
ilovechoonsik
[STARTERS 4기 TIL] R #3 (230222) 본문

ggplot2 패키지 설치 및 기본 문법
ggplot2 사용한 데이터 시각화
ggplot2 사용한 그래프 꾸미기
ggplot2 기반 시각화 실습
영화평 텍스트
국정원 트윗, 발라드 가사
미국 주별 강렬 범죄율
시계열 데이터 예측
통계 분석 기법을 이용한 가설 검정
t 검정 및 통계 분석 유의사항
상관분석
실습 - 와인 성분과 품질 간 관계 구하기
1. ggplot2
1.1 ggplot2 란?
기본 패키지보다 우수한 시각화 기능 제공
gg 문법 구조 바탕, 일관된 규칙에 따라 그래프 생성
-> 요소들의 층으로 이루어진다, data layer 부터 시작하여 각 층의 요소들을 더해 시각화 완성하는 방
1.2 두 가지 함수
(1) qplot : 빠르게 시각화 할 때 사용, 기본 함수 plot과 유사한 사용법
qplot(data=‘사용할 데이터 변수명’, x=‘data에서 x축에 사용할 변수’, y =‘data에서 y축에 사용할 변수’)그래픽 문법 요소 층의 2개 층 표
1층 : data layer (데이터 지정)
2층 : aesthetics layer (x,y축 지정)
추가 가능한 요소
aes(Aesthetics) 요소 추가 가능! : 범주형 컬럼 넣게 된다면, 그 범주 값에 따른 색을 지정!
python의 hue 파라미터
geom(Geometrics) : 그래프 모양 지정
(2) ggplot() : grammar of grapics plot
그래픽 문법 요소 층 전부, 또는 일부를 직접 쌓아 시각화 (+ 연산자로 추가)
원하는 모든 형태의 복잡한 시각화 자료 표현 가능
보통 3층 이상부터는 ggplot() 안에 잘 표현하지 않는다~
ggplot(data=‘데이터 변수 명’, mapping = aes(x=‘data에서 x축에 사용할 변수’, y =‘data에서 y축에 사용할 변수’, ...))
2. ggplot2 [ ~ 3층 : 그래프 기본 세팅]
데이터가 시각화 되기 위해서는 반드시 정의되어야 하는 layer
1층 : data layer (데이터 지정)
2층 : aesthetics layer (x,y축 지정)
3층 : point, line, boxplot 등 최소 1개
2.1 산점도 그래프 - geom_point()
ggplot(dataFrame, aes(x=x축, y=y축)) +
geom_point()+ 연산자 사용하여 추가 layer 추가
- 주요 매개변수
shape: 점 모양
color: 테두리 색
fill: 채우기 색
size: 점 크기
stroke: 테두리 두께
mapping : point 에만 범주별 색 지정하고 싶다면 사용

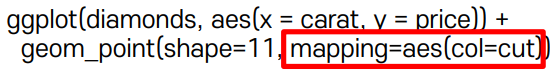
2.2 2층 Aesthetics layer - aes()
aes(x,y,col,fill)
- 주요 매개변수
x,y축 정의 가능
col : 선 색 -> 점(테두리), 선 등에 사용
fill : 색 채우기 -> 막대 그래프, 히스토그램 등에 사용 (선x 채우기만 존재)
2.3 선 그래프 - geom_line()
ggplot(dataFrame, aes(x=x축, y=y축)) +
geom_line()
- 주요 매개변수
color : 선색
size : 선 크기
arrow : 선 끝에 화살표 생성
-> arrow() 함수 매개변수 값으로 사용 (TRUE,FALSE)
2.4 막대 그래프 - geom_bar()
ggplot(dataFrame, aes(x=x축)) +
geom_bar()- 주요 매개변수
shape: 점 모양
color: 테두리 색
fill: 채우기 색
size: 점 크기
stroke: 테두리 두께
2.5 히스토그램 - geom_histogram()
ggplot(dataFrame, aes(x=x축)) +
geom_histogram()
- 주요 매개변수 = geom_bar
binWidth : 히스토그램 데이터를 나누는 구간의 길이 (x가 1~5 일때 0.2 -> 25 구간)
*주의* 히스토그램 바 개수가 아님
geom_bar 주요 매개변수 참고
2.6 상자그림 - geom_histogram()
ggplot(dataFrame, aes(x=x축, y=y축)) +
geom_boxplot()y축 값(수치형)만 입력 가능
x축 값(범주형)과 함께 입력 시, 범주 별 데이터의 상자그림 출력가능
- 주요 매개변수 = geom_bar
3. ggplot2 [ 4~7층 : option layer (그래프 꾸미기) ]

- option layer 종류
4층(Facets) : 범주 값 별 서브그래프 분석
5층(Statistics) : 통계관련 값 시각화
6층(Coordinates) : 좌표계 변환
7층(Theme) : 배경, 제목 등 추가/변경
3.1 4층 Facets layer
2층 aesthetics layer 에서 범주형 컬럼 넣어서 범주값 별로 표현을 했었는데
facets layer는 범주형 컬럼의 변수별 서브 그래프를 각기 다른 패널에 그려주는 층
(1) 문법
‘~’ 뒤에 서브 그래프를 그릴 범주형 컬럼명 기입
ggplot(…) +
geom_xxxx(..) +
facet_xxxx(~’범주형 변수’)
(2) 주요 함수
- facet_wrap() : 1가지 범주형 컬럼에 대한 서브 그래프 출력
1~3계층 +
facet_wrap(~’범주형 컬럼 변수’, labeller=label_value, nrow=NULL, ncol=NULL)- facet_grid() : 2가지 범주형 컬럼에 대한 서브 그래프 출력하는 함수
1~3계층 +
facet_wrap(’범주형 컬럼 변수1’~’범주형 컬럼 변수2’, labeller=label_value)
(3) 주요 매개변수
labeller : 'label_both' 사용시 컬럼명과 범주값 함께 출력
nrow, ncol : 서브 그래프 배치할지 행, 열 결정
3.2 5층 Statistics layer
데이터에 대한 통계값을 시각화 해주는 층
주요 함수
(1) stat_smooth() : 데이터에 회귀선을 그리는 함수
ggplot(…) +
geom_xxxx(..) +
stat_smooth(level=0.95)회귀선 : 데이터 대표하는 값 선으로 이어놓는 것 (추세 확인)

- 주요 매개변수
level : 신뢰구간 (0.0 ~ 1.0)
신뢰구간 < 비례 > 우측 회색 넓이
(2) stat_summary() : x값에 대한 y값의 간단한 통계값을 그래프에 그려주는 함수
어떤 통계함수 적용할지, 어떤 geom 설정할지가 중요
ggplot(…) +
geom_xxxx(..) +
stat_summary(fun.y = mean, color, size, geom = ‘point’)
- 주요 매개변수
fun.y : 구하고 싶은 통계함수 (mean, min, max, median 등)
color : geom 색
size : geom 크기
geom : 통계치를 나타낼 시각화 형태
3.3 6층 Coordinate layer (좌표계 전환)
- x축 또는 y축 정보를 변형하는 시각화
- 주요 함수
coord_cartesian(xlim, ylim) : x축, y축 범위 지정
coord_flip() : x축, y축 반전
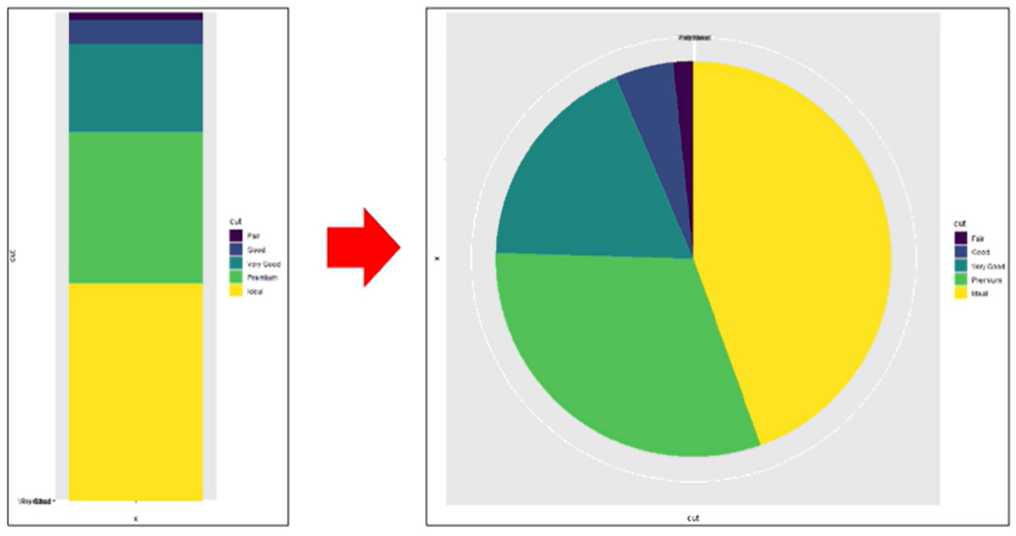
coord_polar() : (x,y) 좌표계를 극좌표계로 변환
= pie 그려주는 함수
+ coord_polar(theta='y')
3.4 7층 Theme layer (배경, 제목 등 추가/변경)
데이터와 무관하게 시각화 요소를 꾸밀 수 있는 층
• 주요 함수
ggtitle(“”) : 제목 작성
theme(…) : 제목, 축, 범례, 판넬, 배경, facet 모양 등의 속성 변경
theme_gray() : 배경을 회색으로 지정
theme_bw() : 배경을 하얀색으로 지정
4. 시각화 실습 - 폭염
4.1 전처리
- strsplit
- index 참조해서 값 가져오기 - for
- 결측치 처리 - boolean indexing
data <- read_excel("day.xlsx", col_names = TRUE, range=cell_cols(4:12) )
data <- data[,c(-3, -4, -6, -8)] #필요없는 컬럼 제거
str(data)
library(dplyr)
# 열 이름 특수문자 제거
result <- data %>% names() %>% strsplit(split="[[:punct:]]")
# 소괄호 바로 넣지 않고, split인자로 [[:punct:]] 줘서 모든 특수문자 구분자로 사용
# 첫 번째 값들만 가져와서 컬럼명으로 지정하면 됨
### 위에서 만든 list에서 필요한 값 들고와 벡터 생성
# index 참조를 통해 직접 값을 들고 올 것 -> list 안 값을 들고올 떄 주로 사용하는 방법
new_name <- c() #빈 벡터 선언
for(t in result){# list의 특정 값을 가져올 때는 index문을 사용하여 index 직접 참조
print(t)
print(paste('first value:', t[1]))
new_name <- c(new_name, t[1]) # 각 벡터의 첫 번째 값만 빈 벡터에 계속 추가
}
print(new_name)
### 컬럼명 변경
names(data) <- new_name
names(data)
### 결측치 값 변경
# '폭염영향예보' 컬럼 NA 값 '보통'으로 변경
data$폭염영향예보[is.na(data$폭염영향예보)] <- '보통' # boolean indexing, na가 있는 곳 데이터만 확보 후 변경
str(data)
na.omit(data) # NA가 존재하는 행 제거
4.2 시각화
ggplot(data, mapping=aes(x=최고기온, y=최고체감온도, col=자외선지수)) +
geom_point() +
facet_wrap(~자외선지수) +
stat_smooth(level=0.99) +
coord_cartesian(ylim=c(20,33)) +
ggtitle('2021년 9월 대한민국 최고기온 대비 최고체감온도') +
theme_bw()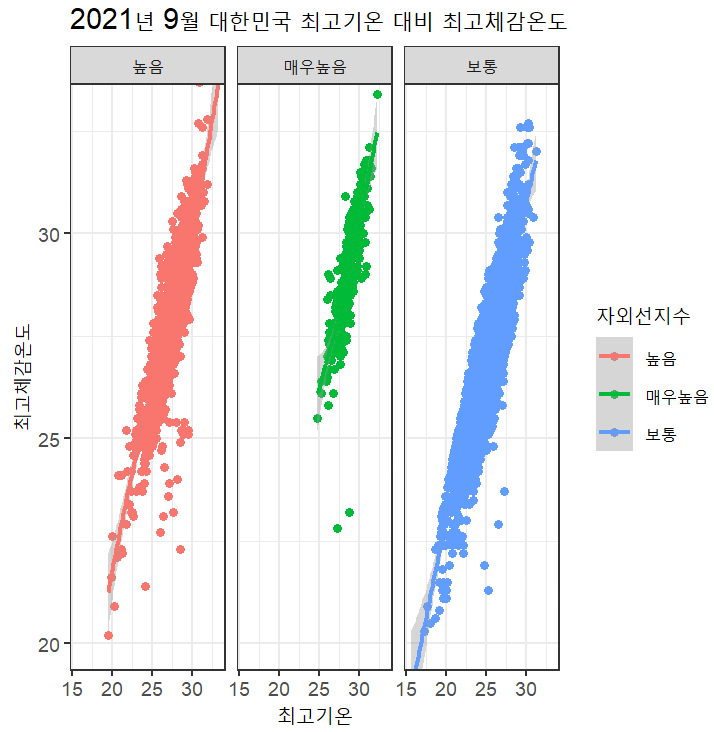
5. 시각화 실습 - 영화평텍스트, 국정원 트윗, 발라드 가사
ing
6. 시각화 실습 - 범죄
#패키지 설치
install.packages("ggiraphExtra")
install.packages('maps')
install.packages("gridExtra")
#패키지 로딩
library(ggiraphExtra)
library(tibble)
library(ggplot2)
library(gridExtra)
### 데이터셋 로딩
# rownames_to_column : 데이터셋 row 값에도 컬럼명 처럼 행 이름이 존재할 수 있는데, 행 명을 하나의 컬럼으로 바꾸는 함수
# USArrests는 행 명이 주 이름으로 되어 있기 때문에 고걸 하나의 컬럼으로 가져오는 것
# 컬럼으로 가져올 떄, 컬럼명은 var= 매개변수로 지정
crime <- rownames_to_column(USArrests, var = 'state')
crime$state <- tolower(crime$state) # 소문자로 변경
print(crime$state)
###
# map_data : maps 패키지에 존재하는 함수!
# 위경도 가져와줌
states_map <- map_data('state')
states_map
### 주별 살인율 단계 구분도 시각화
# Choropleth : 단계 구분도
ggChoropleth(data=crime, aes(fill=Murder, map_id= state), map=states_map, interactive = T)
crime
### 주별 폭행율 인터렉티브 단계 구분도 작성하기
ggChoropleth(data=crime, aes(fill=Assault, map_id = state), map=states_map, interactive=T)
### 인구수 대비 강력범죄 발생율 화면분할 하여 나타내기
# grid.arrange: gridExtra 패키지에 있는 함수
#나타내고 싶은 plot을 각각의 변수에 저장
p1 <- ggplot(data= crime, aes(x=UrbanPop, y=Murder)) +
geom_point() +
stat_smooth(level = 0.9) # 회귀곡선
p2 <- ggplot(data= crime, aes(x=UrbanPop, y=Assault))+
geom_point() +
stat_smooth(level = 0.9)
p3 <- ggplot(data= crime, aes(x=UrbanPop, y=Rape))+
geom_point() +
stat_smooth(level = 0.9)
grid.arrange(p1, p2, p3)

7. 시계열 데이터 예측
install.packages('forecast') # 시계열 데이터 예측 함수 제공
install.packages('quantmod') # 한국 주가 데이터 받아오는 함수 제공
library(forecast)
library(quantmod)
### sin 함수 파형 예측
x = seq(0, 5, 0.01)
y = ts(sin(2 * pi * x) + x, frequency=100)
# ts: time-series 타입
plot(x,y, type='l')
plot(forecast(y, h=200)) #h: 예측할 데이터 개수
# 항공기 고객 수 예측
class(AirPassengers) # ts
plot(x= c(1:144), y=AirPassengers, type="l")
plot(forecast(AirPassengers), h=200)
### 삼성전자 종가 예측
### 예측 모델에 1~8월 데이터 주고, 9,10 종가 예측하도록 작성
library(quantmod) # getSymbols 사용하기 위해 import
data_pred = getSymbols('005930.KS', #삼성전자 주식코드
from = '2021-01-01', to = '2021-09-01',
auto.assign = FALSE)
data_real = getSymbols('005930.KS',
from = '2021-01-01', to = '2021-10-30',
auto.assign = FALSE)
### 전처리
### 1. 컬럼명 전처리
### 2. 날짜값을 x축으로 사용해야 하기 때문에, data는 행 이름을 가지고 있으므로 행 이름 값을 'date' 컬럼으로 이동
### 'date' 컬럼은 Date 타입으로 형 변환환
library(tibble)
# 데이터 컬럼명 변경
names(data_pred) <- c("open", "high", "low", "close", "volume", "adjusted")
names(data_real) <- c("open", "high", "low", "close", "volume", "adjusted")
# 행 이름 열 추가
data_pred <- rownames_to_column(as.data.frame(data_pred), var = 'date')
data_real <- rownames_to_column(as.data.frame(data_real), var = 'date')
# date 컬럼 Date 형식으로 형변환
data_pred$date <- as.Date(data_pred$date)
data_real$date <- as.Date(data_real$date)
# 기존 1~8 데이터 가지구 9,10까지 합쳐서 데이터 예측하면 안 됨
# 뺴서 진행
library(quantmod)
library(forecast)
pred_length <- length(data_real$close)-length(data_pred$close)
# 실제 데이터와 예측용 데이터 간의 크기 차이를 이용해
# forecast 사용
test <- forecast(data_pred$close, h=pred_length)
# 첫 컬럼 - 우리가 예측한 회귀곡선의 선
# 나머지는 신뢰구간
# class 보면 forecast로 확인
# test 안의 첫 회귀곡선 데이터를 data_real에 추가해야 함으로 전처리
# -> as.data.바꿀자료형(바꿀대상데이터)
test <- as.data.frame(test)
length(test$`Point Forecast`)
#시각화 순서
#1. 1~10월 데이터 셋에 1~8월 데이터와 9,10월 예측한 데이터 합쳐서 새로운 컬럼으로 추가 (data_pred의 종가값과 예측 값을 합쳐서 data_real에 ‘pred_close’라는 새로운컬럼으로 등록)
#2. 새롭게 추가한 컬럼을 시각화 하고 실제 데이터를 시각화해서 예측되는 부분에 색 차이를 줘서 확인하기
# ggplot 사용하여 선 그래프 출력
# 예측값에 대한 선은 빨간색으로 지정
# 기존 데이터셋 1~8월 종가+9,10월 예측한 테스트셋 종가를 'pred_close' 컬럼으로 추가
data_real[,"pred_close"] <- c(data_pred$close, test$`Point Forecast`)
str(data_real)
# 나중에 시각화 시 x축에 1달 단위로 넣어야 하기 때문에 추가!
datebreaks <- seq(as.Date("2021-01-01"), as.Date("2021-10-01"), by="1 month")
ggplot(data=data_real, aes(x=date)) +
geom_line(aes(y=pred_close, col='red')) + # 예측선 먼져 빨간색으로 그린다
geom_line(aes(y=close)) +
scale_x_date(breaks=datebreaks) + #Theme layer. x축을 date값으로 나타냄
theme(axis.text.x = element_text(angle=30, hjust=1)) # x축 값 텍스트를 30도 회전
#-> 삼성전자 종가는 예측 완벽히 실패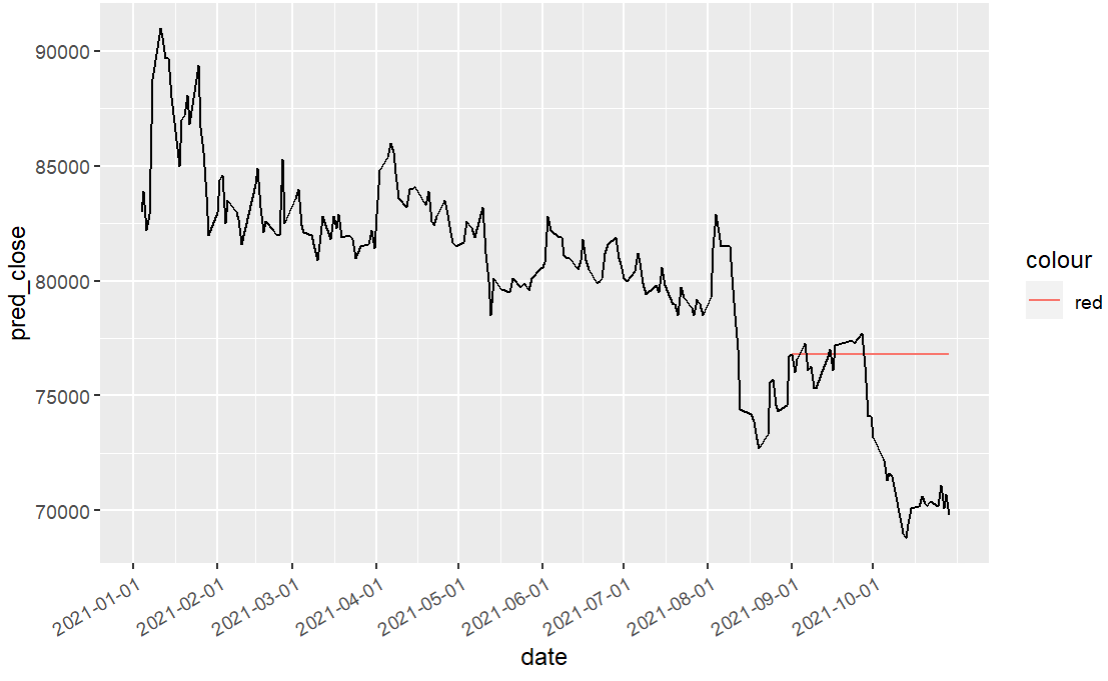
8. 통계 분석 기법을 이용한 가설 검정
8.1 가설검정이란?
: 모집단에 대한 가설을 모집단으로 부터 추출한 표본을 사용하여 검통하는 추론방법

모집단 : 정보를 얻고자 하는 관심 대상의 전체집합
표본 : 모집단으로부터 샘플링 하여 얻어지는 결과
, 모집단의 부분집
가설 설정 : 문제 설정
귀무가설 : 20대 남성 평균 키는 175가 맞다
대립가설 : 20대 남성 평균 키는 175가 아니다
원리 : 통계량을 계산 한 후, 유의 수준을 넘는지 비교
통계량 : 판단을 위해서 계산하여 얻는 1종 오류가 발생할 확률의 허용한계 (보통 5%) 특정 (z, t)
유의수준 : (=틀릴확률) 1종 오류가 발생할 확률의 허용한계

8.2 z-검정?
• 가정
: 모집단은 정규 분포를 따른다고 가정

• 통계량: Z값
- 정규분포에서는 유의 수준에 따른 비교 값이 고정
-> 1% : 2.58, 5% : 1.96, 10%: 1.64
- 모집단의 평균과 표준편차를 알 때 사용
- 유의 수준 값 보다 z값이 크다면 귀무가설 기각
• Z-검정 실습

대립 가설 -> 모집단 평균 175 아니다
귀무가설 유지 여부 -> p-value를 통해 판단
p-value > 유의 수준 = 귀무가설 유지
p-value < 유의 수준 = 귀무가설 기각
p-value : 다양한 통계량을 하나의 특정한 기준으로 보이게 만든 것
8.3 t-검정?

• 가정
: 모집단은 정규 분포를 따른다고 가정
• 통계량 : t값

• t-검정
- 모집단의 표준편차를 모를 때, 표본의 표준편차를 사용해 검정하는 방법
-> 현실에서는 모집단의 표준 편차를 모르는 경우가 더 많기 때문에
t-검정이 훨씬 많이 사용되고 있다.
- 유의수준이 주어졌을 때, t 값이 t분포표 값보다 크다면 귀무가설 기각
• 예시


z- 검정 때와 같이
p-value < 유의수준 : 귀무가설 기각
p-value > 유의수준 : 귀무가설 채용
8.4 양측/단측 검정
양측 검정이란?

- 대립가설이 같지 않다 라는 조건으로 주어지는 경우 사용
같지 않을 조건을 충족시키려면 좌우측으로 얼마나 많이 벗어나는지 확인
- 유의수준 5% -> 양쪽 5%까지 벗어났을 때 같지 않다 -> 궁극적으로 10%만큼 같지 않을 확률
>> 때문에 통계량을 유의수준 /2 값과 비교해야 함.
- 같지 않으면 되는 조건을 말한다, 요 조건은 ? 매우 크던지/매우 작으면 됨
단측 검정이란?
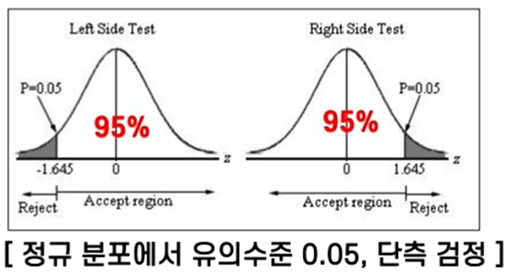
- 대립가설이 크다, 작다 라는 조건으로 주어지는 경우 사용
- 비교 방향이 한 방향 밖에 존재하지 않기 때문에 유의 수준과 동일한 % 끊으면 된다!
- 대립가설이 크다, 작다로 정의되는 경우, 한 쪽으로 얼마나 벗어났는지 비교하는 경우!
결론 및 예시
양측,단측 구별하는 방법은 문제 정의 시 이미 정해진다.
대립가설이 같지 않다 -> 양측 검정
대립조건이 특정한 값보다 작다 -> 더 적은 단측 검정
대립가설이 어떠한 값보다 훨씬 크거나 작다 -> 단측 큰 단측 검정
library("BSDA")
data <- read_excel('man_height.xlsx')
z.test(x=data, alternative = "greater", mu=175, sigma.x=6, conf.level = 0.95)
z.test(x=data, alternative = "less", mu=175, sigma.x=6, conf.level = 0.95)
t.test(x=data, alternative = "two.sided", mu=175, conf.level = 0.95)- 대립가설의 부등호 방향, 등호인지 확인
- 유의수준은 문제 그대로
- z.test : 모집단 평균, 표준편차 넣어준다
- t.test : 모집단 평균만 넣어준다
- 각 함수에서 유의 수준을 별도로 조정할 필요 없다
8.5 z검정, t검정의 전제
- 두 집단에 한한 검정 방법
모 분포와 표본간의 단일한 검정
-> 3개 이상 집단간 검정은 다른 방법론 필요
- 아래 3가지 조건을 만족해야 z,t 검정 사용가능
1. 독립성 : 한 집단에서 사용한 표본을 다른 집단에서 사용 x
2. 정규성 : 표본은 정규분포를 따른다,
3. 등분산성독립성 : 집단 내 특정 샘플이 선택될 확률이 모두 같음

9. 상관분석
9.1 상관분석이란?
: 두 변수 간에 상관이 있는지 알아보는 기법!
9.2 상관계수의 이해
: 상관 내의 크기는 상관계수로 표현! 0~1 사이 값으로 정의
9.3 R기반 상관분석 방법 이해
(1) 피어슨 상관계수 분석
- 연속형 변수의 선형적인 상관관계 측정 구성
ex) 신장과 몸무게의 상관관계 등
가장 기본적으로 사용되는 상관계수

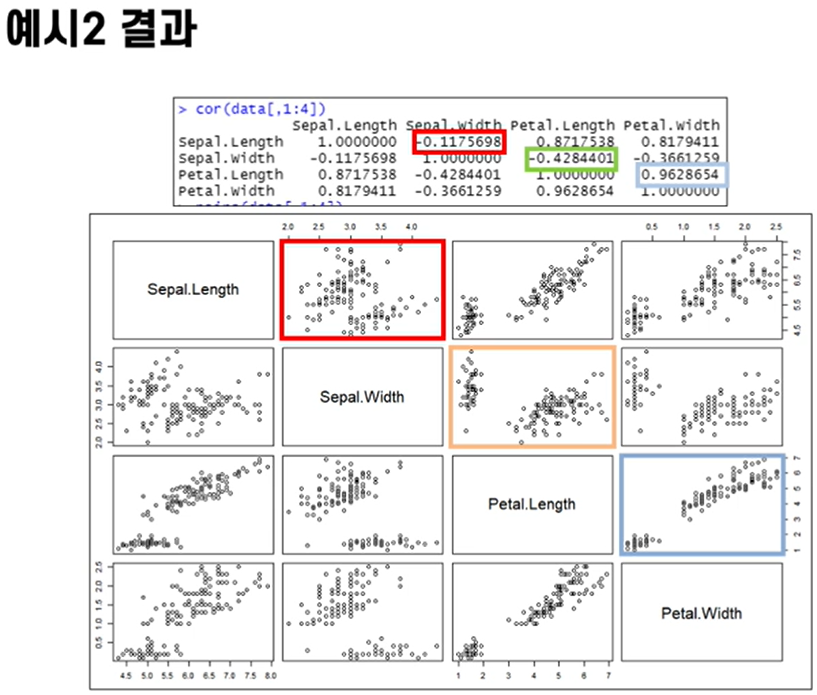
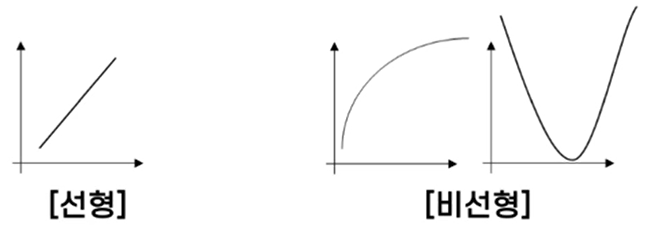
(2) 켄달, 스피어만 상관계수
- 순서가 있는 변수의 상관관계 측정
- 순서가 있는 범주형 데이터 분석가능
ex) 게임 레벨에 따른 승률, 과학 등수에 따른 수학 등수
> 피어슨의 경우 연속되지 않는 값에 대한 계수를 추출하기 불가능
> 그에 반해 범주형 데이터, 연속형 값 간의 상관계수 추출 가능!
> 어떠한 범주형 값이 증가할 때, 그에 따라 수치형 값도 증가 또는 감소하는지 확인 가능
- 비선형적인 상관관계 분석 가능
켄달

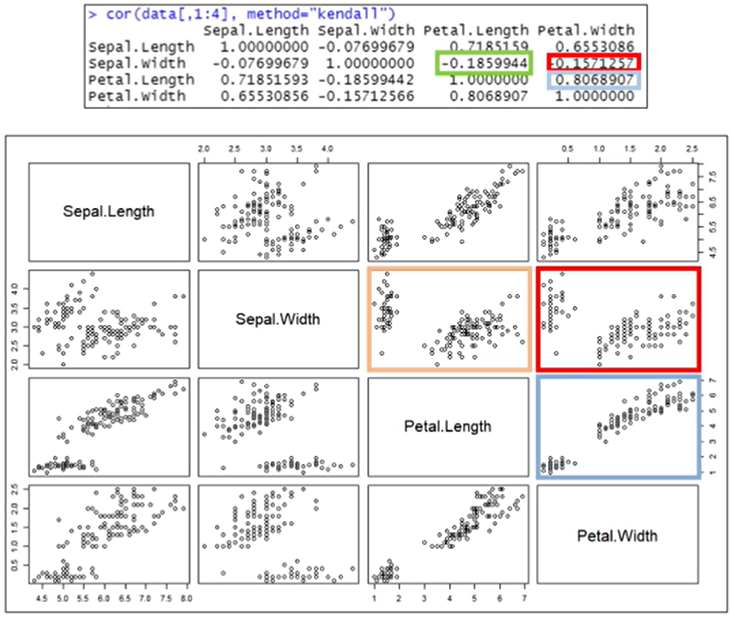
하늘색 : 강력한 선형에 대해서는 피어슨과 비슷
빨강/초록 : 기울기가 0에 수렴하는데, 켄달/스피어만은 어떠한 값이 증가할 때, 따라서 증가/감소하는지 확인하는 방법론이기 때문에 기울기가 0에 가까운 관계는 추출 잘 못함
스피어만


켄달과 유사하지만, 스피어만이 점수를 좀 더 후하게 줌
9.4 시각화 - corrplot

💪🏻 앞으로 개선해야 할 점 (추가로 배워야 할 점)
📌 R도 그렇고 통계 파트도 그렇고 기간을 길게 잡고
꼭꼭 씹어 먹어야 할 개념들을 3일 만에 머리에 넣어봤다!
잘 쳐줘서 4분의 1쯤? 기억에 남는 거 같다🤯 -> 핵심 내용 복습/이해 필수
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] Design Thinking #2 (230224) (0) | 2023.02.24 |
|---|---|
| [STARTERS 4기 TIL] Design Thinking #1 (230223) (0) | 2023.02.23 |
| [STARTERS 4기 TIL] R #2 (230221) (0) | 2023.02.21 |
| [STARTERS 4기 TIL] R (230220) (1) | 2023.02.20 |
| [STARTERS 4기 TIL] SQL 집계, VIEW, 통계, 순위 (230217) (0) | 2023.02.18 |



