
ilovechoonsik
[STARTERS 4기 TIL] 파이썬 기초 + 판다스, 시리즈 (230207) 본문

📖 오늘 내가 배운 것
1. 딕셔너리
2. 함수
3. 람다표현식과 map 함수
4. 클래스와 객체
5. 모듈과 패키지
6. 판다스
7. 시리즈
1. 딕셔너리
1.1 딕셔너리?
- 키:값 쌍을 이루어 하나의 항목으로 저장되는 자료형
- 키와 값은 콜론(:)으로 구분
- 중괄호{} 안에 , 로 구분하여 항목을 저장

1.2 딕셔너리 만들기
- 중괄호 안에 키
- 중괄호 안에 키:값의 쌍으로 된 항목을 콤마(,)로 구분하여 적어준다.
- menu = {'김밥':2000, '떡볶이':2500, '어묵':2000, '튀김':3000}
- dict()로 딕셔너리 만들기
(1) 딕셔너리명 = dict(키1=값1, 키2=값2,...,)
- 키에 따옴표('')를 쓰지 않는다는 점에 주의한다.
- 키에 따옴표('')를 쓰지 않아도 딕셔너리가 생성되면서 자동으로 문자열형으로 지정된다.
- menu1 = dict(김밥=2000, 떡볶이=2500, 어묵=2000, 튀김=3000)
(2) 딕셔너리명 = dict(zip(key리스트, value리스트)) # zip = 동일한 개수로 이루어진 데이터 묶어서 리
- menu2 = dict(zip(['김밥','떡볶이','어묵','튀김'],[2000,2500,2000,3000]))
(3) 딕셔너리명 = dict([(키1,값1),(키1,값2),...,])
- menu3 = dict([('김밥',2000),('떡볶이',2500),('어묵',2000),('튀김',3000)])
(4) 딕셔너리명 = dict({키1:값1,키2:값2,...,})
- menu4 = dict({'김밥':2000, '떡볶이':2500, '어묵':2000, '튀김':3000})
결과
{'김밥': 2000, '떡볶이': 2500, '어묵': 2000, '튀김': 3000}
1.3 딕셔너리에 사용할 수 있는 자료형과 키 값 특징
- 딕셔너리의 value에는 모든 자료형을 혼합하여 사용할 수 있다.
- 딕셔너리의 key에는 숫자, 문자열, 부울형, 튜플을 사용할 수 있다.

# 딕셔너리 키는 자료를 구분하는데 사용되기 때문에 변경 못하고 중복을 배제
# 값에는 전부 가능
1.4 딕셔너리 값에 접근

#딕셔너리명.get(key, msg)
#존재하지 않는 key로 추출 시도해도 오류가 발생하지 않는다.
#존재하지 않는 key로 추출 시도할 경우 출력할 메시지를 설정할 수 있다.
person.get('몸무게','존재하지않음')
###'존재하지않음'
1.5 딕셔너리의 항목 추가/수정하기
scores = {'kor':100, 'eng':90, 'math':80}
# math점수 85점으로 수정하기
scores['math']=85
# music점수 95점 추가하기
scores[' music']=95
### {'kor': 100, 'eng': 90, 'math': 85, ' music': 95}
- setdefault
: 키가 존재하면 수정, 존재하지 않으면 추가
# setdefault로 항목 추가하기
# 딕셔너리명.setdefault(키,값)
# 이미 들어있는 키의 값은 수정할 수 없다.
scores = {'kor':100, 'eng':90, 'math':80}
# music점수 넣기(key만 넣고 value를 생략하면? value에 빈값)
scores.setdefault('music')
### {'kor': 100, 'eng': 90, 'math': 80, 'music': None}
scores = {'kor':100, 'eng':90, 'math':80}
# music점수 90점 추가
scores.setdefault('music',90)
###{'kor': 100, 'eng': 90, 'math': 80, 'music': 90}
scores = {'kor': 100, 'eng': 90, 'math': 80, 'music': 95}
# music점수 85점으로 수정
scores.setdefault('music',85)
###{'kor': 100, 'eng': 90, 'math': 80, 'music': 95}- update로 여러 항목 추가/수정하기
- 키가 존재하면 수정, 존재하지 않으면 추가된다
- 딕셔너리명.update(키1=값1, 키1=값2,...)
- 키에 따옴표를 하지 않지만, 딕셔너리에 들어갈 때는 따옴표가 붙어서 들어간다.
scores = {'kor':100, 'eng':90, 'math':80}
# math:90, music:90
scores.update(math=90, music=90)
###{'kor': 100, 'eng': 90, 'math': 90, 'music': 90}
- 딕셔너리명.update(zip(key리스트, value리스트)
scores = {'kor':100, 'eng':90, 'math':80}
# math:90, music:90
scores.update(zip(['math','music'],[90,90]))
###{'kor': 100, 'eng': 90, 'math': 90, 'music': 90}
- 딕셔너리명.update([(키1,값1),(키2,값2),...])
scores = {'kor':100, 'eng':90, 'math':80}
# math:90, music:90
scores.update([('math',90),('music',90)])
###{'kor': 100, 'eng': 90, 'math': 90, 'music': 90}
- 딕셔너리명.update({키1:값1,키2:값2,...,})
scores = {'kor':100, 'eng':90, 'math':80}
# math:90, music:90
scores.update({'math': 90, 'music': 90})
### {'kor': 100, 'eng': 90, 'math': 90, 'music': 90}
1.6 딕셔너리의 항목 삭제하기
- del 딕셔너리명[키]
- 해당 키의 항목 삭제
- 딕셔너리명.pop(키, 기본값)
- 해당 키의 항목(값) 반환하고 삭제
- 딕셔너리명.clear()
- 딕셔너리의 모든 항목 삭제
1.7 딕셔너리 키, 값 다루기
(1) 딕셔너리 키,값을 리스트 형태로 가져오기
- 딕셔너리명.keys()
- 딕셔너리의 키만 리스트로 가져오기
- dict_keys객체로 받아온다. 리스트처럼 사용할 수 있지만 리스트는 아니다.
- 딕셔너리명.values()
- 딕셔너리의 value만 리스트로 가져오기
- dict_values객체로 받아온다.
- 딕셔너리명.items()
- 딕셔너리의 (key,value) 쌍을 리스트로 가져오기
- dict_items객체로 받아온다.
(2) for문으로 딕셔너리 출력하기
- for문으로 딕셔너리의 key만 출력하기
scores = {'kor':100, 'eng':90, 'math':80}
# scores.keys는 dict.keys라는 객체이지만 시퀀스 형태이기 때문에 list처럼 사용할 수 있다!
for i in scores.keys():
print(i)
# 딕셔너리로 for문 돌리기
for i in scores:
print(i)
'''
kor
eng
math
'''
- for문으로 딕셔너리의 value만 출력하기
scores = {'kor':100, 'eng':90, 'math':80}
for i in scores.values():
print(i)
- for문으로 딕셔너리의 key, value만 출력하기
scores = {'kor':100, 'eng':90, 'math':80}
for i in scores.items():
print(i)
'''
('kor', 100)
('eng', 90)
('math', 80)
'''
for k,v in scores.items():
print(k,v)
'''
kor 100
eng 90
math 80
'''
(3) 딕셔너리 정렬하기
- sorted(dict.keys())
- sorted(dict.values())
- sorted(dict.items())
# .sort()는 지원하지 않음
- scores.keys().sort()
1.8 연습
- 영어단어장 만들기
엔터를 입력할 때까지 영어단어,뜻을 입력받아 단어장을 만들고, 입력이 끝나면 단어 테스트를 실시하는 프로그램을 만들어봅시다.
1) 단어장을 만듭니다.
2) 단어테스트를 실시하고 맞은 갯수를 계산합니다.
3) 테스트가 끝나면 맞은갯수/전체단어수/점수 형태로 결과를 출력합니다
1.1 단어장 만들기
엔터('')를 입력할 때까지 영어단어,뜻을 입력받아 딕셔너리에 저장
dict_word={}
while True:
input_word = input('영어단어,뜻:')
if input_word=='':
break
eng = input_word.split(',')[0]
kor = input_word.split(',')[1]
dict_word[eng] = kor
dict_word
'''
영어단어,뜻:apple,사과
영어단어,뜻:banana,바나나
영어단어,뜻:grapes,포도
영어단어,뜻:
{'apple': '사과', 'banana': '바나나', 'grapes': '포도'}
'''
1.2 단어테스트
단어장의 단어들을 모두 테스트
맞은 갯수는 별도로 카운트
cnt = 0
for eng, kor in dict_word.items():
answer = input(eng)
if answer==kor:
print('O')
cnt+=1
else:
print('X')
'''
apple사과
O
banana수박
X
grapes포도
O
'''
1.3 테스트 결과 출력
맞은갯수/전체문제수/점수 출력
print('맞은갯수:',cnt)
print('전체문제수:',len(dict_word))
print('점수:',round(cnt/len(dict_word)*100,1))
'''
맞은갯수: 2
전체문제수: 3
점수: 66.7
'''
2. 함수
2.1 함수란?
: 특정 기능을 구현하기 위한 코드의 묶음
2.2 함수 사용 목적
- 크고 복잡한 프로그램을 해결하기 쉬운 작은 단위로 쪼개어 해결한다.
- 반복되는 코드를 함수화하여 코드의 중복을 배제한다.
2.3 함수 사용의 효과
- 크고 복잡한 문제를 쉽게 해결할 수 있다.
- 코드의 가독성을 높여 프로그램의 흐름 파악이 용이하다.
- 자주 사용되는 코드를 하나의 함수로 만들어 프로그램 내에서 재사용할 수 있다.
- 프로그램의 디버깅이 용이하다.
2.4 함수의 종류

2.5 함수 정의 및 호출
# 함수 정의
def introduce():
print('안녕하세요!')
print('저의 이름은 파이썬입니다.')
# 함수 호출
introduce()# 함수 정의를 먼저 한 후 호출하도록 코드를 순차적으로 작성해야 한다.
# 코드는 위에서부터 아래로 순차적으로 실행된다.
# 함수를 호출하는 시점에 함수가 정의되어 있지 않으면 에러 발생
2.6 매개변수 전달하기
- 함수에서 값을 받는 부분 : 매개변수, 파라미터
def 함수명 (매개변수1, 매개변수2, ...):
- 함수 호출할 때 값을 전달하는 부분 : 인수, argument
함수명(인수1, 인수2,...)
def introduce(name, age):
print('안녕하세요!')
print('저의 이름은, '+name+'입니다.')
print('나이는, '+str(age)+'살입니다.')
introduce('파이썬',20)
introduce('홍길동',21)
'''
안녕하세요!
저의 이름은, 파이썬입니다.
나이는, 20살입니다.
안녕하세요!
저의 이름은, 홍길동입니다.
나이는, 21살입니다.
'''
연습
- 이름과 나이를 입력받아 생일축하 메시지를 출력하는 함수를 만들고 호출하세요.
- 생일문구 : ooo님의 oo번째 생일을 축하합니다!!
name = input('이름:')
age = input('나이:')
def happybirthday(name, age):
print(f'{name}님의 {age}번째 생일을 축하합니다.')
happybirthday(name,age)
'''
이름:파이썬
나이:20
파이썬님의 20번째 생일을 축하합니다.
'''
2.7 값 반환
- 여러개의 값 하나의 튜플로 묶어서 반환한다.
# 두 수를 매개변수로 받아 더한값과 뺀 값을 리턴하는 함수 만들기
def get_plus_minus(n1,n2):
return n1+n2, n1-n2
result = get_plus_minus(1,2)
result
plus,minus = get_plus_minus(1,2)
print(plus,minus)
###3 -1
2.8 함수에서 빠져나오기
- return을 만나면 함수를 빠져나온다.
- 반환할 값이 있다면 값을 반환하고 빠져나오고, 없다면 그냥 빠져나온다.
# 정수를 입력받아 0, 짝수, 홀수 여부를 리턴하는 함수 만들기
def is_odd_even(n):
if n == 0:
result=0
elif n%2==0:
result='짝수'
else:
result='홀수'
return result
is_odd_even(21)
###'홀수'
연습
- 소수 여부 판단하기 매개변수로 전달받은 수가 소수인지 아닌지 판별하는 함수를 작성하고 호출하세요.
- 소수란 : 1과 자기 자신으로만 나누어 떨어지는 1보다 큰 양의 정수
def is_prime(n):
if n <= 1:
return False
for i in range(2,n): #2부터 자신까지 for문 돌려서 나누기
if n % i == 0:
return '소수 아님'
return '소수임'
is_prime()
2.9 인수
- 인수
함수(인수, 인수, ...)
기본적인 인수 전달방법! 함수에 정의된 매개변수와 순서에 맞게 짝을 맞추어 인수를 전달한다.
- 디폴트 인수
def greet(name, msg='오랜만이야'):
print('안녕',name,msg)
greet('친구')
greet('친구', '반가워')안녕 친구 오랜만이야
안녕 친구 반가워함수를 정의할 때 매개변수에 디폴트값을 지정하면 디폴트값이 지정된 인수를 생략할 수 있다.
디폴트 인수는 기본 위치 인수를 다 적은 다음에 적어야 한다.
- 키워드 인수
def get_minus(x,y,z):
return x-y-z
print(get_minus(5,10,15))
print(get_minus(5,z=15,y=10))-20
-20함수를 호출할 때 인수의 이름을 명시하면, 순서를 바꾸어 전달할 수 있다.
- 가변인수
인수를 하나의 튜플이나 리스트로 전달한다.
# 가변적인 수를 하나의 리스트/튜플로 받아서 수의 평균을 리턴하는 함수
def average(args):
return sum(args)/len(args)
average([1,2,3])
average((1,2,3,4,5))3.0
매개변수에 '*'를 붙이면 여러개의 인수를 하나의 튜플로 받는다. (인수의 갯수가 가변적)
# 가변적인 수를 받아서 수의 평균을 리턴하는 함수
def average(*args):
# print(args)
return sum(args)/len(args)
average(1,2,3)
# 2.0
2.10 함수에서 변수 사용
- 전역변수
- 함수 밖에서 생성된 변수
- 함수 내에서도 사용할 수 있다.
- 지역변수
- 함수 내에서 생성된 변수
- 함수 내에서만 사용할 수 있다.
- 함수 안에서 전역변수 값 변경하기

- 함수 내에서 전역변수 값을 변경하려면 'global' 키워드를 함께 사용하여야 한다.
- global을 사용하지 않으면 동일한 이름의 지역변수가 생성되어 사용된다.
n1 = 1
n2 = 10
def get_plus_minus():
n1 = 2
plus = n1+n2
minus = n1-n2
return plus, minus
get_plus_minus()
n1
-->> 1
n1 = 1
n2 = 10
def get_plus_minus():
global n1
n1 = 2
plus = n1+n2
minus = n1-n2
return plus, minus
get_plus_minus()
n1
-->> 2
3. 람다 표현식과 map 함수
3.1 람다 표현식
- 매개변수와 수식으로 이루어진 함수!
lambda 매개변수1, 매개변수2, .... : 수식수식을 실행하고 그 결과를 반환한다.
다른 함수의 인수로 넣을 때 주로 사용
# 람다표현식으로 만들기
lambda n1,n2:n1+n2
# 람다표현식 사용하기
(lambda n1,n2:n1+n2)(1,2)
# 3# 람다표현식을 프로그램 내에서 재사용하고 싶다면, 람다표현식을 변수에 담아서 사용한다.
lambda_plus = lambda n1,n2:n1+n2
# 변수로 람다표현식 담아 호출하기
lambda_plus(1,2)
lambda_plus(3,5)8
3.2 map 함수
- map은 리스트나 튜플의 각 요소를 지정된 함수로 처리해주는 함수이다.
- 원본리스트를 변경하지 않고 새 리스트를 생성한다.
- list(map(함수, 리스트))
- tuple(map(함수, 튜플))
# map함수를 이용하여 리스트 a의 각 요소를 정수화 하여 새로운 리스트로 만들기
a = ['1', '2', '3', '4']
b = list(map(int,a))
print(a)
print(b)
# ['1', '2', '3', '4']
# [1, 2, 3, 4]
- map 함수에 람다표현식 사용하기
# 아래 리스트 l1에 1을 더한 l2 리스트 만들기
l1 = [1,2,3,4,5]
l2 = list(map((lambda x:x+1),l1))
print(l1)
print(l2)[1, 2, 3, 4, 5]
[2, 3, 4, 5, 6]
- 람다 표현식에 조건부 표현식 사용
- lambda 매개변수들 : 식1 if 조건식 else 식2
# 아래 리스트에서 짝수는 float로 바꾸고, 홀수는 str로 바꾸기
l1 = [1,2,3,4,5,6,7,8,9,10]
list(map((lambda x:float(x) if x%2==0 else str(x)),l1))
# 들어온 매개변수 x가 짝수라면 -> float(x)
# else -> str(x)['1', 2.0, '3', 4.0, '5', 6.0, '7', 8.0, '9', 10.0]
4. 클래스와 객체




1 . 자동차 클래스와 객체
- 3가지 속성과 3가지 기능이 있는 자동차 객체를 찍어내기 위한 틀을 만든다.
- 속성 : brand, model, color
- 기능 : turn_on, turn_off, drive
1.1 자동차클래스 만들기 (자동차라는 개별적인 각 객체 만들기 위한 )
class Car:
def __init__(self, b,m,c): # self는 객체 받는 매개변수! 인수에 포함 x
# 객체 속성 초기화, 이 객체의 b,m,c는 받아온 매개변수로 지정
self.brand = b
self.model = m
self.color = c
print(self.brand, self.model, self.color, '출고')
def turn_on(self):
print(self.brand, '시동을 겁니다.')
def turn_off(self):
print(self.brand, '시동을 끕니다.')
def drive(self):
print(self.brand, '주행중입니다.')
1.2 객체 생성하기
호출방법 : 객체명 = 클래스명(매개변수1,매개변수2,...)
car1 = Car('현대자동차','소나타','화이트')
car2 = Car('르노삼성','SM7','블랙')현대자동차 소나타 화이트 출고
르노삼성 SM7 블랙 출고
1.3 메소드 호출하기
- 객체명.메소드명(매개변수1,매개변수2,...)
# car1라는 객체의 동작
car1.turn_on()
car1.turn_off()
car1.drive()
# car2라는 객체의 동작
car2.turn_on()
car2.turn_off()
car2.drive()
- 객체 메소드 목록 조회
- dir(객체)
- 함수, 메소드 사용법
- help(함수명)
5. 모듈과 패키지
5.1 모듈 사용하기
- import 모듈명
- 모듈명.함수명( )
import myCalc
print(myCalc.get_plus(1,2))
print(myCalc.get_minus(1,2))
print(myCalc.get_multiply(1,2))
print(myCalc.get_division(1,2))
'''
3
-1
2
0.5
'''
5.2 모듈 별칭 사용하기
- import 모듈명 as 별칭
- 별칭.함수명()
import myCalc as calc
print(calc.get_plus(1,2))
print(calc.get_minus(1,2))
print(calc.get_multiply(1,2))
print(calc.get_division(1,2))
'''
3
-1
2
0.5
'''
5.3 모듈 이름 붙이지 않고 함수 사용하기
- from 모듈명 import 함수명1, 함수명2,...
from myCalc import get_plus, get_minus
print(get_plus(1,2))
print(get_minus(1,2))
print(myCalc.get_multiply(1,2))
'''
3
-1
2
'''
from myCalc import *
print(get_plus(1,2))
print(get_minus(1,2))
print(get_multiply(1,2))
print(get_division(1,2))
'''
3
-1
2
0.5
'''
5.4 파이썬 내장 모듈
- math
- 수학적 연산과 관련된 함수들을 모아놓은 모듈
- ceil : 올림하여 정수로 만들기
- floor : 내림하여 정수로 만들기
- sqrt : 제곱근
- factorial : 팩토리얼
- pi : 원주율
import math
print(math.ceil(1.4))
print(math.floor(1.7))
print(math.sqrt(4))
print(math.factorial(3))
print(math.pi)
'''
2
1
2.0
6
3.141592653589793
'''
- random
- 임의의 수를 발생시키거나 리스트의 요소 중 임의의 수를 선택하는 데 사용되는 모듈
랜덤 정수 구하기
- random.randint(시작값, 끝값) : 시작값~끝값 사이의 랜덤 정수 구하기 (끝값 포함)
- random.randrange(시작값, 끝값) : 시작값~끝값 사이의 랜덤 정수 구하기 (끝값 미포함)
- random.randrange(끝값) : 0~끝값 사이의 랜덤 정수 구하기 (끝값 미포함)
# 1~10 사이의 랜덤 정수 구하기(10포함)
print(random.randint(1,10))
# 1~9 사이의 랜덤 정수 구하기
print(random.randrange(1,10))
# 0~9 사이의 랜덤 정수 구하기
print(random.randrange(10))
'''
6
7
1
'''
랜덤 실수 구하기
- random.random() : 0~1 사이의 랜덤 실수 구하기
- random.uniform(시작값,끝값) : 시작값 ~ 끝값 사이의 랜덤 실수 반환(끝값 미포함)
# 0~1 사이의 랜덤 실수 구하기
print(random.random())
# 1~10 사이의 랜덤 실수 구하기
print(random.uniform(1,10))
'''
0.9558941639754068
2.5328923420483207
'''
시퀀스 데이터에서 무작위 요소 추출
- random.choice(시퀀스)
시퀀스 데이터에서 무작위로 n개 요소 추출
- random.sample(시퀀스,n)
시퀀스 데이터를 무작위로 랜덤하게 섞기
- random.shuffle(시퀀스) : 원본을 섞는다. 리턴값이 없다.
print(random.choice([1,2,3]))
print(random.choice('python'))
print(random.choice(range(1,101)))
'''
3
n
46
'''
print(random.sample([1,2,3],2))
print(random.sample('python',2))
print(random.sample(range(1,101),2))
'''
[1, 2]
['y', 'n']
[89, 7]
'''
a = [1,2,3,4,5]
random.shuffle(a)
a
# [2, 5, 1, 4, 3]
- datetime
- 날짜, 시간과 관련된 모듈.
- 날짜 형식을 만들 때 주로 사용된다.
현재 날짜와 시각 가져오기
- datetime.datetime.now()
현재 날짜와 시각 출력하기
print(now.year,'년')
print(now.month,'월')
print(now.day,'일')
print(now.hour,'시')
print(now.minute,'분')
print(now.second,'초')2021 년
9 월
24 일
14 시
16 분
46 초
시간을 포멧에 맞게 출력하기
- datetime.datetime.now().strftime(포멧)
now.strftime('%Y.%m.%d %H:%M:%S')
#'2021.09.24 14:16:46'
특정 시간 이후의 날짜와 시간 구하기
- datetime.datetime.now()+datetime.timedelta(더할시간) : 특정 일, 시간, 분, 초 이후의 날짜와 시간 구하기
- timedelta에는 year로 계산하는 기능은 없음
now + datetime.timedelta(weeks=1, days=1, hours=1, minutes=1, seconds=1)
# datetime.datetime(2021, 10, 2, 15, 17, 47, 299163)
# 현재로부터 100일 이후의 날짜와 시간 구하기
now + datetime.timedelta(days=100)
# datetime.datetime(2022, 1, 2, 14, 16, 46, 299163)
# 현재로부터 100일 전의 날짜와 시간 구하기
now + datetime.timedelta(days=-100)
# datetime.datetime(2021, 6, 16, 14, 16, 46, 299163)
- time
- 시간 데이터를 다루기 위한 모듈
현재 날짜와 시간 가져오기
- time.localtime()
- time.ctime()
time.localtime().tm_year
time.localtime().tm_mon
time.localtime().tm_mday
time.localtime().tm_hour
time.localtime().tm_min
# 25
time.ctime()
#'Fri Sep 24 14:25:33 2021'
일시정지
- time.sleep(초)
모듈 살펴보기
- 모듈 내 함수 확인
- dir(모듈명)
- 모듈 내 함수 사용법 확인
- import 모듈명
help(모듈명.함수명)
- 외부 모듈
- 외부모듈 설치하기 : pip install 모듈명
- 설치된 외부모듈 확인하기 : pip list
6. 판다스


6.1 데이터프레임 만들기
- 데이터프레임 : 엑셀의 시트(sheet)와 동일한 개념이다. (2차원 표 형태)

인덱스 : list에서는 항목의 순서 나타내는 값, df,series에서 인덱스는 데이터에 이름을 붙이는 것
- 리스트로 만들기
pd.DataFrame(2차원리스트, columns=컬럼리스트, index=인덱스리스트)
- 행 단위로 데이터프레임이 생성된다.
- 컬럼, 인덱스를 지정하지 않으면 디폴트로 0부터 시작하는 숫자가 지정된다.
df = pd.DataFrame(
[['james',30,'programmer'],
['amy',20,'student'],
['david',25,'designer']],
columns=['name','age','job'],
index=['a','b','c']
)
df
'''
name age job
a james 30 programmer
b amy 20 student
c david 25 designer
'''
- 딕셔너리로 만들기
pd.DataFrame(딕셔너리, index=인덱스리스트)
- 딕셔너리는 {컬럼명1:컬럼값리스트, 컬럼명2:컬럼값리스트...}
- 컬럼 단위로 데이터프레임이 생성된다.
- 딕셔너리의 키가 컬럼명이 된다.
- 인덱스를 지정하지 않으면 디폴트로 0부터 시작하는 숫자가 지정된다.
{'name':['james','amy','david'],
'age':[30,20,25],
'job':['programmer','student','designer']
}
df = pd.DataFrame(
{'name':['james','amy','david'],
'age':[30,20,25],
'job':['programmer','student','designer']
},
index=['a','b','c']
)
df
'''
name age job
a james 30 programmer
b amy 20 student
c david 25 designer
'''
- csv 파일에서 데이터를 읽어와 만들기
pd.read_csv(파일경로)
- csv파일은 utf-8 형식이어야 한다.
6.2 데이터 일부 미리보기
- head(n) : 가장 위 n개 행
- tail(n) : 가장 뒤 n개 행
- sample(n) : 랜덤 n개 행 (비율로 보려면 frac=비율(0.n))
- nlargest(갯수,컬럼명) : 높은 순 보기 (컬럼의 데이터가 숫자형일 때 사용할 수 있다.)
- nsmallest(갯수,컬럼명) : 낮은 순 보기 (컬럼의 데이터가 숫자형일 때 사용할 수 있다.)
6.3 데이터 요약보기
- shape : 행,열 크기 보기
- len(데이터프레임) : 데이터 갯수 보기
- columns : 컬럼명 보기
- index : 인덱스 보기
- dtypes : 데이터 자료형 보기 (판다스에서는 문자열의 데이터타입이 object)
- info() : 데이터프레임 정보 보기 (데이터프레임의 총 샘플 갯수, 컬럼 수, 컬럼 별 정보 등)
- 컬럼.unique() : 컬럼의 유니크한 데이터 뽑기 (개수는 nuique)
- 컬럼.value_counts() : 컬럼의 유니크한 값의 갯수
- describe() : 요약통계 보기
7. 시리즈
7.1 시리즈 만들기
시리즈 : 엑셀시트의 열 1개를 의미한다.(1차원 리스트형태)
만들기 : pd.Series(리스트)
# 시리즈 만들기
s = pd.Series(['amy',170,240])
s.index
s
# 문자열 숫자 섞여 있으면 -> dtype은 object로 찍힌다
'''
0 amy
1 170
2 240
dtype: object
'''
7.2 시리즈의 index와 value 가져오기
- 시리즈에는 index와 value가 있다.
- 시리즈의 index 가져오기 : 시리즈.index
- 시리즈의 value 가져오기 : 시리즈.values
- 시리즈의 인덱스는 리스트의 인덱스와 다른 개념이다.
시리즌의 인덱스는 데이터의 이름이고, 행번호는 따로 있다.
7.3 시리즈의 index 지정하기
시리즈.index = 인덱스리스트
- 시리즈의 인덱는 숫자, 문자열 모두 가능하다.
7.4 시리즈의 통계값 사용하기
- 평균 : 시리즈.mean()
- 최소값 : 시리즈.min()
- 최대값 : 시리즈.max()
- 중간값 : 시리즈.median()
- 표준편차 : 시리즈.std()
- 요약통계 : 시리즈.describe()
>>> 시리즈의 통계값은 시리즈의 value가 모두 숫자형일 때 사용할 수 있다.
s2 = pd.Series([10,20,30,40,50])
print('평균:',s2.mean())
print('최소값:',s2.min())
print('최대값:',s2.max())
print('중간값:',s2.median())
print('표준편차:',s2.std())
'''
평균: 30.0
최소값: 10
최대값: 50
중간값: 30.0
표준편차: 15.811388300841896
'''
7.5 시리즈 주요 메서드
- 시리즈.sort_values( ) : 값 정렬 (디폴트는 오름차순 : ascending=True, 내림차순 : ascending=False)
- 시리즈.sort_index( ) : 인덱스 정렬
- 시리즈.reset_index( ) : 인덱스 리셋 : --> 행번호로 인덱스 재지정
- replace(찾을값, 교체할값) : 특정 값을 가진 시리즈 값을 교체
- 시리즈.to_frame( ) : 시리즈를 데이터프레임으로 변환
# s3의 value 중 10을 5로 교체
s3 = s3.replace(10,5)
s3
'''
0 1
1 3
2 2
3 4
4 5
dtype: int64
'''
# s3 정렬 (디폴트는 오름차순 : ascending=True)
s3.sort_values()
'''
0 1
2 2
1 3
3 4
4 5
dtype: int64
'''
#정렬
s3.sort_values(ascending=False)
'''
4 5
3 4
1 3
2 2
0 1
dtype: int64
'''
# s3을 데이터프레임으로 만들기
s3.to_frame()
'''
0
0 1
1 3
2 2
3 4
4 5
'''
# 시리즈 인덱스 새로 만들기
s.reset_index()
'''
index 0
0 name amy
1 height 170
2 footsize 240
'''
8. 컬럼명으로 데이터 추출하기
8.1 시리즈 형태로 추출하기
- 데이터프레임명['컬럼명'] / 데이터프레임명["컬럼명"]
: 컬럼명은 1개만 지정할 수 있으며 대괄호 1개를 사용한다. - 데이터프레임명.컬럼명
: 컬럼명에 공백이나 특수문자가 섞여있을 때는 사용할 수 없다.
8.2 데이터프레임 형태로 추출하기
- 데이터프레임명[컬럼명리스트]
- 대괄호안에 컬럼리스트가 들어간다.(대괄호 2개로 표현되어야한다.)
# 'name','kor' 컬럼 데이터 추출하기
df_name_kor = df[['name','kor']]
df_name_kor.head(3)
'''
name kor
0 Aiden 100.0
1 Charles 90.0
2 Danial 95.0
'''
# 'math' 컬럼을 데이터프레임 형태로 추출하기
df_math = df[['math']]
df_math
'''
math
0 95.0
1 75.0
2 100.0
3 100.0
4 60.0
'''
8.3 조건에 따라 데이터 추출하기
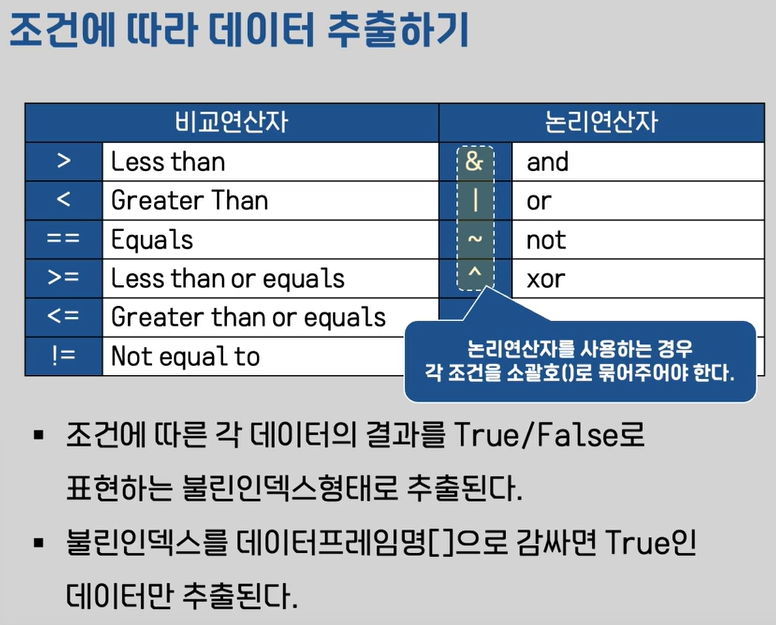
(1) 조건의 결과에 따른 boolean index 추출
- 조건식의 결과에 따른 결과가 boolean index로 만들어진다.
- boolean index를 데이터프레임명[ ]으로 감싸주면 True인 데이터만 추출된다.
# kor 점수가 100점인 데이터 불린인덱스
df['kor']==100
'''
0 True
1 False
2 False
3 True
4 False
5 False
6 False
~
'''
df[df['kor']==100]
'''
name kor eng math
0 Aiden 100.0 90.0 95.0
3 Evan 100.0 100.0 100.0
9 Kevin 100.0 100.0 90.0
12 Peter 100.0 95.0 100.0
'''
(2) 여러 조건
- 논리연산자는 '&' , '|' ,'~', '^' 기호를 사용한다.
- 논리연산자를 사용할 때에는 각 조건을 ()로 감싼다.
# 한 과목이라도 100을 받은 학생 추출
df[(df.kor==100)|(df.eng==100)|(df.math==100)]
'''
name kor eng math
0 Aiden 100.0 90.0 95.0
2 Danial 95.0 100.0 100.0
3 Evan 100.0 100.0 100.0
~~~
'''
# kor의 값이 60~90인 학생의 name, kor 추출
df[(df['kor']>=60)&(df['kor']<=90)][['name','kor']]
'''
name kor
1 Charles 90.0
5 Ian 90.0
6 James 70.0
~~~~
'''(3) 특정 값을 가진 데이터만 추출
- 컬럼.isin(값리스트)
# 이름이 Amy인 데이터 추출
df[df['name'].isin(['Amy'])]
'''
name kor eng math
13 Amy 90.0 75.0 90.0
'''
# 이름이 Amy, Rose인 데이터 추출
df[df['name'].isin(['Amy','Rose'])]
'''
name kor eng math
13 Amy 90.0 75.0 90.0
22 Rose 70.0 65.0 70.0
'''
# kor이 50,100 데이터 추출
df[df['kor'].isin([50,100])]
'''
name kor eng math
0 Aiden 100.0 90.0 95.0
3 Evan 100.0 100.0 100.0
8 Justin 50.0 60.0 100.0
'''
(4) null 여부에 따른 데이터 추출
- 컬럼.isnull() --> 해당 컬럼의 값이 null인 데이터 추출
- 컬럼.notnull() --> 해당 컬럼의 값이 null이 아닌 데이터 추출
# kor이 null인 데이터 추출
df[df.kor.isnull()]
'''
name kor eng math
4 Henry NaN 35.0 60.0
16 Ellen NaN 60.0 NaN
27 Vikkie NaN 50.0 100.0
'''
# kor이 null이 아닌 데이터 추출
df[df.kor.notnull()]
'''
name kor eng math
0 Aiden 100.0 90.0 95.0
1 Charles 90.0 80.0 75.0
2 Danial 95.0 100.0 100.0
3 Evan 100.0 100.0 100.0
'''
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] 데이터 시각화 #2 (230213) (0) | 2023.02.13 |
|---|---|
| [STARTERS 4기 TIL] 데이터 시각화 (230210) (0) | 2023.02.10 |
| [STARTERS 4기 TIL] 공공 데이터 분석 (230209) (0) | 2023.02.09 |
| [STARTERS 4기 TIL] 파이썬 전처리 베이스 (230208) (0) | 2023.02.08 |
| [STARTERS 4기 TIL] 파이썬 기초 (230206) (0) | 2023.02.07 |



