau 고급 #2 (230306) (0) | 2023.03.06 |
| [STARTERS 4기 TIL] Tableau 고급 #1 (230303) (0) | 2023.03.06 |
| [STARTERS 4기 TIL] Tableau 기초 #2 (230302) (0) | 2023.03.02 |



