
ilovechoonsik
[STARTERS 4기 TIL] SQL 집계, VIEW, 통계, 순위 (230217) 본문

📖 오늘 내가 배운 것
1. 집계, VIEW
1.1 집계함수
-> GROUPING 하는 구문들과 연계하여 많이 사용

COUNT 같은 경우 * 넣으면 전체 행 COUNT
COLUMN 넣으면 해당 COLUMN COUNT (NULL 있으면 제외하고 COUNT)
SUM도 NULL 제외하고 계산!
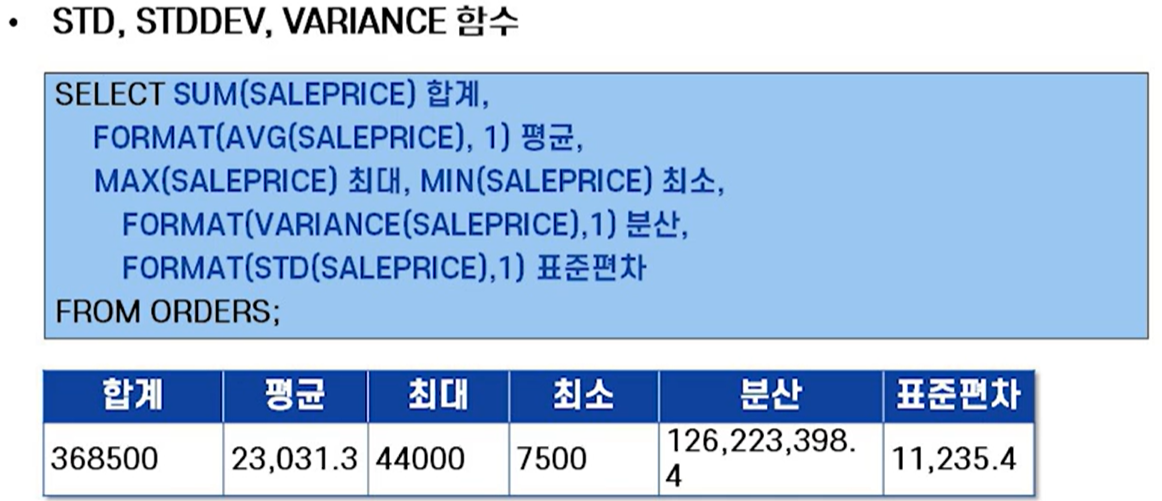
1.2 수치형 집계함수
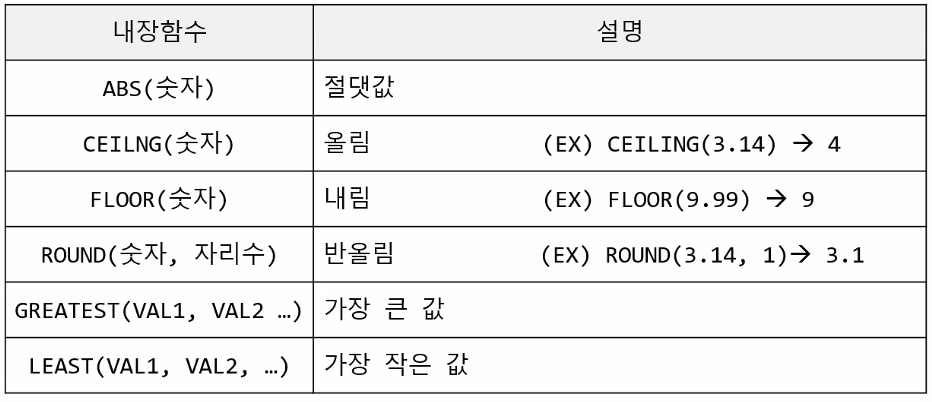
1.3 기간 집계함수
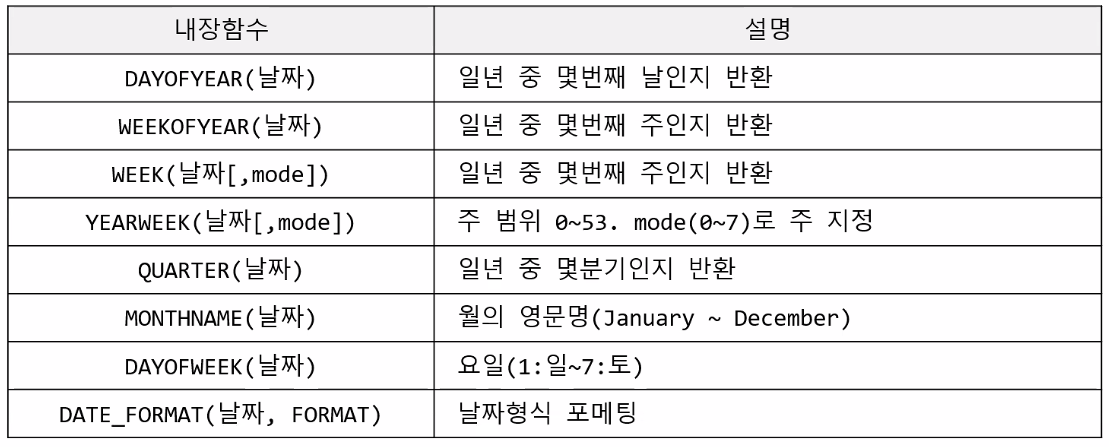
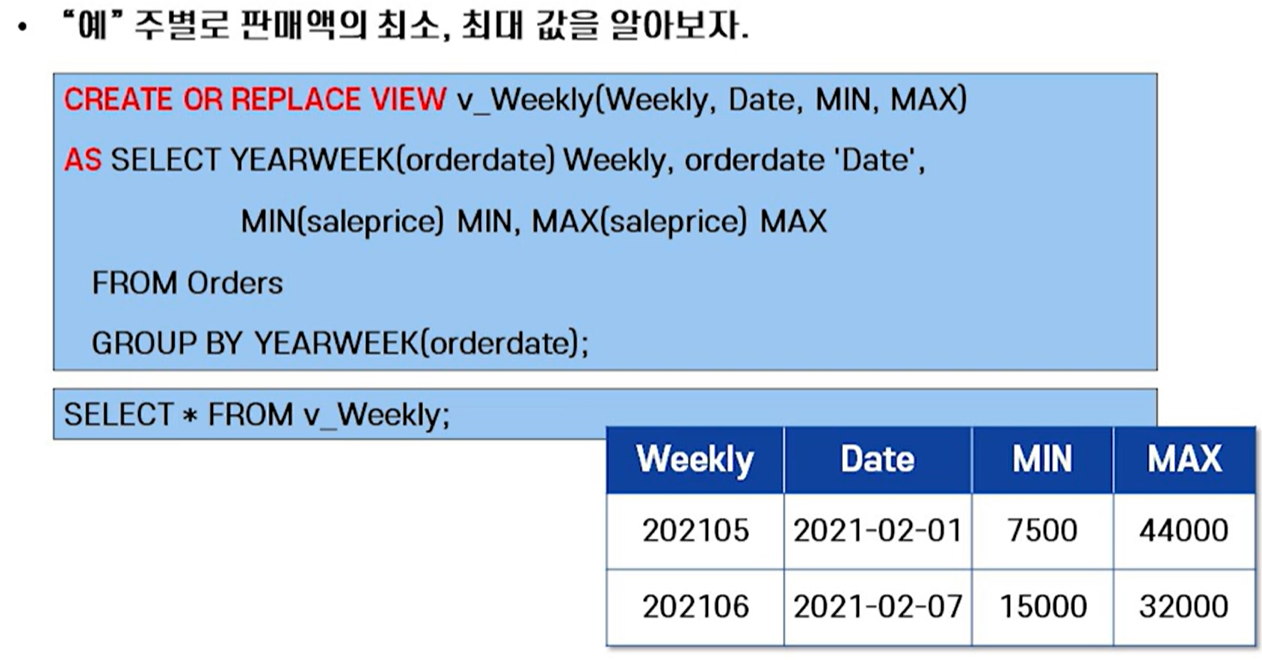
1.4 VIEW와 집계함수
- VIEW?

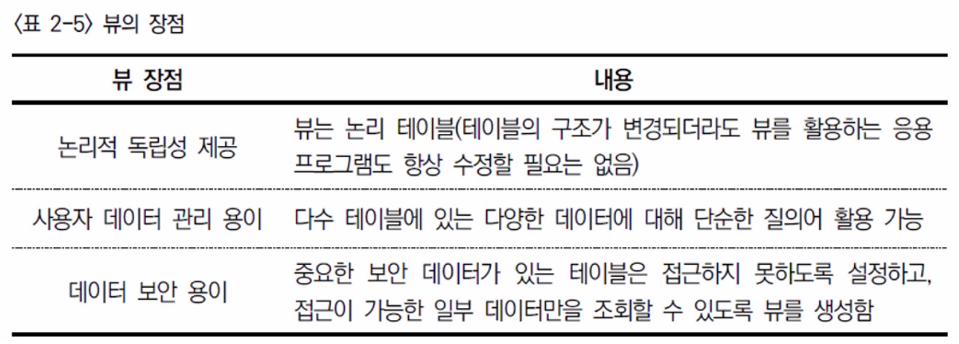
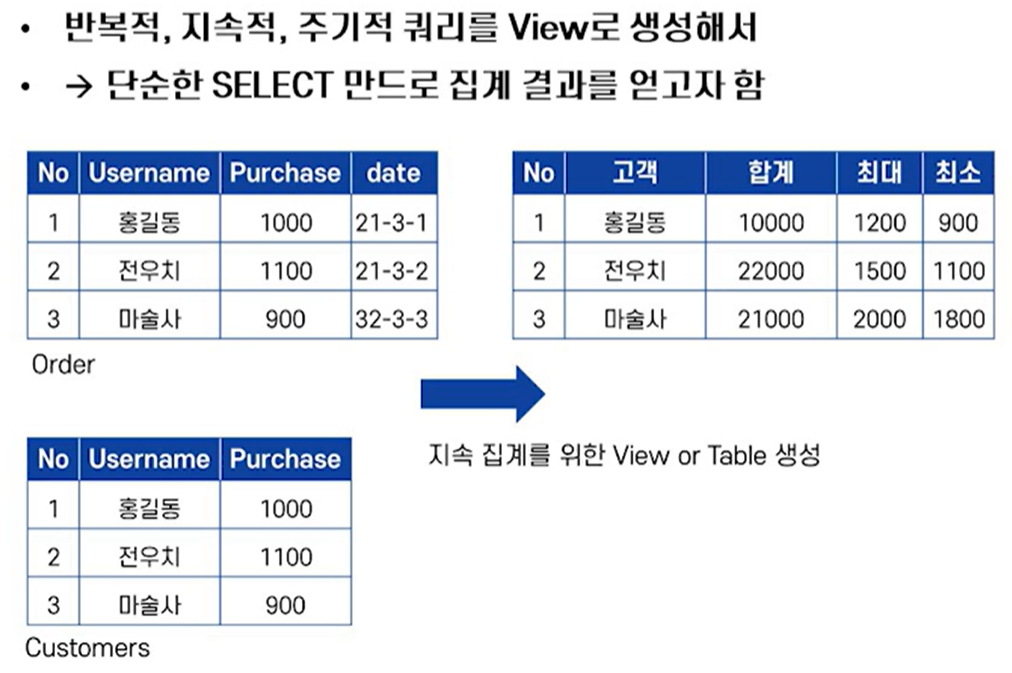

2. 통계 기법
2.1 기본 통계
- 기술통계
: 데이터를 대표값을 중심으로 해서 해당 데이터의 주기적, 반복적 내용들 또 데이터에 이상, 결측치 판단하는데 사용
- 대표값
: 데이터 계수 count
: 최대최소중간 max min median
: 합평균 sum average
: 순위 rank
- 대표값은 중심경향성을 통해 판단!
- 산술적인 지표를 통해 바라보게 된다 (평균, 중간, 최대 최소 등)

- 대표값 구하는 방법은?
산술평균 : 평균 총합 / 개수
기하평균 : 관측치의 제곱근 취해서 산술하는 평균값
중앙값 : 데이터 가운데 값
- 대표값 함수

- 데이터의 분포

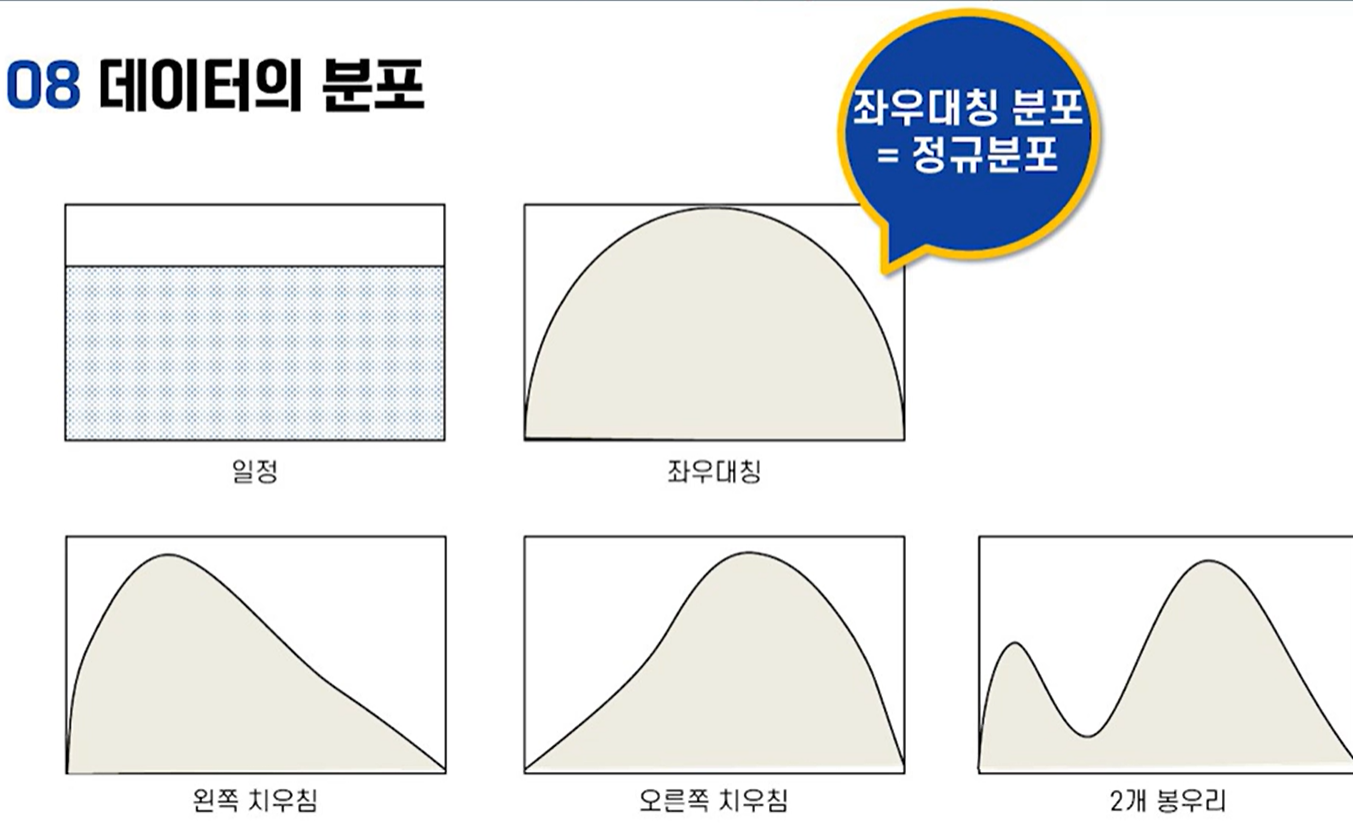
- 데이터의 분포 함수

# 4분위 수 같은 경우는 지원하는 함수 없음, 직접 계산해야 함
- 4분위 수 구하기 (단계 별로)
📌 가격 개수를 이용한 사분위수
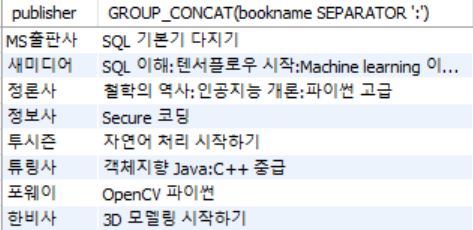
1단계 : group_concat(name [separator][order by]) : 컬럼 결과를 한 줄로 결합
SELECT publisher, GROUP_CONCAT(bookname SEPARATOR ':')
FROM book
GROUP BY publisher;
2단계: 모든 가격을 결합한다.
SELECT GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ',')
FROM Orders;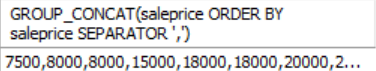
3단계: 전체 레코드 수를 25%~100% 까지 계산해 본다.
SELECT 25/100 * COUNT(saleprice) + 1 AS '25%',
50/100 * COUNT(saleprice) + 1 AS '50%',
70/100 * COUNT(saleprice) + 1 AS '75%',
MAX(saleprice) AS 'MAX'
FROM Orders;
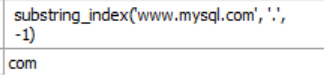
4단계: substring_index(str, delim, count)
- 문자열 str 을 delim 로 구분해서 배열로 만든 후 count 만큼만 보여준다.
- count 가 양수이면 왼쪽에서 count 수만큼 보여주고 음수이면 오른쪽에서 count 수 만큼 보여준다.
select substring_index('www.mysql.com', '.', 1); -- 'www'
select substring_index('www.mysql.com', '.', -1); -- 'com'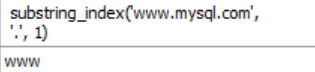
5단계: FINAL
- 합쳐지는 데이터가 많을 경우 꼭 SET GROUP_CONCAT_MAX_LEN = 10485760; 와 같은 설정이 필요함
- SET GROUP_CONCAT_MAX_LEN = 10485760;
SELECT MIN(saleprice) AS 'MIN',
SUBSTRING_INDEX(SUBSTRING_INDEX(
GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 25/100 * COUNT(*) + 1), ',', -1)
AS `25%`, # 전체 saleprice에서 25% 위치에 존재하는 값 가져오기
SUBSTRING_INDEX(SUBSTRING_INDEX(
GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 50/100 * COUNT(*) + 1), ',', -1)
AS `50%`,
AVG(saleprice) AS 'MEAN',
SUBSTRING_INDEX(SUBSTRING_INDEX(
GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 75/100 * COUNT(*) + 1), ',', -1)
AS `75%`,
MAX(saleprice) AS 'MAX'
FROM Orders;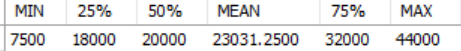
3. 순위, 소계, 피벗 등
3.1 순위 지원 함수

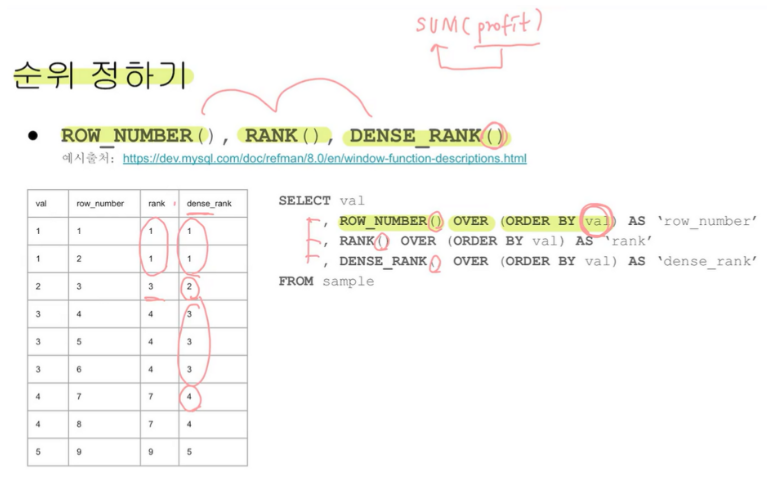
- PARTITION BY


3.2 소계
- ROLLUP 그룹별 집계
ROLLUP을 활용하면 GROUP BY에서 선택한 기준에 따라 소계가 구해진다.
모든 product의 profit 합계와 모든 country의 profit 합계(총합)가 구해진다.
소계, 즉 중간 집계를 구하기 위해 사용!
SELECT country, product, sum(profit)
FROM sales
GROUP BY country, product WITH ROLLUP;ROLLUP 적용 전 (왼쪽) VS ROLLUP을 적용한 모습(오른쪽)

ROLLUP은 집계한 기준값을 NULL값으로 대체한다. 이때, COALESCE을 활용하면 NULL 대신 원하는 텍스트를 넣을 수 있다.
SELECT COALESCE(country,"ALL countries") as country,
COALESCE(product,"ALL products") as product,
sum(profit)
FROM sales
GROUP BY country, product WITH ROLLUP;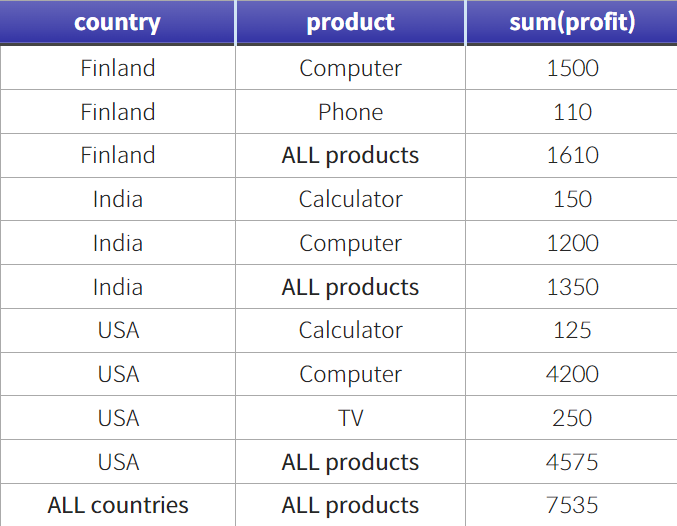
SELECT COALESCE(address, '총합') AS 지역
, COALESCE(bookname, CONCAT(SUBSTRING_INDEX(address,' ',-1), ' 합계')) AS 책이름
, COUNT(*) cnt
FROM Customer C, Book B, Orders O
WHERE O.bookid = B.bookid
AND C.custid = O.custid
GROUP BY address, bookname WITH ROLLUP;
ROLLUP 적용 전 (왼쪽) VS ROLLUP을 적용한 모습(오른쪽)
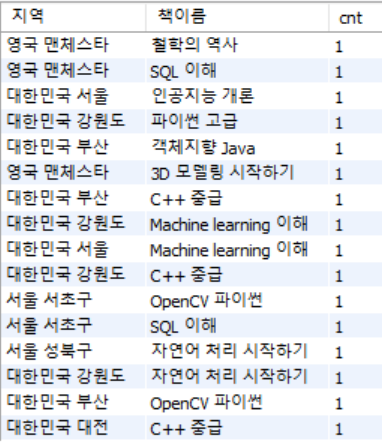
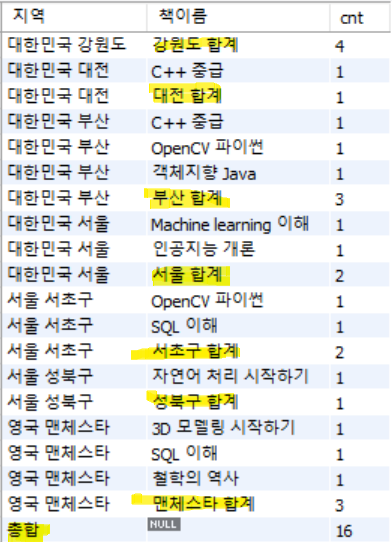
# GROUP BY 1,2 지정 불가능
# NULL값 처리는 HAVING IS NOT NULL로 가능
# mysql 8.0부터는 Oracle처럼 GROUPING 함수를 사용할 수 있다. 결과는 IFNULL을 적용한 쿼리와 같다.
GROUPING(컬럼) 값은 집계가 위치해야 할 ROW(NULL이 표시되는 지점)에서 1 아니면 0을 리턴한다.
IF문을 통해 그 지점을 다른 문자로 대체할 수 있다.
SELECT IF(GROUPING(country),'ALL countries',country),
IF(GROUPING(product),'ALL products',country), SUM(profit)
FROM sales GROUP BY country, product WITH ROLLUP;
4. 멘토링
4.1 다중 테이블 조회
2. IFNULL, RANK, LEFT JOIN
#1. 고객별 총 주문횟수, 총구매액, 평균개매액, 최소/최대구매액 구하기
#2. 구매하지 않은 고객 포함
#3. 구매하지 않은 고객은 집계 결과 0으로 표현
#4. 총 구매액 순으로 순위 매기기
SELECT username AS 고객
, IFNULL(COUNT(o.orderid), 0) AS 주문횟수
, IFNULL(SUM(o.saleprice), 0) AS 총구매액
, IFNULL(ROUND(AVG(o.saleprice),1), 0) AS 평균구매액
, IFNULL(MIN(o.saleprice), 0) AS 최소구매액
, IFNULL(MAX(o.saleprice), 0) AS 최대구매액
, RANK() OVER (ORDER BY SUM(o.saleprice) DESC) 순위
FROM customer c
LEFT JOIN orders o ON c.custid = o.custid
GROUP BY username
ORDER BY 총구매액 DESC
3. PARTITION BY
##################################################
# 고객별 saleprice 랭킹
##################################################
select c.username
, b.bookname
, o.saleprice
, RANK() OVER(PARTITION BY username ORDER BY o.saleprice DESC) 순위
from orders o, customer c, book b
where o.custid=c.custid
and o.bookid=b.bookid;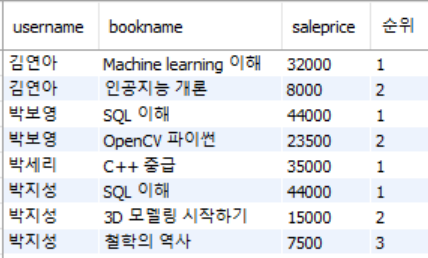
##################################################
# 지역-도서별 판매 수량
# 지역별 판매수량 소계
##################################################
select substring_index(address,' ',1) as 지역,
b.bookname as 도서명,
count(*) 총판매수량 ,
sum(o.saleprice) 총판매금액
from customer c, orders o, book b
where c.custid = o.custid
and o.bookid = b.bookid
group by 1,2 WITH ROLLUP;
# 지역별 총판매금액 소계를 넣고 싶다 -> GROUP BY WITH ROLLUP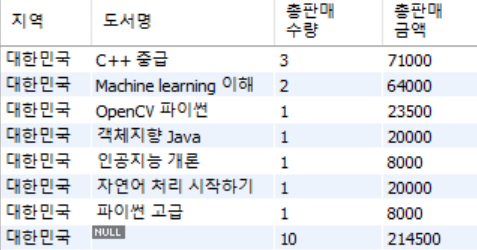
참고 자료
[1] ROLLUP
https://yahwang.github.io/posts/31
[2] NULL 처리
https://velog.io/@gillog/DB-MySQL-NULL-%EC%B2%98%EB%A6%ACIFNULL-CASE-COALESCE
[3] RANK (데이터리안 - WINDOW FUNCTION)
💪🏻 좋았던 점, 앞으로 개선해야 할 점 (추가로 배워야 할 점)
📌 저번 시간과 마찬가지로 이미 학습했던 내용이었기에 복습하는 느낌으로 쭉 강의를 들었다!
근데 SQL에서의 통계 기법은 처음 학습하는 내용이었고, 생각보다 많이 헷갈렸다!!
복습을 통해 개념 튼튼히 하고 갈 수 있도록 해야겠다💪🏻💪🏻
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] R #2 (230221) (0) | 2023.02.21 |
|---|---|
| [STARTERS 4기 TIL] R (230220) (1) | 2023.02.20 |
| [STARTERS 4기 TIL] SQL 다양한 문법 및 활용 (230216) (0) | 2023.02.18 |
| [STARTERS 4기 TIL] 데이터 베이스 배경, SQL 활용 조작 (230215) (0) | 2023.02.16 |
| [STARTERS 4기 TIL] 공공 데이터 분석 #2 (230214) (0) | 2023.02.14 |



