
ilovechoonsik
[STARTERS 4기 TIL] 파이썬 기초 (230206) 본문

📖 오늘 내가 배운 것
1. 파이썬 데이터분석 소개
2. 파이썬 시작하기
2.1 기본자료형과 변수
2.2 산술연산, 문자열연산
2.3 문자열 다루기
2.4 반복문
- 조건에 따라 분기하기(if)
- 횟수로 반복하기(for)
- 조건으로 반복하기(while)
- 알고리즘 연습하기
2.5 리스트와, 튜플 만들기
2.6 인덱싱과 슬라이싱
2.7 리스트 변경하기 (추가,수정,삭제)
2.8 리스트 활용
2.9 연습 문제
1. 파이썬 데이터 분석 소개
1.1 데이터 분석
데이터 분석 : 데이터를 정리하고, 변환하고, 조작하고, 검사함으로써 지저분한 원시 데이터에서 유용한 인사이트를 도출하는 작업
데이터 분석가 : 조직이 더 나은 비지니스 의사결정을 할 수 있도록 데이터를 사용해 돕는 역할을 합니다. 수많은 데이터를 정리하고, 유용한 정보를 추출하고 데이터 분석에 기초하여 결정을 내려서 인사이트를 도출해 전달
데이터 분석 목적 : 수집 데이터를 가공하여 정보로 만들고 > 정보와 지식을 결합하여 새로운 지식을 만들고 > 지식에 아이디어 결합하여 창의적인 산물 만들고 > 새로운 가치를 창출
1.2 데이터와 정보
| 구분 | 내용 | 예시 |
| 데이터 | 객관적 사실을 수집하여 모아놓은 자료 | 블로그 방문기록 |
| 정보 | 데이터 가공하여 의미 도출된 것 | 일일 방문자 수, 성별 방문자 수, 시간대별 방문자 수 |
| 지식 | 정보에 개인적 경험을 결합시킨 새로운 지식 | 방문자가 많은 성별/나이에 대한 원인 파악 |
| 지혜 | 지식에 아이디어가 결합된 창의적 산물 | 방문자가 많은 성별/나이를 타겟으로 운영 전략 수립 |
1.3 데이터 분석 절차
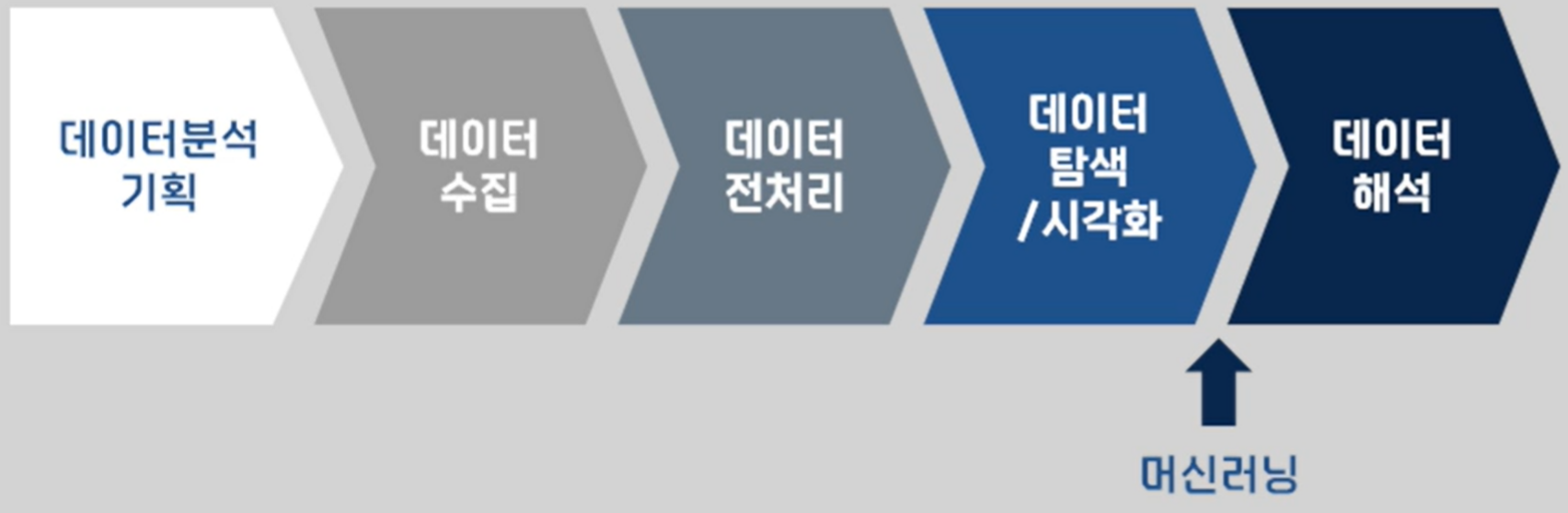
(1) 데이터 분석 기획
- 문제 정의 : 해결해야 할 문제 정의
- 데이터 정의 : 분석에 필요한 데이터 속성 정의
- 분석 목적 : 현상 파악/원인 분석/추세분석 및 예측
# 데이터 속성이란? : 데이터의 구체적인 정보 항목으로 더 이상 분리될 수 없는 최소의 데이터 보관 단위
ex) 온난화 현상을 파악을 위해 필요한 데이터 속성 : 연도별 평균기온
(2) 데이터 수집
- 기업의 데이터베이스 (일반인 접근 x)
- 공공데이터
- 민간데이터 (유료/무료)
- 웹스크래핑
- 설문
- 센서 데이터
#공공 데이터란? : 국가의 다양한 데이터를 공공데이터법에 따라 개방하여 국민들이 보다 쉽고 용이하게 활용할 수 있도록 제공하는 데이
(3) 데이터 전처리
수집한 데이터는 바로 분석하기 힘들 수 있다! 이에 데이터를 분석하기 알맞게 정재하고 가공 (분석에서 가장 많은 시간 소요)
- 필요한 속성만 추출 : 불필요한 컬럼 제거
- 조건에따라 데이터 추출 : 최근 ~년 데이터만 추출
- 결측치 식별/처리 : 버이었는 값, 신뢰도 떨어질 수 있다.
- 대표값으로 대치 : 중간값, 최빈값, 평균값
- 주변값으로 대치 : 이전값, 다음값
- 결측치 삭제 : 결측치 존재하는 행 삭제, 결측치 많은 열 삭제
- 이상값 식별/처리 : 이상치는 보통 제거! (그래프 그려서 튀는 값 있는지 확인)
- 자료형 변경 : 숫자로 처리해야 하는 데이터가 문자형 존재, 시계열 데이터가 문자형으로 되어 있는 경우
- 테이블 형태 변경
- 행/열 변경
- 컬럼명/인덱스 변경
- 새로운 속성 추가
- 여러 데이터 연결
- (어떤 통계값 사용한다면) 데이터 그룹핑
(4) 데이터 탐색/시각화
- 통계적 특성 이해, 시각화
- 데이터에 대한 이해!
(5) 데이터 해석
- 인사이트 도출 : 현상 파악, 원인 도출, 추세를 파악/예측
2. 파이썬 기초
2.1 기본자료형과 변수
- 기본 자료형
- 정수형 int
- 실수형 float
- 문자열형 string
- 부울형 bool
- 변수란? : 데이터가 저장되는 메모리 공간
- 규칙 : 영문,숫자, _만으로 구성
- 대문자 소문자를 구분
- 중간에 공백 존재하면 안 됨
- 문자나 밑줄로 시작해야 함
- 예약어는 변수명으로 사용할 수 없음 (파이썬 문법에 사용되는 단어)
- 역할을 짐작하기 쉬운 이름 설정
2.2 산술연산, 문자열연산
(1) 산술연산
a, b = 3,4
print('a+b=',a+b) # 더하기
print('a-b=',a-b) # 빼기
print('a*b=',a*b) # 곱셈
print('a/b=',a/b) # 나눗셈
print('a//b=',a//b) # 나눗셈 - 몫
print('a%b=',a%b) # 나눗셈 - 나머지
print('a**b=',a**b) # 거듭제곱
''' 결과
a+b= 7
a-b= -1
a*b= 12
a/b= 0.75
a//b= 0
a%b= 3
a**b= 81
'''- 산술연산의 우선순위는 수학에서와 동일한 규칙을 갖는다
(2) 문자열 연산
# 문자열 더하기(문자열 연결하기)
a = 'good'
b = 'morning'
a+b
### goodmorning
# 문자열 곱하기(문자열 반복하기)
s = 'ha'
s * 3
### 'hahaha'
# 문자열과 숫자형 더하기
english = 80
result = '영어점수'+ str(english)
print(result)
### 영어점수80# 주의할 점: 문자열 덧셈 연산 시 데이터 형은 모두 문자형이어야 함
(3) 복합할당연산자

(4) f스트링으로 변수값 출력하기
print(f'나이는 {age}살이시군요. 내년이면 {age+1}살이 되시겠네요')
### 나이는 20살이시군요. 내년이면 21살이 되시겠네요
a = int(input('첫번째숫자:'))
b = int(input('두번째숫자:'))
print(f'{a}+{b}={a+b}')
### 1+3=4문자 사이에 변수값 쉽게 출력 가능
(5) 연습문제
#화씨 온도를 입력받아 섭씨 온도로 변환하는 프로그램을 작성해보세요.
#𝐶=(𝐹−32)∗59
# 화씨온도 입력
# 온도는 보통 실수형으로 사용되기 때문에 float으로 받아야 함!
F = float(input("화씨 온도를 입력하세요 : "))
# 섭씨온도로 계산
C = (F-32) * (5/9)
# 결과 출력
print(f'화씨 온도: {F} --> 섭씨 온도 :{C}')
2.3 문자열 다루기
(1) 문자열 인덱스
: 문자의 자리 번호
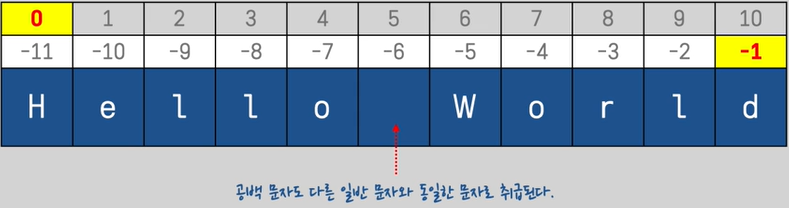
(2) 문자열 슬라이싱
: 문자열의 일정 범위를 추출하는 작업 - 문자열[시작인덱스 : 끝 인덱스 : 간격]
- 양,음수로 추출
a = 'Hello World'
print(a[0:5]) # 'Hello' 출력하기
print(a[6:11]) # 'World' 출력하기
'''
Hello
World
'''
print(a[-11:-6]) # 'Hello' 출력하기
print(a[-5:]) # 'World' 출력하기
'''
Hello
World
'''
- 첫, 끝 인덱스 생략 가능
a = 'Hello World'
# 'Hello'
print(a[:5])
# 'World'
print(a[6:])
# 'Hello World'
print(a[:])
'''
Hello
World
Hello World
'''
- 한문자씩 건너뛰어 출력하기 a[::2]
a = 'Hello World'
print(a[::2])
# HloWrd
- 역순으로 출력 : 간격을 마이너스(-)로 하면 역순으로 출력된다. a[::-1]
a = 'Hello World'
print(a[::-1])
# dlroW olleH
(3) 문자열 함수
- find(찾을 문자열)
: 찾을 문자열 시작 인덱스 찾기
a = 'Hello, Python!!!'
# 'e'의 위치 찾기
print(a.find('e'))
# 'l'의 위치 찾기
print(a.find('l'))
###1
###2
- replace(찾을 문자열, 교체할 문자열)
: 찾을 문자열을 교체할 문자열로 바꾸기
a = '나는 초코우유 좋아. 초코우유 최고'
# '초코'-->'딸기'로 교체
print(a.replace('초코','딸기'))
###나는 딸기우유 좋아. 딸기우유 최고
- lower(), upper()
: 문자열 모두 소/대문자로 바꾸기
a = 'Hello, Python!!!'
a.lower() # 소문자로!
###'hello, python!!!'
a.upper() # 대문자로!
###'HELLO, PYTHON!!!'
- split('구분자')
: 문자열을 구분자 기준으로 나누기 : 결과 list로 반환
phone = '010-123-4567'
phone.split('-')
###['010', '123', '4567']
email = 'abc@naver.com'
email.split('@')
###['abc', 'naver.com']
(4) 연습 문제
- 사용자의 영문 이름을 입력받아 성과 이름 순서를 바꾸어서 출력하는 프로그램을 작성하세요.
- 성과 이름은 공백으로 구분합니다.
# 사용자의 영문이름 입력받기 (성과 이름은 공백으로 구분)
full_name = input('영문이름(성, 이름 공백으로 구분): ')
# 공백의 위치 찾기 -> find
space = full_name.find(' ')
# 성, 이름을 슬라이싱하여 각각 변수에 담기
first_name = full_name[:space]
last_name = full_name[space+1:] # 공백 다음부터 시작!
print(last_name, first_name)
'''
영문이름(성, 이름 공백으로 구분): kim minsu
minsu kim
'''
2.4 반복문
(1) 프로그램의 3가지 기본 제어 구조
- 순차구조 : 코드를 작성한 순서에 따라 명령어들이 순차적으로 실행
- 선택구조 : 조건에 따라 명령을 선택하여 실행하는 구조
- 반복구조 : 동일한 명령이 반복되면서 실행되는 구조
- 들여쓰기 : 파이썬에서는 들여쓰기로 코드를 묶어준다. 들여쓰기 간격은 같아야 한다.
(2) if - 조건에 따라 분기하기
- if : 조건 만족할 때 명령 실행
- if, else : 조건을 만족할 때, 만족하지 않을 때로 분기
- if, elif : 여러 개의 조건 중 만족하는 조건 찾아서 실행 분기
: 조건식 결과가 True = 해당 문장 실행 후 다음 조건식 검사하지 않고 바로 조건문 빠져나옴
# 점수를 입력받고 점수의 범위에 따라 등급을 출력하는 프로그램을 작성하세요.
#등급 A B C D F
#점수 90이상 80~89 70~79 60~69 0~59
score = int(input('점수:'))
if score>=90:
grade='A'
elif score>=80:
grade='B'
elif score>=70:
grade='C'
elif score>=60:
grade='D'
else:
grade='F'
print('grade:',grade)
- 연습문제
# 짝수/홀수로 나뉘기 때문에 if/else로 작성
# 근데 0은? 홀수/짝수가 아니기 때문에 elif로 조건에 추가
num = int(input('정수:'))
if num%2 == 1:
print('홀수')
elif num==0:
pirnt(0)
else:
print('짝수')
###정수:3
###홀수
(3) for - 횟수로 반복하기
- for? : 시퀀스를 순회할 때 주로 사용되는 반복 구조
- 시퀀스 : 여러 값이 연속적으로 이어진 자료 : 리스트 튜플 문자열
for i in [1,2,3,4,5]:
print(i)
'''
1
2
3
4
5
'''
for i in 'python':
print(i)
'''
p
y
t
h
o
n
'''
for i in range(5): #0,1,2,3,4
print(i)
'''
0
1
2
3
4
'''
- range 함수

- 중첩반복구조
- 내부 for문을 외부 for문의 시퀀스만큼 반복한다.
- 내부루프와 외부루프는 동일한 제어변수를 사용해서는 안된다.
# 가로로 1단씩 출력 -> 2-9까지 고정시켜 놓고, 1~9까지 돌려야 함
# 내부 2,10 / 외부 1,10
for i in range(2,10):
for j in range(1,10):
print(f'{i}*{j}={i*j}', end='\t') #간격 맞추기 위해 \t로 탭
print() #한 단이 끝나면 줄 바꿈
'''
2*1=2 2*2=4 2*3=6 2*4=8 2*5=10 2*6=12 2*7=14 2*8=16 2*9=18
3*1=3 3*2=6 3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27
4*1=4 4*2=8 4*3=12 4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 5*6=30 5*7=35 5*8=40 5*9=45
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 6*7=42 6*8=48 6*9=54
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 7*8=56 7*9=63
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 8*9=72
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
'''
# 세로로 1단씩 출력 -> 1~10 고정시키고 2~10 돌려야 함
# 외부 (1,10) / 외부 (2,10)
for i in range(1,10):
for j in range(2,10):
print(f'{j}*{i}={j*i}', end='\t')
print()
'''
2*1=2 3*1=3 4*1=4 5*1=5 6*1=6 7*1=7 8*1=8 9*1=9
2*2=4 3*2=6 4*2=8 5*2=10 6*2=12 7*2=14 8*2=16 9*2=18
2*3=6 3*3=9 4*3=12 5*3=15 6*3=18 7*3=21 8*3=24 9*3=27
2*4=8 3*4=12 4*4=16 5*4=20 6*4=24 7*4=28 8*4=32 9*4=36
2*5=10 3*5=15 4*5=20 5*5=25 6*5=30 7*5=35 8*5=40 9*5=45
2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 7*6=42 8*6=48 9*6=54
2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 8*7=56 9*7=63
2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 9*8=72
2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
'''
- 연습문제
# 1부터 10까지 정수의 합
total = 0
for i in range(1,11):
total += i
print(total)
# 55
# 1부터 100까지 홀수의 합
total = 0
for i in range(1,101):
if i%2==1:
total+=i
print(total)
# 2500
(4) while - 조건으로 반복하기
- 반복문을 사용할 때 범위를 지정할 수 없는 경우, 특정 값이 들어왔을 때 종료하고 싶은 경우 사용
- while 문만 가능한 겨우 : 반복의 횟수가 정해지지 않았을 때!
'q'를 입력할 때까지 반복하여 이름 입력받기
while True:
name = input('이름:')
if name=='q':
break #조건에서 빠져나오기 위해 break 사용
'''
이름:a
이름:b
이름:c
이름:d
이름:f
이름:q
'''
- 연습문제
'''
올바른 아이디/비밀번호를 입력할 때까지 아이디와 비밀번호를 입력하는 프로그램 만들기
확장하기
아이디가 잘못되었으면 '아이디를 확인하세요' 출력
비밀번호가 잘못되었으면 '비밀번호를 확인하세요' 출력
입력 횟수가 정해지지 않았기 때문에 while 사용
'''
# 올바른 아이디와 비밀번호
id = 'id123'
pwd = 'pwd123'
while True:
input_id = input('id:')
input_pwd = input('pwd:')
if id==input_id and pwd==input_pwd:
break
if id!=input_id:
print('아이디를 확인하세요')
if pwd!=input_pwd:
print('비밀번호를 확인하세요.')
#사용자가 0을 입력할 때까지 숫자을 입력받아 입력받은 숫자들의 합을 구하는 프로그램을 작성하세요
total = 0
while True:
i = int(input('숫자를 입력하세요! : '))
if i != 0:
total += i
else:
print(total)
break
(5) 알고리즘 연습하기
- up&down 숫자맞추기 게임
# 1~100 사이의 정답 숫자를 랜덤으로 하나 정하고, 정답 숫자를 맞출 때까지 숫자를 입력하는 게임이다.
# 내가 입력한 숫자가 정답보다 작으면 'DOWN', 정답보다 크면 'UP'을 출력하고 숫자를 다시 입력받는다.
# 정답을 맞추면 '정답!'이라고 출력하고 게임을 끝낸다.
# 조건
# 기회는 5번까지만 주어집니다.
# 5회가 넘으면 '횟수초과' 메시지와 함께 정답을 알려줍니다.
# 정답을 맞추면 몇번째에 맞추었는지 출력합니다.
import random
num = random.randrange(1,101)
cnt = 0
while True:
cnt += 1
i = int(input('숫자 입력 : '))
if cnt == 5:
print(f'횟수 초과! 정답은 : {num}')
break
if i < num:
print('UP')
elif i > num:
print('DOWN')
else:
print(f'정답! {cnt}번만에 맞췄다')
break- 사칙연산 프로그램
# 두 수와 사칙연산기호(+,-,*,/)을 입력받아 연산 기호에 따라 연산 결과를 출력하는 프로그램을 작성하세요.
# 사칙연산기호(+,-,*,/)가 아닌 경우 '잘못입력하셨습니다' 출력
num1 = int(input('첫 번째 숫자'))
num2 = int(input('두 번째 숫자'))
op = input('사칙연산 기호')
if op=='+':
print(f'{num1}+{num2}={num1+num2}')
elif op=='-':
print(f'{num1}-{num2}={num1-num2}')
elif op=='*':
print(f'{num1}*{num2}={num1*num2}')
elif op=='/':
print(f'{num1}/{num2}={num1/num2}')
else:
print('잘못 입력하셨습니다.')- 할인된 금액 계산
# 물건 구매가를 입력받고, 금액에 따른 할인율을 계산하여 구매가, 할인율, 할인금액, 지불금액을 출력하세요.
price = int(input('물건구매가:'))
if price>=100000:
dc = 10
elif price>=50000:
dc = 7
elif price>=10000:
dc=5
else:
dc=0
print(f'''
구매가:{price}
할인율:{dc}
할인금액:{price*(dc/100)}
지불금액:{price-price*(dc/100)}
''')
2.5 리스트와 튜플
(0) 파이썬 복합 자료형

(1) 리스트란?
여러 개의 데이터 값을 하나의 변수에 담을 수 있는 자료구조

- 리스트 만들기
# []를 사용하여 빈 리스트 만들기
l1 = []
### []
# list() 함수를 사용하여 빈 리스트 만들기
l2 = list()
### []
# []를 사용하여 초기값이 있는 리스트 만들기
l3 = [1,3,5,7,9]
### [1,3,5,7,9]
# list() 함수를 사용하여 초기값이 있는 리스트 만들기(규칙이 있는 정수값의 나열)
l4 = list(range(1,100,2))
### [1,3,5,7,9,11,...99]
(2) 튜플이란?
- 튜플?
리스트와 동일하지만 튜플은 ()로 둘러쌈
리스트는 값의 생성, 삭제, 수정 가능하지만 튜플은 값을 바꿀 수 없다.
- 사용 시점
프로그램이 실행되는 동안 값이 바뀌면 안 되는 경우
함수에 인자를 전달하거나 값을 리턴할 때 사용되는 경우가 많음
- 튜플 만들기
# ( )를 사용하여 빈 튜플 만들기
t1 = ()
# tuple() 함수를 사용하여 빈 튜플 만들기
t2 = tuple()
# ( )에 초기값 지정하여 튜플 만들기
# 튜플을 만들 때 괄호()를 생략할 수 있다.
t3 = (1,3,5,7,9)
t4 = 1,3,5,7,9
# 항목이 1개일 때는 ,를 붙인다.
t5 = (1,)
t6 = 1,
###(1,)
# tuple() 함수를 사용하여 초기값이 있는 튜플 만들기(규칙이 있는 정수값의 나열)
t7 = tuple(range(1,100,2))
###(1,3,5,7,...99)(3) 리스트, 튜플 자료형
- 모든 자료형이 혼합되어 들어갈 수 있다.
list1 = ['amy',20,165.5, ['독서','코딩']]
### ['amy', 20, 165.5, ['독서', '코딩']]
tuple1 = ('amy',20,165.5, ['독서','코딩'])
### ('amy', 20, 165.5, ['독서', '코딩'])
(4) 리스트, 튜플 연결하기
연결 : +
반복 : *
값 존재하는지 확인 : in, not in
항목의 갯수 : len
예시
# 존재여부 확인
l = [1,2,3,4,5]
t = (1,2,3,4,5)
print(5 in l)
print(10 in l)
print(5 not in l)
print(10 not in l)
'''
True
False
False
True
'''
# 갯수 구하기
l = [1,3,2,4,3,5,7,8,77.7,88.8,'a','b','c',[10,20,30]]
len(l)
### 14
t = ((1,2),[3,4])
len(t)
### 2
2.6 인덱싱과 슬라이싱
(1) 인덱싱
- 인덱스?
- 인덱스로 항목 추출
- 리스트명[인덱스]
- 튜플명[인덱스]
- 중첩리스트, 튜플 인덱싱
# 아래 리스트 l에서 '수박' 인덱싱하여 가져오기
l2 = ['사과','오렌지','포도',['수박','바나나']]
l2[3][0] # 3번째 중 0번째
# 아래 튜플 t에서 'Life' 인덱싱하여 가져오기
t2 = (1,2,('a','b',('Life','is')))
t2[2][2][0] (2번째 중 2번째 중 0번째)
(2) 슬라이싱
- 슬라이싱?
: 리스트 혹은 튜플의 일부를 추출하여 새로운 리스트로 만든다.
- 인덱스로 슬라이스
- 리스트명[시작인덱스:끝인덱스:간격]
- 튜플명[시작인덱스:끝인덱스:간격]
l1 = ['축구','농구','배구','야구','족구','발야구','피구']
# 족발피
l1[-3:]
### ['족구', '발야구', '피구']
# 모든 항목 역순으로
l1[::-1]
### ['피구', '발야구', '족구', '야구', '배구', '농구', '축구']
# ['발야구','족구','야구']
# 역순으로 가져와야 할 때 야구=-4번째, 발야구=-2번째
l1[-2:-5:-1]
### ['발야구','족구','야구']
# 아래 리스트 l3에서 홀수만 슬라이싱하기
l3 = list(range(1,21))
l3[::2]
### [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
(3) 항목의 인덱스 찾기
- 리스트명.index(항목)
- 튜플명.index(항목)
t1 = ('스키','보드','스케이트','스케이트보드','수상스키','웨이크보드')
# '스케이트'의 인덱스 찾기
t1.index('스케이트')
### 2
# '오토바이'의 인덱스 찾기
t1.index('오토바이')
### 오류
# 오류 처리?
if '오토바이' in t1:
print(t1.index('오토바이'))
else:
print('존재하지 않음')
2.7 리스트 변경하기 (추가,수정,삭제)
(1) 추가
- 리스트명.append(항목) : 리스트 끝에 항목 추가
- 리스트명.insert(인덱스, 항목) : 리스트 중간에 항목 삽입
- 리스트명.extend(리스트) : 리스트 끝에 여러 항목 추가
todolist = ['양치','물마시기']
# '아침운동' 항목 추가하기
todolist.append('아침운동')
### ['양치', '물마시기', '아침운동']
# '아침운동'하기 전에 '아침식사'
todolist.insert(2,'아침식사')
### ['양치', '물마시기', '아침식사', '아침운동']
# '아침운동' 후에 ['샤워','드라이','공부']
todolist.extend(['샤워','드라이','공부'])
### ['양치', '물마시기', '아침식사', '아침운동', '샤워', '드라이', '공부']
(2) 수정
- 리스트명[인덱스] = 항목 : 항목 수정
- 리스트명[시작인덱스:끝인덱스] = 리스트 : 여러 항목 수정
todolist = ['양치', '물마시기', '아침식사', '아침운동', '샤워', '드라이', '공부']
# 아침운동-->산책으로 수정
todolist[3]='산책'
### ['양치', '물마시기', '아침식사', '산책', '샤워', '드라이', '공부']
# '아침식사','산책' --> '독서','산책','아침식사'
todolist[2:4] = ['독서','산책','아침식사']
### ['양치', '물마시기', '독서', '산책', '아침식사', '샤워', '드라이', '공부']
(3) 삭제
- del 리스트명[인덱스] : 인덱스 이용하여 항목 삭제
- 리스트.remove(항목) : 항목값을 이용하여 삭제 - 항목이 여러개인 경우 앞의 인덱스만 삭제
- 리스트.pop() : 마지막 항목 반환하고 삭제
todolist = ['양치', '물마시기', '독서', '산책', '아침식사', '샤워', '드라이', '공부']
# 마지막 인덱스 삭제
del todolist[-1]
### ['양치', '물마시기', '독서', '산책', '아침식사', '샤워', '드라이']
# '양치' 삭제
todolist.remove('양치')
['물마시기', '독서', '산책', '아침식사', '샤워', '드라이']
a = todolist.pop()
a
### '드라이'
todolist
### ['물마시기', '독서', '산책', '아침식사', '샤워']
(4) 연습문제
# 아래 wishlist의 '시계','신발'을 myCart로 이동해봅시다.
wishlist = ['가방','시계','신발']
mycart = []
#wishlist의 시계, 신발을 추출해서 mycart에 담는다.
mycart.extend(wishlist[1:3])
mycart
### ['시계','신발']
#wishlist의 시계, 신발을 삭제한다.
del wishlist[1:3]
wishlist
### ['가방']
2.8 리스트 활용
(1) 리스트 통계값
- 항목수 : len(리스트명)
- 합계 : sum(리스트명) - 모든 항목이 숫자여야 함
- 최소값 : min(리스트명) - 숫자, 문자 모두 가능하지만 한 가지로 이루어져 있어야 함
- 최대값 : max(리스트명) - 숫자, 문자 모두 가능하지만 한 가지로 이루어져 있어야 함
- 항목의 갯수 : 리스트명.count(항목)
l = [1,2,3,4,5,3,4,5]
print('항목수:',len(l))
print('합계:',sum(l))
print('최소값:',min(l))
print('최대값:',max(l))
print('평균:',sum(l)/len(l)) # 평균 구하는 함수는 없음, 직접 구해야 함
print('항목5의 갯수:',l.count(5))
'''
항목수: 8
합계: 27
최소값: 1
최대값: 5
평균: 3.375
항목5의 갯수: 2
'''
(2) 리스트 정렬하기
- 원본리스트 정렬
- 리스트명.sort()
- 리스트명.sort(reverse=True) : 욕순
friends = ['수지','지은','찬혁','수현','범준']
friends.sort()
### ['범준', '수지', '수현', '지은', '찬혁']
friends.sort(reverse=True)
### ['찬혁', '지은', '수현', '수지', '범준']
- 복사본 만들어서 정렬
- sorted(리스트명)
- sorted(리스트명, reverse=True) : 역순
friends = ['수지','지은','찬혁','수현','범준']
sorted_friends = sorted(friends)
sorted_friends
###['범준', '수지', '수현', '지은', '찬혁']
friends
['수지', '지은', '찬혁', '수현', '범준']
- 리스트 순서 뒤집기
- 리스트명.reverse() : 순서 뒤집기
friends = ['수지','지은','찬혁','수현','범준']
friends.reverse()
### ['범준', '수현', '찬혁', '지은', '수지']
(3) 2차원 리스트 다루기

# 리스트 만들기
l2 = [[10,20,30],[40,50,60]]
'''
0열 1열 2열
0행 10 20 30
1행 40 50 60
'''
# 30 추출하기
print(l2[0][2]) #0행 2열
###30
# 1행 2열 추출하기
print(l2[1][2])
###30
###60
(4) 연습문제
# 파일리스트에서 파일명과 확장자를 분리하여 다음과 같은 형태로 저장하는 리스트를 만들어봅시다.
'''
파일명 확장자
file1 py
file2 txt
file3 pptx
'''
file_list = ['file1.py','file2.txt','file3.pptx']
name_extension = []
for i in file_list:
#print(i.split('.')) .split 분리 [['file1','py'],...,['file3','pptx']]
name_extension.append(i.split('.')) #name_extension에 list 1개씩 추가
print(name_extension)
###[['file1', 'py'], ['file2', 'txt'], ['file3', 'pptx']]
2.9 연습 문제
(1) 과목별 평균 구하기
'''
다음은 학생 별 [국어,영어,수학]점수가 저장된 리스트이다.
score_list = [[96,84,80],[96,86,76],[76,95,83],[89,96,69],[90,76,91]]
각 학생의 세 과목의 성적의 [총점, 평균]을 구하여 리스트에 담으시오.
(평균은 반올림하여 소수점 1자리까지 표현한다.)
'''
score_list = [[96,84,80],[96,86,76],[76,95,83],[89,96,69],[90,76,91]]
stu_scores = []
for i in score_list:
total = sum(i)
average = total/3
#print([total,rount(average,1)])
stu_scores.append([total,round(average,1)])
stu_scores
###[[260, 86.7], [258, 86.0], [254, 84.7], [254, 84.7], [257, 85.7]]
(2) 과목별 평균 구하기
'''
다음은 학생 별 [국어,영어,수학]점수가 저장된 리스트이다.
score_list = [[96,84,80],[96,86,76],[76,95,83],[89,96,69],[90,76,91]]
각 과목의 리스트를 분리하고 과목별 평균을 구해봅시다. 평균은 소수점 1자리까지 출력한다.
'''
score_list = [[96,84,80],[96,86,76],[76,95,83],[89,96,69],[90,76,91]]
kor_list=[]
eng_list=[]
math_list=[]
kor_average=0
eng_average=0
math_average=0
#각 과목의 리스트 분리하기
for i in score_list:
#print(i)
kor_list.append(i[0])
eng_list.append(i[1])
math_list.append(i[2])
print('kor_list:',kor_list)
print('eng_list:',eng_list)
print('math_list:',math_list)
kor_average = sum(kor_list)/len(kor_list)
eng_average = sum(eng_list)/len(eng_list)
math_average = sum(math_list)/len(math_list)
print('kor_average:',round(kor_average,1))
print('eng_average:',round(eng_average,1))
print('math_average:',round(math_average,1))
'''
kor_list: [96, 96, 76, 89, 90]
eng_list: [84, 86, 95, 96, 76]
math_list: [80, 76, 83, 69, 91]
kor_average: 89.4
eng_average: 87.4
math_average: 79.8
'''
(3) 랜덤 항목 추출하기
- random.choice(리스트명)
menulist = ['한식','일식','중식','양식','분식','이탈리아식']
print('오늘은 뭘먹지?')
import random
random.choice(menulist)
'''
메뉴를 입력받아 랜덤으로 메뉴를 정하는 프로그램을 작성해봅시다.
공백('')을 입력할 때까지 메뉴를 입력받습니다.
'''
menulist = []
while True:
menu = input('메뉴:')
if menu=='':
break
menulist.append(menu)
print('오늘의 메뉴는:',random.choice(menulist))
'''
메뉴:치킨
메뉴:피자
메뉴:햄버거
메뉴:
오늘의 메뉴는: 피자
'''#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] 데이터 시각화 #2 (230213) (0) | 2023.02.13 |
|---|---|
| [STARTERS 4기 TIL] 데이터 시각화 (230210) (0) | 2023.02.10 |
| [STARTERS 4기 TIL] 공공 데이터 분석 (230209) (0) | 2023.02.09 |
| [STARTERS 4기 TIL] 파이썬 전처리 베이스 (230208) (0) | 2023.02.08 |
| [STARTERS 4기 TIL] 파이썬 기초 + 판다스, 시리즈 (230207) (0) | 2023.02.07 |



