
ilovechoonsik
유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 11주차 학습 일지 본문

1. 이번 주에 어떤 것을 배웠나요? 겪은 시행착오/어려운 점은?
1.1 SQL 미니 프로젝트



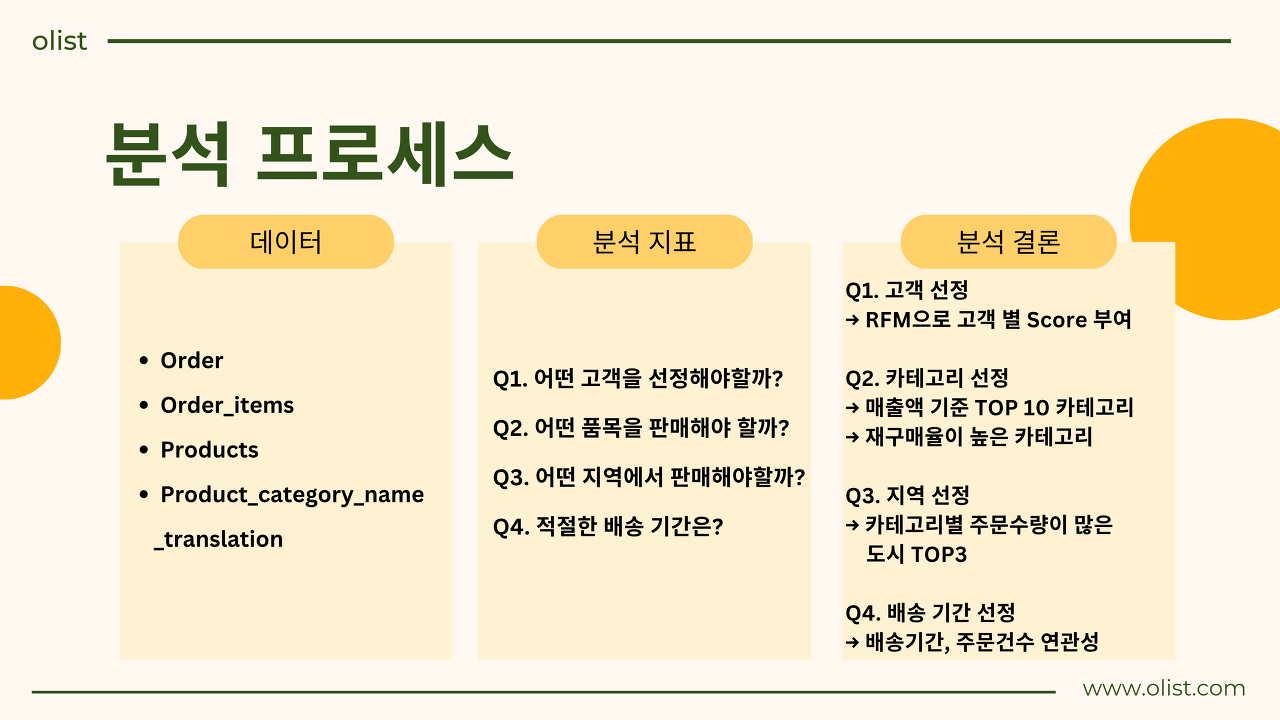










📌 분석 프로세스
📌 우리는?
: Olist에 입점하려는 셀러
📌 분석 목적
: Olist 상위 고객들 특성 파악 후 이에 맞춰 성공적인 입점/셀링 전략 수립
📌 분석 흐름
1. 어떤 고객을 대상으로 해야 할까?
- RFM 기준
- 최근 활성화 여부, 구매 횟수, 총 구매액 3가지 지표를 통해 고
2. 어떤 품목을 판매해야 할까?
- 매출 TOP 10 카테고리
- 꾸준히 판매되고 있는 카테고리 = 카테고리별 재구매율
3. 어떤 지역에서 판매해야 할까?
- 주문자와 판매자가 거리, 배송기간, 주문건수 상관관계
- 2번 품목이 주로 판매되는 지역 TOP 3
📌 피드백
📌 우리 조
- 셀러 입장에서의 고객 분석이라 한다면? RFM 적절한가?
우리가 가지고 있는 데이터를 봤을 때는 RFM 적절하지 않다~
셀러라면? 여기에 입점을 하기 위해 고려해야 할 것?
어떤 상품이 잘 팔릴까? 경쟁자?
- flow는 좋았다
- 목적 부분이 부실하다! 우리가 뭘 할 거다~가 앞에서 명확해야 함!
📌 다른 조
- 어떻게 추출해서 SQL 결과 나온 거 테이블 보여주기
- 글씨가 너무 작다!! 크게 확대해서 주요 부분은 가시성 챙겨주기
- TOP DOWN으로 분석 개요 들어가는 거 좋았다!
- 분석 목표 확실히 보인다.
----
📌 공동 피드백
1. 회사에 대한 분석이 먼저 들어가면 좋겠다.
2. 브라질의 전자 상거래의 특성을 분석한다거나, 수도가 어디고 어떤 카테고리가 어느 지역에서 경제 수준이 ~하기 때문에 잘 팔린다! 요런 거 들어가기 전에 고려하면 좋음
-> 데이터에 매몰되지 말고 대상에 대해 전체적으로 (2조의 문제 정의 접근 흐름 굳!)
3. 사용한 컬럼 이야기 시 orders 테이블의 ~한 컬럼입니다! 이건 주문 이력 확인하기 위해 사용했다.
4. 글자 많은 건 좋지 않지만, 장표 보고 이해할 수 있고 보면서 들을 수 있게 매치
+++ 실무를 하다보면?
SQL 잘 짜고 대시보드 잘 만드는 건 엔지니어의 역할!
이건 기본으로 탑재해야 하는 것들이다~
못하던 사람들도 실무하면 잘해진다.
그렇다면 역량의 차이는?
내가 속해있는 분야에 대해 도메인 지식이 얼마나 되냐?
PT/발표/커뮤니케이션 등이 굉장히 중요하다!
- 분석 전 과정에 녹여놓은 내 주장을 대상에게 전달할 수 있어야 한다🫠
1.2 SQL/Tableau 최종평가 공부
📌 SQL
✅ 매출액 분석
➡️ ABC (구성비누계 70 아래 A, 90 아래 B)
Step 1. 매출액이 많은 순으로 정리
Step 2. 총매출을 100%로 하여 고객별 백분비 산출
Step 3. 그 누적 구성비율을 상위의 고객부터 순서대로 누적해 간다.
Step 4. 그래프의 세로에 매출액 점유비의 누적치를, 가로축에 고객을 기입하고 고객별 누적구성비를 표시해 간다
Step 5. 세로축의 70%와 90%의 누적치 해당점에서 가로선을 긋고, 그래프의 선과의 교차점에서 수직선을 긋는다
➡️ Z차트 (매출, 누적 매출, 이동연계(10 preceding 줘야 함))
Step 1. 제품별 연-월에 따른 월별 매출
Step 2. 매출누계
나는 limit으로 했는데 where 기준월매출 != 0 도 쓸 수 있다!
✅ 시계열
➡️ 재구매율
- 월별 재구매율
Step 1. 고객 구매월 중복되지 않게 불러오기
Step 2. 다음 월과 매칭되도록 self join (a.date+1=b.date)
Step 3. 월별 구매자 수 집계하여 재구매율 계산
- 제품의 연도별 재구매율 (동일한 고객이 재구매)
Step 1. 고객별 연도별 제품 구매 기록을 중복 없이 불러온다!
Step 2. 제품에 대한 동일한 고객의 재구매율이기 때문에
self join 시 연도+1과 고객, 제품이 같은 경우를 조건으로!
Step 3. product_name 별 연도 별 구매자, 재구매자, 재구매율 구하기
➡️ 1997년 분기별 판매수량 TOP10 - 순위변화
1. 1997년의 분기, 판매수량 등 필요 컬럼 가져오기
2. 랭크 구하기 (연 분기별이기 때문에 partition 연, 분기)
3. LAG 사용해서 이전 분기와 연산/비교하기
✅ 고객분석
국가별 고객수, 구성비, 누적비, 누적합, 매출액, 건당평균주문액, 주문건수 + 상관관계
구매 이력이 없는 고객! 등
➡️ DECIL (고객 등급 나누고 그룹화해서 관리하는 기법)
Step 1. 고객의 총 매출액 기준 정렬
Step 2. 상위부터 10%씩 나누어 10개의 그룹 할당! 10등분 (ntile? 사용하면 된다고 하심)
Step 3. decil 별 매출합계 (1등급은 ~, 2등급은 ~)
Step 4. decil 별 구성비 (전체 매출 중 구성비)
Step 5. decil 별 구성비 누계 (구성비의 누계!)
➡️ RFM
Decil 분석의 단점을 보완한 분석 기법이 RFM 분석!
- 구매 가능성이 높은 고객을 식별하기 위한 데이터 분석 방법
- 마케팅에서 사용자 타겟팅을 위한 방법
- 구하는 방법
Step 1. recency 구하기 위한 datediff 구하기
Step 2. 고객 별로 각 지표 값 추출
Step 3. 지표에 스코어 부여
Step 4. 스코어 종합
➡️ 이탈고객 (비활동 고객 전환 비율!)
- 마지막 구매일 이후 90일 이상 경과한 고객의 비율
- 기준일 : order_date의 max값
Step 1. 고객별 order_date의 max값, 전체 order_date의 max값
Step 2. 경과일 계산
Step 3. 이탈고객 여부 (이탈일 90일 이상)
Step 4. 이탈률 계산
📌 Tableau
✅ live connection extract
1. incremental refresh vs full refresh
full refresh는 모든 데이터 행 업데이트, 속도 느림
incremental refresh는 새롭게 추가, 변경되는 행만 업데이트
2. tableau do when you connect to a data source?
-> creates a live connection to the data
✅ 정렬, 서식, 계산, 이미지 등 각종 잡다한 방법
1. 참조선 추가할 수 있는 타입
측정값, 계산된 필드 - 수치로 떨어지는 녀석들
2. 라벨로 그룹, 마크로 그룹 차이는?
라벨 - 해당 그룹으로 마크 생성
마크 - 하이라이팅
3. Sort 방법?
데이터 필드, 헤더, 축, 메뉴바 단축 버튼
4. add Total to a view
Analysis Tab
Analytics Pane
5. 마크에 텍스트 레이블을 추가하는 방법?
marks card에 drag-drop
toolbar에 show mark label
analysis in menu bar - show mark label
6. how worksheet visualisation as an image
click on the worksheet in menu bar
right click on worksheet and choosing copy and image
7. row, column bold 방법 (다른 것들에 영향 없이)
Menu bar - format - select Rows or Column
Right Click rows or columns - format - font
7-1. 축 폰트 진하게 만드는 방법?
축 우클릭 - 포맷 - 폰트 어둡게
8. 툴팁 수정하는 방법
marks card에서 tooltip 눌러서
워크시트 - 툴팁
워크시트 포맷팅 들어가면 됨
뷰 마크 우클릭 - sheet - default - tooltip
8-1. 툴팁의 글씨체 수정?
마크 카드의 툴팁
메뉴바 워크시트 - 툴팁
메뉴바 포맷 - - 폰트 - 툴팁
9. 대시보드를 다수의 이미지로 추출하는 방법
메뉴 바의 대시보드에서만 가능
10. 대시보드 사이즈 옵션
범위, 자동, 고정
11. 대시보드에서 시트 결합의 베네핏
필터 함께 적용
비교하며 분석
분석 속도
12.트렌드 라인 종류?
리니,로가,익포,폴리,파워
13. 애니메이션 특징
통합 워크시트에서 한 번에 킬 수 있다.
개별적으로 킬 수 있다.
디폴트로 꺼져 있다.
기본 0.3초
maps, ploygons, density marks in web borwser 작동 불가능
pie, text , axes, header, ofrecasts, tends, referencline
page history trails 도 불가능
✅ blending
1. 일반 계산된 필드, blending 후 계산된 필드의 차이?
혼합에 사용되는 필드는 무조건 집계
블렌딩해서 두 개의 데이터 사용할 때 계산된 필드로 각 데이터 끌어와서 사용해야 한다면?
반드시 각 데이터는 집계된 상태여야 한다.
집계 없이 가져온 데이터 값 그대로 넣으면 raw로 뿌려서 인식하지 못함.
2. 블렌드 후 null 값 이유?
대소문자
혼합 필드 데이터 유형이 일치하지 않는 경우
보조 데이터 원본에 주 데이터 원본 값이 포함되어 있지 않은 경우
✅ True False
1. Measure로 discrete 만들 수 있나? Yes
2. demansion으로 measure 만들 수 있나? Yes
다만, date or geomatric일 때만
3. Measure로 Sets 만들 수 있나? No (집합은 차원으로만 가능)
4. Sets로 Measure 만들 수 있나? No
5. relationship? lod 안 해친다
6. 메타 데이터 매니저는 단순히 보고 체크하는 용
데이터 해석기는 자동으로 수정하는 용 -> data interpreter
7. 조인은 선 결합 후 집계, 블렌딩은 선 집계 후 결합
8. 개별적 mark에 대한 similar character? -> clustering
9. join 시 중복을 피하는 방법? - relationship
10. relationship 사용하는 거! 모든 측정값 유지함
11. 뷰, 비주얼에 사용된 데이터를 추출하는 형식?
-> (window)mdb or (mac)csv
12. bins를 만들기 위해 계산된 필드를 사용 - yes
✅ +++
1. LOD
INCLUDE=포함한 차원에 대해 집계,
EXCLUDE 상위 차원 끌고오기
FIXED 차원의 고정
2. YOY, MOM은?
-YoY:전년도 대비 절대적 수치 증감률, YTD:ytodate:누계로 연초에 많이 사용
MoM : 전월 - 지금 월 비교하는 것
MTD : 지금이 2023/3/21이면? 3월 MTD의 경우 3월 1일 ~ 3월 21일까지 합계를 보여주거나 나열해서 보여주거나 총합
- 태블로는 뭐든 집계시켜 버리는 성질이 있다. 잘 못 추출한 데이터는 중복 문제를 야기시킬 수 있는데, 확인 방법은 count, countd 함께 사용해서 체크하는 것.
- 날짜 계산은 DATEDIFF ('기준단위',[시계열],[타겟시계열]) = 1
-> 기준단위가 month라면 타겟시계열
- 날짜 형식은 DATEPARSE()로 바꾸기
DATEDIFF ('YEARORMONTH',ORDERDATE, NOW) = [PARAMETER]
/ DATEDIFF ('YEARORMONTH',ORDERDATE, NOW) = [PARAMETER]+1- 1
MTD YTD는?
DATEDIFF ('YEARORMONTH',ORDERDATE, PARAMETER) = 0 AND DATEDIFF ('YEARORMONTH',ORDERDATE, PARAMETER) > 0
즉 파라미터로 설정한 ORDERDATE는 작거나 같아야 한다.
3. PRIMARY 함수
- LOOKUP() -> MOM 쓸 때 많이 사용! SQL의 LAG/LEAD와 같이 당기고 미는데 -+ 인자로 결정
- TOTAL() VLOD 측정값 TOTAL
- WINDOW_SUM,AVG - 문자 그대로 구간 나눠서 해당 구간의 평균, 합을 모는 거
- RANK! SQL에서 RANK 뽑으면 안 되는 이유? 차원이 바뀌면 RANK도 바뀌기 때문에 의미가 없다
4. tmp
- IF에는 항상 집계 씌워줘야 한다.
- ATTR은? 단 하나의 값을 가지면 걔 반환, 아니라면 *반환! 즉, 이질성테스트- 라이브와 추출의 차이?
- demansion을 measure로 변경하는 건 가능하다. 다만, date or geomatric일 때만
- VLOD의 마크를 변경할 수 있는 건 오직 차원!
- measure의 드래그드롭/더블클릭차이는? 2개째 더블클릭부터 measure name이 필터로 들어간다!! 드래그 드롭은 타겟을 사용자가 설정
1.3 Tableau Desktop Specialist

배운 점 요약 및 시행착오/어려운 점
1. SQL 미니 프로젝트
이번 미니 프로젝트에서는 SQL 활용한 분석 프로세스를 전반적으로 학습했으며, 그 과정에서 이전에 배웠던 심화 쿼리들을 복습할 수 있었다. 최종 평가 및 해커톤 전에 분석 프로세스, 기술적인 부분 두 가지를 모두 잡고 갈 수 있었던 시간이라 큰 의미가 있었고
SQL 쿼리 짜는 게 점점 익숙해지면서 더더욱 분석에 재미가 붙었다😋 특히 RFM, ABC, Z 차트, 재구매율, 이탈률 등 분석시에 주로 사용하는 다양한 방법론을 SQL로 구현해 볼 수 있었는데 내 손으로 짠 쿼리를 통해 그럴듯한 인사이트가 바로바로 뽑혀 나올 때마다 굉장히 즐거웠다.
아직 SQL로 구현해보지 못한 다양한 분석 기법들이 존재하고, 분석 프로세스 중 목적 정의 부분을 창의력 있게 풀어가지 못한다 느꼈기에, 다양한 분야의 데이터에 대해 어울리는 분석 이론을 적용하여 분석 프로세스를 익히는 학습이 필요하다 생각된다!!!💪🏻
미니 프로젝트 피드백 시간에서 분석 시 보완해야 할 점들에 대해 배울 수 있었다. 피드백 중 핵심이라 생각되는 부분은 데이터만 보고 분석을 진행하면 그만큼 사고가 편협해질 수 있기에 먼저 해당 데이터 관련 기업, 도메인, 시장에 대한 조사를 앞단에 수행해야 한다는 점이었다. 안 그래도 이번 분석을 진행하며 창의적인 목적 정의/계획 수립 방안에 대한 고민이 존재했는데 적절한 피드백을 받을 수 있어 행복했다
2. SQL/Tableau 최종평가 공부
최종 평가 대비해서 지금까지 배웠던 SQL과 Tableau를 총 복습하는 시간을 가졌다. SQL은 각종 함수에 대한 개념을 외우고 분석 방법론을 쿼리로 능숙하게 작성할 수 있도록 복습하였고, Tableau는 작성해 왔던 TIL과 기존에 자격증 공부하던 자료들을 바탕으로 준비했다.
SQL은 어렵고 복잡한 쿼리를 많이 배웠기 때문에 복습에 시간이 오래 걸릴 것이라 생각했는데, 막상 하다 보니 그렇지도 않았다. 복잡한 쿼리를 CTE로 분리해서 각 단계 별로 차근차근 학습했던 내용들이 어느 정도 내 것이 되어 있었던 거 같다. 그래서 요번 복습 시간은 교육 시작 당시에 비해 실력이 좀 늘었구나~ 라는 걸 느낀 순간이 되었다. STARTERS 정말 최고👍🏻
3. Tableau Desktop Specialist
재발급 신청해 놓은 여권이 월요일에 발급되었고, 주말에 시험 일정을 잡게 되었다. 금주는 최종 평가가 예정되어 있었던 만큼 자격증 시험에 응시하기 부담스러운 주였지만, 최종평가는 자격증 시험과 마찬가지로 Tableau의 개념/이론적인 부분 위주의 문제로 구성되어 있다고 하여 함께 준비하자는 생각으로 시험에 응시하게 되었다. 사실 교육 끝나기 전에 꼭 취득하고 끝내고 싶었던 이유가 더 크다.
여차저차 테스트를 보게 되었고, 다양한 기출을 풀며 자신감을 두둑이 챙긴 상태였기 때문에 긴장이 되지 않았다. 그런데.. 막상 시험 시작하고 문제들을 쭉 보는데 긴장감이 몰려오고 큰일 났다는 생각이 들기 시작했다. 아예 처음 보는 개념들이 존재했으며 기출에서 흔히 중요하다 강조하던 개념들은 나올 때 말장난으로 꼬여 나왔기 때문이었다. 이러한 부분들 때문에 체감상 유데미 테스트보다 두 배는 어려웠던 거 같다😵 사실 시작하기 전에 체크인이 살짝 밀려 5분가량 늦게 시작했는데.. 당시에 그려려니 하고 넘겼지만 10분도 안 남은 시점에 헷갈리는 문제 10개를 재검토하며 소거법으로 때려 맞추고 있을 때 좀 억울한 마음이 들었다. 그래도 높은 점수는 아니지만 결국 PASS 했기에 다행이었다.
최종적으로 이번에 자격증 공부와 시험 응시 하며 몰랐던 개념/이론/기능들을 많이 가져갈 수 있게 되었고, 알고 있던 것들에 대해서도 디테일한 수준으로 이해할 수 있게 되어 굉장히 뜻깊은 시간이었다고 생각한다.
2. 앞으로 적용해야겠다고 느낀 점이 있다면 무엇이고, 어떻게 해보면 좋을까요?
2.1 데이터 분석 프로세스
다음 분석을 하며 빨리 적용해보고 싶다고 느낀 것은 데이터만 보고 분석을 진행하면 그만큼 사고가 편협해질 수 있기에 해당 데이터 관련 기업, 도메인, 시장에 대한 조사를 함께 수행하며 진행하는 게 좋다는 점이었다. 안 그래도 이번 분석을 진행하며 창의적인 목적 정의/계획 수립 방안에 대한 고민이 존재했는데, 요게 고민에 대한 어느 정도 해답이 되어주지 않을까 싶다! 때문에 최종 해커톤을 진행하며 여건이 나온다면, 혹은 추후에 다른 프로젝트를 진행하게 된다면 꼭 적용해보고자 한다.
3. 현재까지의 학습 평가 및 다음 학습을 위한 다짐/목표를 공유해 주세요.
3.1 학습 평가
📌 SQL 더 다양하고 복잡한 분석 방법론 쿼리로 녹여내는 학습 필요
📌 분석 시에 편협한 목적 정의/계획 수립 개선 필요
3.2 다짐 및 목표
🔥 SQL 재밌다! 해커톤 끝나면 다양한 분석 방법론을 쿼리로 구현하는 연습 수행해보자 + 태블로 시각화🐯
🔥 분석 시에 데이터만 보지 말고 해당 데이터 관련 기업, 도메인, 시장에 대한 조사를 함께 수행💸
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > 학습일지 😛' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터 분석/시각화(태블로) 12주차 학습 일지 (0) | 2023.05.01 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 10주차 학습 일지 (0) | 2023.04.16 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 9주차 학습 일지 (1) | 2023.04.09 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 8주차 학습 일지 (0) | 2023.04.02 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 7주차 학습 일지 (0) | 2023.03.26 |



