
ilovechoonsik
[STARTERS 4기 TIL] R (230220) 본문

📖 오늘 내가 배운 것
1. R이란?
전산 통계학을 위한 프로그래밍 언어
1.1 R 활용 가능 분야 (데이터 마이닝 - 데이터 채굴해서 정보를 얻는 학습)
- 텍스트 마이닝
- 소셜 네트워크 분석
- 지도 시각화
- 주식 분석
- 이미지 분석
- 사운드 분석 SST (Speech to Text), 잡음 제거
- 웹 애플리케이션 개발 -> R 언어만을 사용하여 웹에서 데이터 분석 시각화 가능
1.2 데이터 처리과정

(1) 문제 정의 단계
문제 상황 : 대형마트 특가 상품과 함께 판매할 아이템 선정
데이터 마이닝? 특가 상품과 함께 결재 되는 아이템 로그를 수집/분석 -> 유의미한 정보
분석방향 기획 - 데이터 관리팀에 데이터 요청 -> 데이터 전처리 SI 요청 or 자체 인력 사용 -> 분석 -> 보고서 작성
방법론 검토 - 후보 아이템 히스토그램 시각화, 피어슨 상관계수 기반 분석
(2) 데이터 수집 단계
수동 수집 : 직접 데이터 수집 (설문조사, 관찰), 데이터셋 구매 -> 오래 걸리고 비효율적
자동 수집 : 프로그래밍을 통한 자동화 -> 크롤링, 센서기반 (POS기 LOG)
데이터 파악 : 데이터 규모, 데이터 속성 값 -> 이름,전화번호,나이,특가 제품 구매 유무, 구매한 다른 제
(3) 데이터 전처리 단계
결측치 처리 : 값이 없는 경우 처
이상치 처리 : 잘못된 값 처리
속성 선별 : 분석에 필요한 속성만 선별
(4) 데이터 분석 단계
통계분석 : 통계학에 기반한 분석법 - 상관계수, 평균,분산,표준편차 등
시각화 : 주제가 자주 팔리는 제품을 찾는 것이기 때문에 특가 상품을 구매하였을 때, 함께 구매하는 아이템 순
(5) 결과 정리 단계
분석 결과 해석 : 통계, 시각화 자료를 기반으로 가설 성립 여부 예측 -> 우유가 가장 많이 팔렸다면 특가 상품과 함께 파는 게 좋겠다!
보고서 정리 : 데이터 처리 과정 요약 및 분석 결과 기반한 주장 ->
1.3 데이터 처리과정에서의 R 역할
문제 정의를 제외한 모든 과정에서 사용 가능

2. R 및 RStudio 기본 사용방법





2.1 Console 창 사용
- 기본적인 계산 기능 : 사칙연산, 제곱
- 문자열 출력 기능 : Print('~~')
- 데이터 셋 로드 : 내장된 데이터셋 로딩
head : 상위 6개 출력
tail : 하위 6개 데이터 출
콘솔창에서 이전에 작성했던 코드를 화살표를 통해 확인할 수 있지만
스크립트 창에 쳐놓으면 재활용이 훨씬 쉽다! 따라서 어지간한 모든 코드는 스크립트에서!
- Script 저장/불러오기
File - Save (ctrl+s)
File - Open (ctrl+o)
2.2 Working Directory 및 프로젝트 생성
- source 함수 : 어떤 스크립트 안에 코드들을 다른 스크립트에서 사용할 수 있게 해주는 녀석!
절대 경로 사용 : source("해당파일경로/파일이.R")
상대 경로 사용 : source("파일이름.R")
-> 서로 다른 폴더에 같은 이름을 가진 파일이 있다면?
그 기준이 되는 폴더가 Working Directory
- Working Diretory란?
- 작업을 위한 폴더
- 데이터셋, 파일 등 불러오기/저장 작업 수행하는 기본 폴더
- 프로그래밍에 필요한 파일 관리 용
- 현재 Working direcotry 경로 확인 방법
- getwd()
- working directory 내부 파일 확인 방법
- dir()
- 커맨드를 사용한 수정
- setwd()
- 순서
1. 임의의 새 폴더 생성 (기존 폴더도 가능)
2. setwd 커맨드 사용하여 working directory 지정! : R은 경로 지정 시 \ 2개 입력해야 인식 setwd("C:\\R\\workingDirectory")
- RStudio 재시작시 유지 x
- default Working Diretory 수정
순서
1. Tools -> Global Options
2. Default working directory 수정
- RStudio 재시작 시 유지 안됨
2.3 프로젝트 생성
R에는 프로젝트 단위로 작업을 관리할 수 있는 기능이 있다!
우측 상단 프로젝트 버튼 -> New Project
- 장점
1. working directory가 생성한 프로젝트 폴더로 자동 설정 되기 때문에 관리 필요 x
2. 다른 PC에서도 프로젝트를 불러올 수 있기 때문에 유용
우측 상단 Open Project -> 프로젝트 폴더 에서 파일 Open
2.4 유용한 환경설정
R은 두 가지 범위의 환경 설정을 갖는다
- Global 환경 설정
-> RStudio 환경 내에서 실행되는 모든 프로젝트에 적용
- Project 환경 설정
-> 프로젝트에만 설정 사항 반영
- 자동 줄바꿈 기능
Tools -> Global Options -> Code -> 'Soft-wrap R source'
- Line 하이라이트 기능
현재 선택되어 있는 줄 알기
Tools -> Global Options -> Display -> Highlight selected line
- 폰트 및 배경 설정
Tools -> Global Options -> Appearance
- 인코딩 방식 설정 (Project Options)
Tools -> Project Options -> Code Editing -> Choose Encoding (UTF-8)
- 유용한 단축키
Ctrl + S : 파일 저장
Ctrl + O : 파일 불러오기
Ctrl + Shift + N : 새로운 스크립트 창 띄우기
Ctrl + Shift + C : 주석
Ctrl + 1~9 : 화면 이동 1-script 6-plot 5-files
Ctrl + Shit + Enter : 소스코드 실행
Shift + Alt + K : 모든 단축키 문서 실행
3. R의 기본 데이터 타입
3.1 배경
- Object (객체)

: R이 다루는 가장 기초적인 구조
- 데이터 값은 객체에 담김
- Class
: 객체의 타입
Class 확인 : class()

- R은 데이터 처리할 때 Class에 따라 데이터를 다르게 처리
3.2 데이터 타입 종류
(1) Numeric

: 수치형 타입
- 숫자를 나타내는 데이터 타입
- 실수 형 타입 (0도 실수이므로 Numeric)
(2) Integer
: 정수형 타입
- 정수 값 만을 나타내는 데이터 타입
- 메모리 관리에 효율적 (실수 데이터 하나 저장하기 위해 정수 데이터 2개의 공간이 필요)
- 최근에는 굳이 int 사용할 만큼 메모리가 부족하지 않지만 일단 알아놓기
ex) 1, 0, 10, 20, -15
- 객체 타입을 Integer로 지정하려면 값 뒤에 'L' 기입
ex) 1.1L -> Numeric
(3) 논리형 타입
: 참, 거짓을 타나내는 데이터 타입
- TRUE, FALSE
- Class로 확인 시 logical로 리턴
- 모든 문자가 대문자여야 함
(4) 문자형 타입
: 문자 또는 문자열 나타내는 타입
- 따옴표, 쌍따옴표로 감싸는 형태로 표현
(5) 복소수형 타입 (Complex)
: 복소수 값을 나타내는 데이터 타입
실세계 데이터에서 찾아보기 힘듬
알아만 놓기
3.3 특별한 데이터 객체
(1) Inf
: 무한히 큰 값을 나타내는 데이터 객체
- 1/0 -> Inf 리턴
- 1/Inf = 0 리턴
(2) NA (Not Availalbe)
: 결측값 나타내는 데이터 객체
NaN (Not a Number)
: 수치값으로 표현할 수 없는 값을 나타내는 데이터 객체
- 0/0
- 결측값으로 처리됨.
-> NA, NaN 이나 데이터 처리하는 과정에서 동일한 관점으로 처리 된다고 볼 수 있음.
4. 데이터의 종류
4.1 자료구조 왜 알아야하나?
매우 다양한 종류의 데이터셋들이 존재 (CCTV 영상, 시험 성적, 날씨, 교통)
데이터셋 : 데이터들의 집합, 모음
자료구조 = 데이터 특정한 규칙으로 컴퓨터 상에 표현
데이터 양이 아주 많음 -> 빠른 정보 추출을 위해 효율적인 데이터 탐색, 관리 중요
4.2 R에서 생각하는 현실 데이터의 종류는
(1) 데이터 차원에 따라 구분!
1차원 구조 : 단일 주제 데이터들을 모아 놓은 구조
EX) 2021년 전세계 국가의 GDP, 하루간 기온, 특정지역 강우량
2차원 구조 : 복수 주제 데이터들을 모아 놓은 구조
EX) 연도별 전세계 국가의 GDP, 언어/수학/영어 모의고사 점수, 병원 건강검진 결과
%가장 활발히 사용되는 데이터 종류%
N차원 구조 : N-1차원 데이터들을 모아 놓은 구조
EX) 월별 언어/수학/영어 모의고사 점수 (3차원) + 스트레스지수 (4차)
연도별 환자 건강검진 결과 (3차원)
(2) 데이터 구성에 따라 구분
단일 : 한가지 타입의 데이터로만 구성된 데이터
EX) 학생 별 나이, 몸무게, 키 데이터
다중 : 여러가지 타입의 데이터로 구성된 데이터
EX) 학생 별 나이, 이름, 안경 착용 여부 데이터
(3) 데이터 값 연속성에 따라 구분
범주형 : 셀 수 있는, 이산적 데이터 - 산술 연산 불가
셀 수 있기 때문에 보통 논리값 또는 문자로 표현
수치값으로도 범주를 표현할 수 있지만 크기의 차이를 나타내지 않고 각각 범주를 표현하는 것이기 때문에 산술 연산 불가
수치형 : 수치로 표현 - 산술 연산 가능
데이터 값이 연속적, 수치형 값은 범주형으로 표현 가능


온도는 일반적으로 낮으면 춥다 더우면 덥다
온도는 연속적인 수치형 값이지만
우리가 범주로 잘라서 표현한다면 자연스럽게 변형이 될 수 있다.
그럼 반대로 범주형 -> 수치형은?
>> 오늘 추워? 오늘 1도 겠네? >> 불가능!
범주형 데이터는 수치형 데이터에서 표현할 수 있는 값의 정보에 대해 매우 한정적인 데이터 정보만을 표현할 수 있기 때문에 변환이 불가능하다.
수치 > 범주 O
범주 > 수치 X
5. R 자료 구조
- 백터, 매트릭스, 배열
- 리스트, 데이터 프레임
데이터의 양은 갈수록 늘고, 다양한 타입의 데이터들이 존재한다!
이러한 데이터들을 빠르게 처리하기 위해서는 효율적인 자료 구조가 필요하다.
이러한 맥락에서 모든 프로그래밍 언어는 자료구조를 각각의 특색에 맞게 구현해놓고 있다.
R은 데이터의 통계처리, 시각화 특성화 되어 있기 때문에 요기 특화
5.1 벡터(Vector)
: R의 가장 기본적인 자료구조
- 1차원 구조
- 데이터 타입이 동일한 값들의 모음
(1) 생성 방법
- c() : c함수 안에 값들을 넣으면 다 합쳐서 하나의 vector로 표현
-> vector("데이터 타입", length="벡터 크기")


이전에 설명했던 것과 같이 R에서 사용되는 가장 단순한 자료 구조! 1을 넣었을 때 Numeric 나왔었는데, 이게 사실 vector였다. 사진의 numeric, character, logical 뒤에 vector라는 의미가 숨겨져있다.

백터는 단일형 데이터기 때문에 모든 결과가 형변환 일어나서 하나의 단일형으로 표현된다.
1.7 -> 문자
True -> 1
True -> 문자
형변환? : 데이터 타입이 다른 타입으로 변경되는 것.
자동 형변환? : 컴퓨터에 의해 자동으로 형변환이 일어남

자동 형변환 우선 순위
Character > Numeric > Logical
위 벡터 자동 형변환은 벡터가 단일형 데이터이기 때문에 자동 형변환 우선 순위에 의해 변환된 것
5.2 행렬(Matrix)
- Vector의 집합
- 단일형, 2차원 구조
- 행(row), 열(col)로 구성
(1) 생성 방법
- matrix() 함수 사용
사용 방법 : matrix(nrow=행 크기, ncol=열 크기)

- Vector값 사용하여 matrix 생성 가능
사용 방법 : matrix(vector, nrow=행 크기, ncol=열 크기)

- byrow 옵션
데이터를 행부터 채움
기본값 : False

(2) 행렬의 데이터 타입은?

Matrix는 matrix라는 데이터 타입을 따로 가지고 있다.
matrix라는 데이터 타입은 dim이라는 추가적인 속성을 가지고 있다.
dim : 행, 열 크기를 가지고 있는 벡터값 -> c(행,열)
5.3 배열 (Array)
- dim 속성 크기가 2이상인 자료구조
(1) 생성방법
: array() 함수 사용 -> array(dim=(2,2,3))
- vector값 사용하여 array 생성 가능
- Matrix == dim 크기가 2인 array
matrix는 dim=2인 자료 구조, array는 dim>=2 인 자료구조이기 때문에
matrix를 포함하는 좀 더 큰 개념의 객체
그래서 matrix에 class를 씌우면 array도 함께 나온다!
5.4 리스트(List)
: 다중형 데이터를 다루는 1차원 크기의 자료 구조 - 서로 다른 데이터 타입이 존재하는 값들의 모음

- 현실 세계에 아주 흔하게 존재하는 데이터 구조
-> 신상명세 데이터 - 이름, 나이
생성 방법 : list() 함수 사용 -> 리스트 안에는 모든 자료구조 포함될 수 있다.

5.5 데이터 프레임
List의 집합!
- 다중형, 2차원 구조
- 행(row), 열(col)로 구성
- matrix에서 한 행은 vector 였다면 데이터 프레임에서 행은 list 취급
- 각 열은 vector 취급
: 리스트는 다중형 데이터이기 때문에 리스트를 행으로 쌓아놨을 때, 한 열은 모두 같은 데이터 타입이 들어갈 수밖에 없다
- 열 별로 다른 데이터 타입 저장 가능
- 데이터셋 파일 로딩 시, 주로 데이터 프레임 구조 사용
-> Table, excel, csv 형식
(1) 생성 방법 : data.frame()
- 변수 사용 가능!


5.6 깜짝 퀴즈~~~




답
4, 1, 2, 1, 3, 1, 3, 2, 3, 4, 2/5
6. 실습 - 은행 대출상품 마케팅


Age : Numeric, 나이는 소수점 표현 잘 안하기 때문에 Integer로 봐도 될 듯
Job : Character, string!
Marital : Character, 사별도 존재하기 때문에 단순히 True/False 아님
Balance : Numeric, 은행 잔고
Campaign : Character
Y : logical

Age : 수치형/범주형, 어찌보면 범주형이라고 생각할 수도 있다. (0~150 까지의 범주)
Job : 범주형
Marital : 범주형
Balance : 수치형
Campaign : 범주형
Y : 범주형
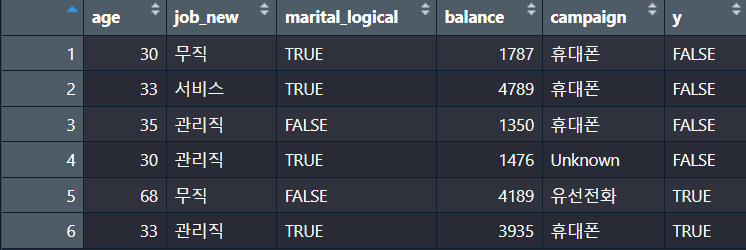
6.1 데이터 프레임 만들어보기
#12 차시 R 데이터 자료구조 실습 코드
age <- c(30, 33, 35, 30, 68, 33) # 나이 벡터 생성
job <- c("무직", "서비스", "관리직", "관리직", "은퇴", "관리직") # 직업 벡터 생성
marital <- c("결혼", "결혼", "미혼", "결혼", "사별", "결혼") # 결혼 유무 벡터 생성
balance <- c(1787, 4789, 1350, 1476, 4189, 3935) # 은행 잔고 벡터 생성
campaign <- c("휴대폰", "휴대폰", "휴대폰", "Unknown", "유선전화", "휴대폰") # 상담 매체 벡터 생성
y <- c(F, F, F, F, T, T) # 상담 결과 벡터 생성
result <- data.frame(age, job, marital, balance, campaign, y) #데이터 프레임 생성
print(result) #출력
7. 변수 이해하기
7.1 변수란?
: 변할 수 있는 값
- 프로그램 내에서 어떤 값을 저장해 놓을 수 있는 보관함
- 데이터를 저장하기 위해 이름을 할당 받은 메모리 공간
- R에서의 변수?
: 객체(Object)를 저장해 놓는 보관함
(1) 변수 사용 방법 : a <- 10
- 'a'라는 변수를 선언
- '<-' 연산자 사용하여 '10'이라는 수치형 값 할당
(2) 선언과 할당
선언 : 변수 명을 등록하여 프로그램에 변수의 존재를 알리는 과정
할당 : 변수에 값을 저장하는 과정
(3) 초기화란?
: 최초로 값을 저장하는 행위 (a <- 10 = 변수 선언과 동시에 10으로 변수를 초기화)
(4) 변수 선언만 하기
: NULL 값 사용 (a <- NULL)
할당할 값이 미정인 상태에서 변수 선언만 하고 싶은 경우 사용
# NA vs NULL
어떠한 값이 없다는 점에서 동일
NULL : 실제로 값을 넣고 싶지 않을 때, 값이 없다라는 의미로 사용하는 객체
NA : 실제로 값이 존재해야 하는 공간에 값이 없는 경우를 나타낸다
(5) 변수 할당


(6) 선언한 변수 확인하기
- Print 함수 또는 Console 창에서 변수 명 입력하여 확인
- RStudio - Evironment (선언한 변수 및 할당된 값 간편하게 확인 가능)
(7) 변수 작명 규칙


8. 함수 이해하기
8.1 함수의 개념
: 입력 변수, 값을 넣고 실행을 하였을 때, 결과 값이 반환되는 장치
입력 값을 넣고 실행 -> 결과 값 리턴 하는 장치
(1) 기본적인 함수형 y=f(x)
x : 입력 변수
f : 함수
f(x) : 함수에 입력 값을 적용
y : 결과 변수
함수는 실행 내용에 대한 정의가 필요
어떠한 입력 값이 오던지 정의된 내용대로 실행하여 결과 값 리턴
(2) R에서의 함수
모든 객체 입출력 값으로 사용 가능

# 요기서 print는 화면에 출력한다는 개념! return과는 다름
8.2 매개변수

함수의 입력 변수를 부르는 명칭
- 함수의 정의에 알맞은 매개변수 입력 필요
- 정의에 맞지않는 매개변수 입력 시, 오작동 또는 에러 발생

(1) 함수의 정확한 형태
document 찾아보기

(2) 매개 변수명 생략
매개변수 값을 정의 순서대로 입력 하는 경우, 매개변수 명 생략 가능

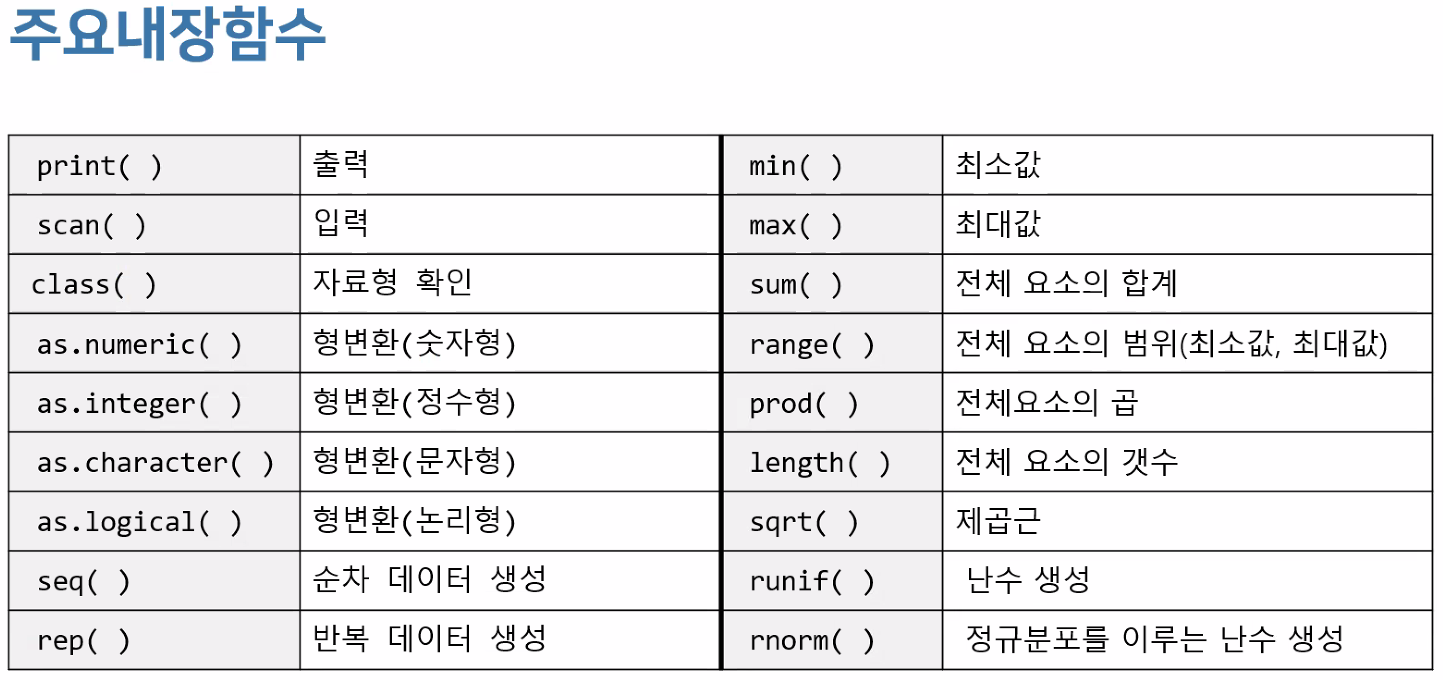
(3) 유용한 내장 함수
: 프로그램에서 기본적으로 정의되어 제공하는 함수
print, class, sqrt, mean
(좌) 강제 형변환 함수 / (우) 데이터 생성 함수


9. 패키지 이해하기
9.1 패키지란?
: 유사한 기능을 하는 함수들을 한데 묶어 관리하는 꾸러미 -> 함수들의 모음

(1) 패키지 탐색 방법
: CRAN 사용, 인터넷 키워드 검색
(2) 패키지 설치 방법
a. 함수를 이용하여 설치
install.packages('함수 이름')
b. R 스튜디오 인터페이스로 설치
RStudio - Packages -> 검색 -> Install 버
# 변수 함수 패키지 퀴즈




답
1,2,2,1,2,2,3,4,1,2,1
10. 실습
#12 차시 R 데이터 자료구조 실습 코드
age <- c(30, 33, 35, 30, 68, 33) # 나이 벡터 생성
job <- c("무직", "서비스", "관리직", "관리직", "은퇴", "관리직") # 직업 벡터 생성
marital <- c("결혼", "결혼", "미혼", "결혼", "사별", "결혼") # 결혼 유무 벡터 생성
balance <- c(1787, 4789, 1350, 1476, 4189, 3935) # 은행 잔고 벡터 생성
campaign <- c("휴대폰", "휴대폰", "휴대폰", "Unknown", "유선전화", "휴대폰") # 상담 매체 벡터 생성
y <- c(F, F, F, F, T, T) # 상담 결과 벡터 생성
result <- data.frame(age, job, marital, balance, campaign, y) #데이터 프레임 생성
print(result) #출력
#16 차시 R 변수, 함수, 패키지 실습 코드
age_mean <- mean(age)
balance_mean <- mean(balance)
print(age_mean)
print(balance_mean)
yToNum <- as.numeric(y) # 상담 결과 벡터를 numeric 형식으로 형 변환
yCount <- sum(yToNum) # sum: 벡터 값들의 총합 리턴
print(yCount)
#실습 문제
#string 패키지 설치/로딩
install.packages("stringr")
library(stringr)
job_new <- str_replace(job, "은퇴", "무직") # "은퇴" 값을 "무직"으로 변경
print(job_new)
marital_new <- str_replace(marital, "결혼", "T") # "결혼" 값을 "T"로 변경
print(marital_new)
marital_logical <- as.logical(marital_new) # marital_new 벡터 logical로 강제 형변환
print(marital_logical) # character -> logical 로의 형변환 시, "T", "F"외의 값은 NA로 변환 됨
marital_logical[is.na(marital_logical)] = F # NA값을 F로 변환
print(marital_logical)
result_new <- data.frame(age, job_new, marital_logical, balance, campaign, y)
print(result_new) #출력
11. 멘토링
Q1. 벡터 생성 시 자료형 혼합되면?
vector같은 경우는 하나의 동일 자료형으로 이뤄지는 자료형
c(1,'a',True)
--> "1" "a" "TRUE"
알아서 자료형 변경해 줌
우선 순위는 Character > numeric > logical
vector는 파이썬 numpy 배열과 비슷하다.
numpy는 e-learning 과정에 없었지만, 중요하기 때문에 따로 학습해야 함
Q2. 할달 연산자를 <- 가 아닌 = 로 사용해도 할당이 되는 이유?
초기에는 <- 였지만 바뀌었다~
두 가지 다 사용 가능!
근데 사람들이 암묵적으로 <- 사용
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=definitice&logNo=220967346991
12. R에서 객체(변수)에 값 설정/저장시, 꼭 <- 연산자를 써야 할까? 그냥 =를 쓰면 안될까?
대부분의 프로그래밍 언어에는 변수 선언 및 초기화시(쉽게 말해 변수에 값 저장시) = 연산자를 쓴다. C ...
blog.naver.com
Q3. class(TRUE)를 입력하면 결과로 "logical"이 나오는데,a라는 변수에 TRUE를 할당한 후 ( a <- TRUE )
b <- class(a)를 하면 class(b)가 "character"이 나오고
c <- print(a)를 하면 class(c)가 "logical"이 나옵니다.위 논리들의 차이가 무엇인지 궁금합니다.
a <- TRUE
class(a)
"logical"
b <- class(a)
class(b)
"character"
c <- print(a)
class(c)
TRUE
파이썬 VS R

간단히 통계 vs 머신러닝
둘 다 알면 좋다~
데이터 타입
파이썬에서는 float, int
r에서는 정수 실수 다 포함
메모리 관리 차원에서 int




벡터는 동일한 타입, 리스트는 다양한 타입

파이썬과 다르게 R에서는 슬라이싱 1부터 시작, 끝 인덱스 다 포함(=len)
R에서는 - 하게 되면 그 인덱스는 빼겠다는 뜻
변수

ls() : 변수 목록 출력
rm(변수) : 지정 변수 삭제
rm(list=ls()) : 전체 삭제
데이터를 다뤄야 하기 때문에 자료 구조를 잘 다루는 역량이 매우 중요하다고 하심
연습하기
# 1. 벡터 만들기
# 1부터 10까지의 숫자로 이루어진 백터 만들기
c(1,2,3,4,5,6,7,8,9,10)
c(1:10)
c(seq(1,10,1)) # seq는 range와 비슷
# 다음 숫자로 이루어진 벡터 만들기
# 1,2,3,50,51,52,53,54,55
c(1,2,3,50,51,52,53,54,55)
c(1:3,50:55) #c=concat 안에 들어오는 인자들 합쳐준다
# 1부터 100까지 3간격의 숫자로 이루어진 벡터 만들기
seq(1,100,3)
# 0.1부터 1까지 0.1 간격의 숫자로 이루어진 벡터 만들기
seq(0.1,1,0.1) # range와는 다루게 소수점 까지 다룰 수 있다!
# 다음 숫자로 이루어진 벡터 만들기
#1,1,1,1,1
rep(1,5)
# 다음 숫자로 이루어진 벡터 만들기 (1,2,3을 5번 반복)
rep(1:3,3)
rep(c(1,2,3),5)
# 2. 벡터 인덱싱/슬라이싱
absent <- c(3,2,0,4,1)
# 인덱싱
absent[1] # 1번 위치
absent[-3] # 3번 위치 뺴고 전부
absent[1:3] # 1~3번 위치
absent[-4:-5] # 1~3번 위치
# boolean indexing
# 벡터로 TRUE, FALSE, TRUE 자리수에 logical 값 넣어주면 TRUE인 값만 가져온다
# 1,3,5 번째 요소만 인덱싱
absent[c(TRUE,FALSE,TRUE,FALSE,TRUE)]
# 팬시 인덱싱
# iloc와 비슷! 인덱스 번호를 이용하여 인덱싱
# 판다스에서는 absent[[1,3,5]]
# 1,3,5번째 요소만 인덱싱
absent[c(1,3,5)]
# 벡터 absent 각 요소에 요일 이름 붙이기
names(absent) <- c('Mon','Tue','Wed','Thr','Fri')
absent
#'Mon'요소 가져오기
absent['Mon']
absent[c('Mon','Wed')]
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] R #3 (230222) (0) | 2023.02.23 |
|---|---|
| [STARTERS 4기 TIL] R #2 (230221) (0) | 2023.02.21 |
| [STARTERS 4기 TIL] SQL 집계, VIEW, 통계, 순위 (230217) (0) | 2023.02.18 |
| [STARTERS 4기 TIL] SQL 다양한 문법 및 활용 (230216) (0) | 2023.02.18 |
| [STARTERS 4기 TIL] 데이터 베이스 배경, SQL 활용 조작 (230215) (0) | 2023.02.16 |



