
ilovechoonsik
[STARTERS 4기 TIL] Tableau 기초 #1 (230228) 본문

📖 오늘 내가 배운 것
1. 태블로 인터페이스 및 막대 차트 그리기
2. 시계열 데이터 활용, 어그리게이션 및 필터
3. 지도, 산점도, 대시보드
4. 조인 및 블렌딩
5. 관계 작업
6. 요약
1. 태블로 사용법 및 막대 차트 그리기!
1.1 데이터 다운로드 후 import
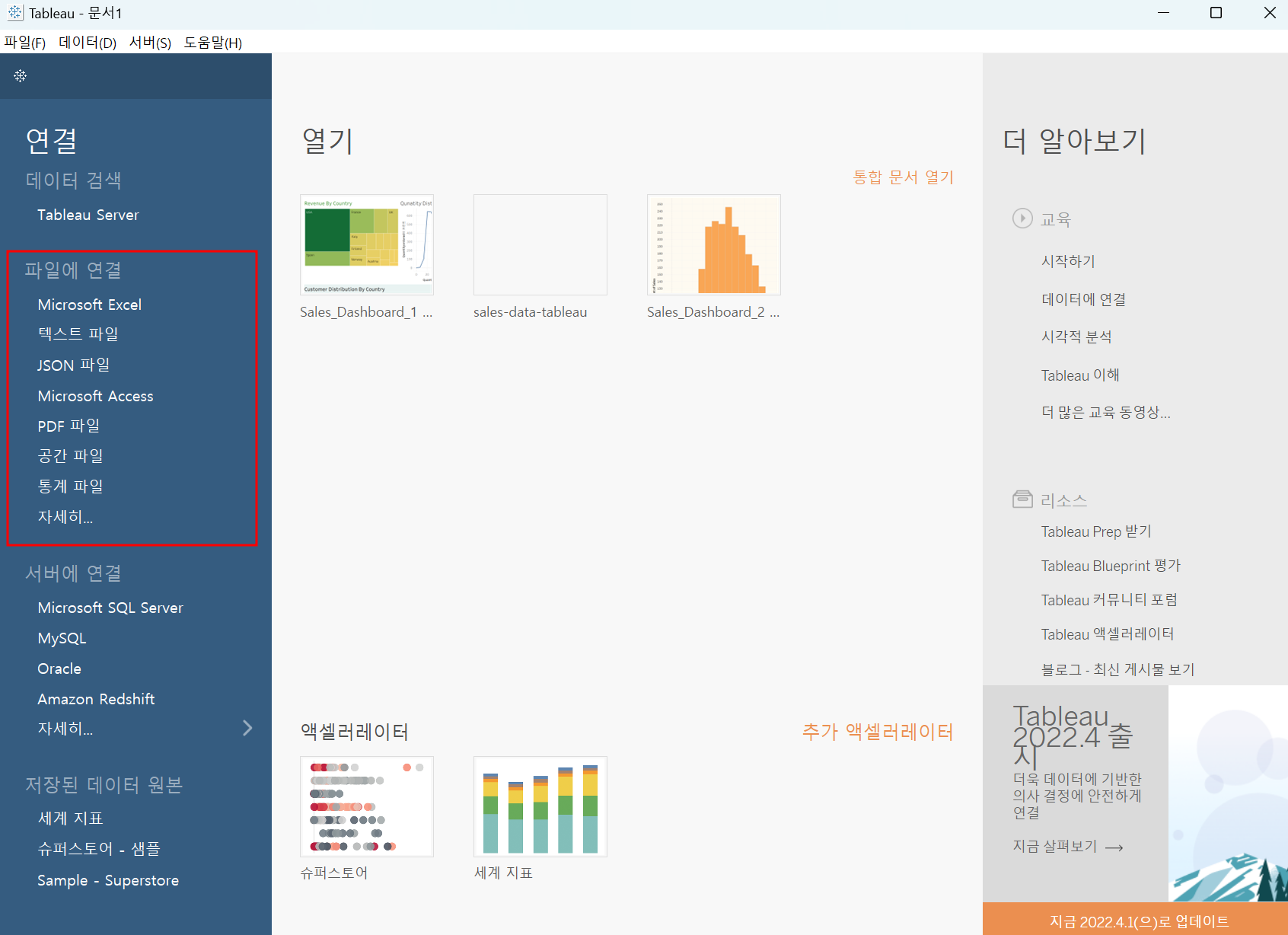
좌 : csv 파일은 comma로 구분된 텍스트로 되어 있기 때문에 사실상 텍스트 파일
우 : 좌측 파일 부분은 이전에 선택한 확장자 파일이 들어있는 폴더! 같은 확장자 파일이 전부 표시되고 여러 개 가져와서 join도 할 수 있음!
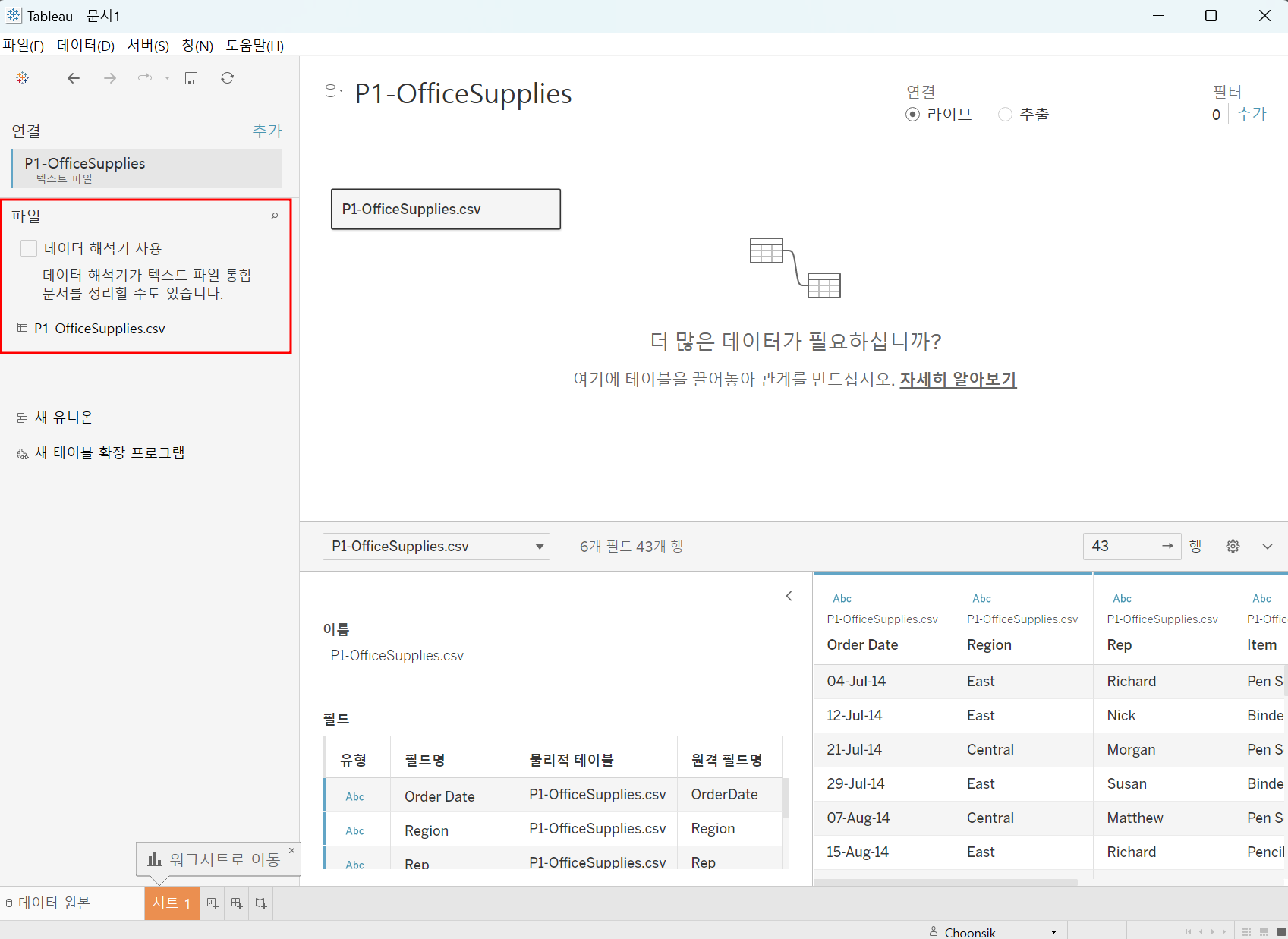
좌측 하단의 데이터 원복-시트 옮겨 다니며 작업할 수 있고
새로운 데이터를 불러오고 싶다면 좌측 상단 데이터 - 데이터 불러오기 선택하면 됨
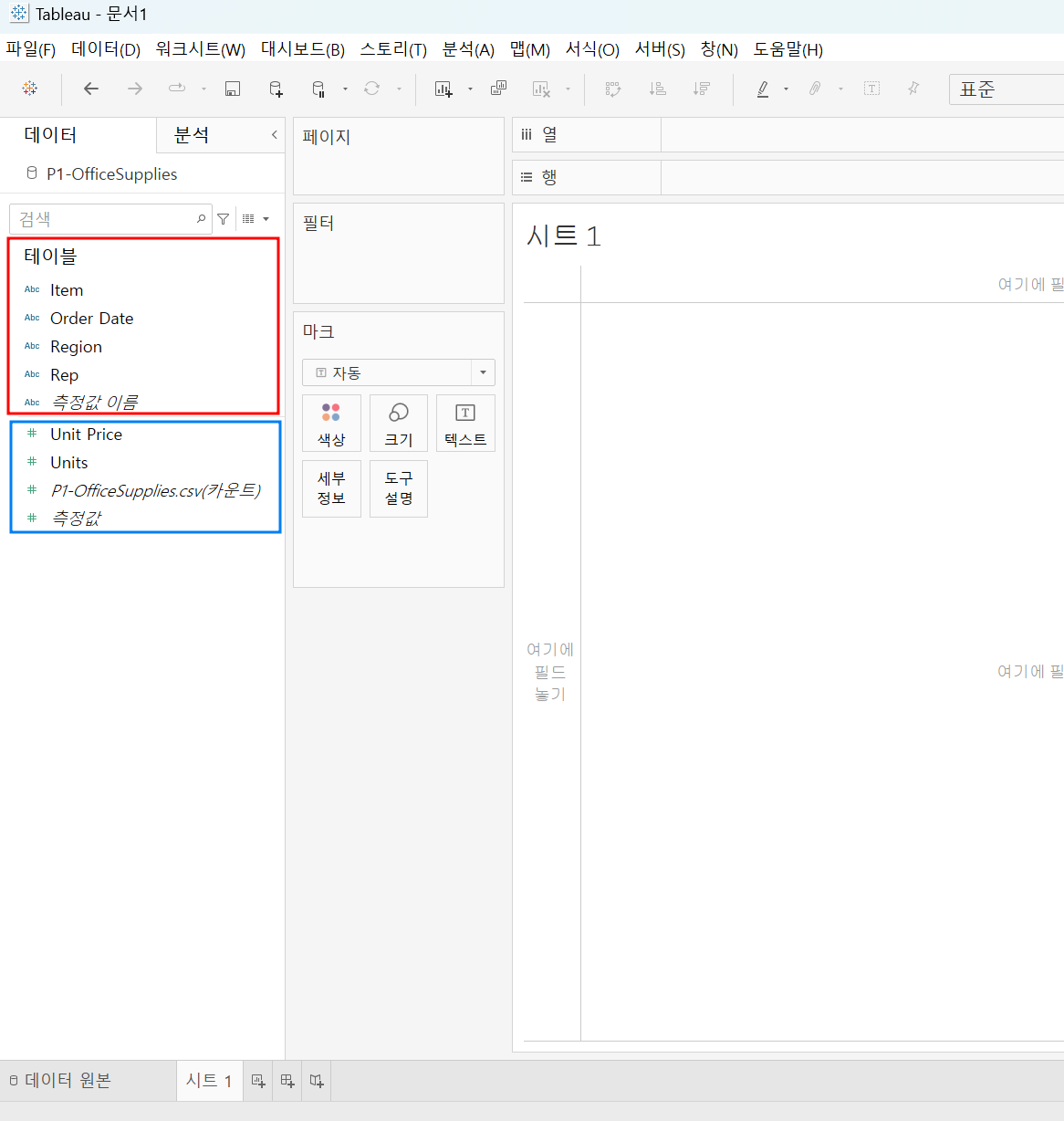
작업공간인 시트로 넘어가 좌측 데이터 요소를 보면
차원(dismension), 값(measure)으로 나눠져 있는 것을 확인할 수 있다!
요 친구들은 데이터 요소 내에서 서로 다른 역할을 가짐
보통 태블로는 값을 두 개 이상의 치수에 넣어서 이들을 카테고리화시키는 방식
| 차원 | 값 |
| 독립적인 변수 | 종속적인 변수 |
| ex. 지역 별로 특정한 아이템이 얼마나 많은 유닛으로 판매된 건지 확인하려면? 차원과 값은? | |
| 지역 | 유닛 |
이러한 정의를 바탕으로 값 <-> 치수 이동시키며 사용할 수도 있음
파일 : 파일 저장, 새 파일 열거나
데이터 : 데이터 가져오기
워크시트 : 작업공간 다룰 수 있음
대시보드 : 워크시트 조합
스토리 : 워크시트, 대시보드의 조합
분석 : 작업공간에서 어떻게 분석하고 싶은지 설정
맵 : 지도 작업
서식 : 나중에
서버 : 나중에
창 : 보조적 기능
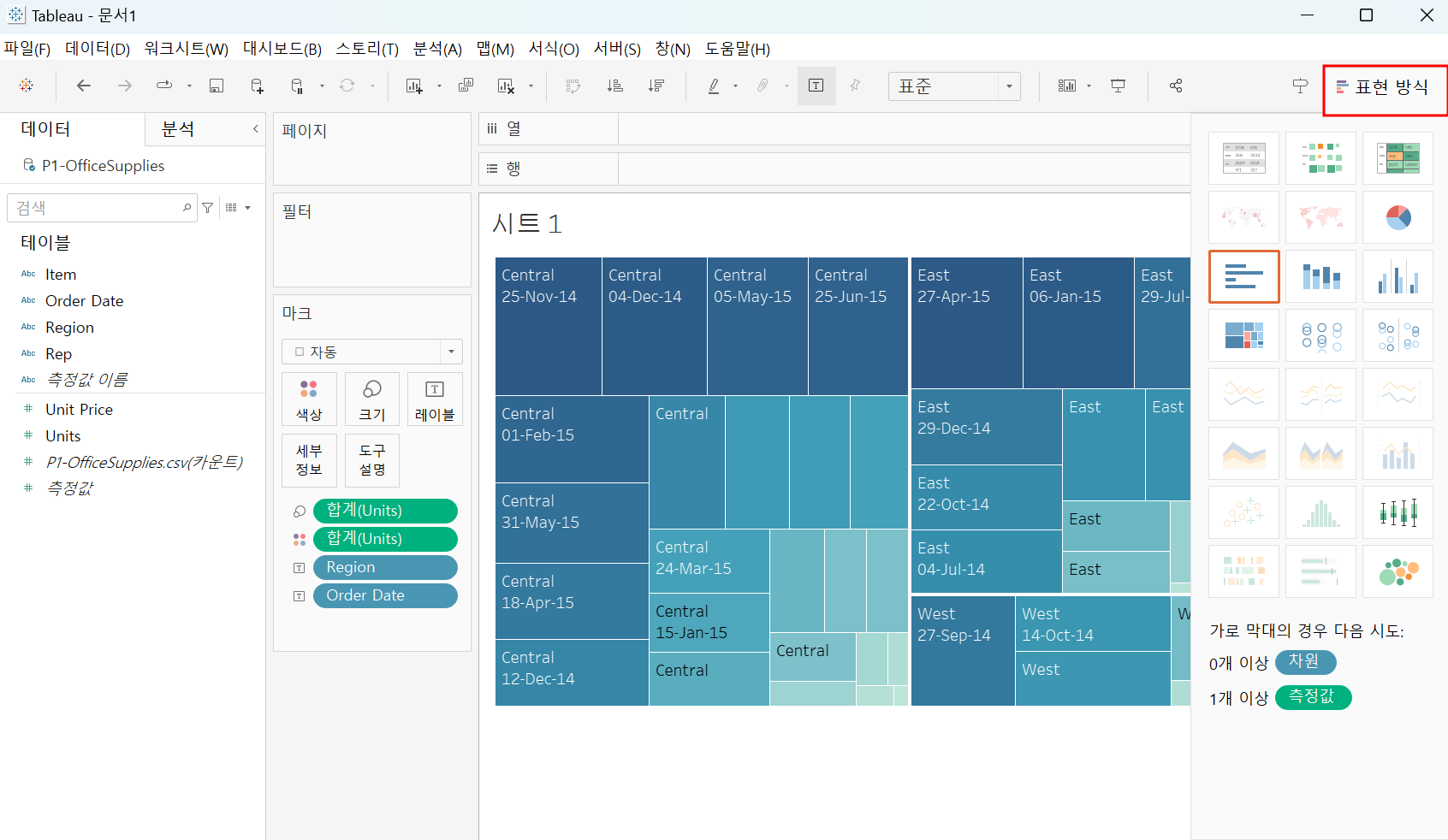
우측 상단 표현 방식에 다양한 그래프 형식을 선택할 수 있음.
1.1 값(계산된 필드) 생성 및 정렬
이제 본격적으로 가장 높은 값을 찾기 위해 열에 지역, 판매원을 두고
행에 그들이 얼마나 많이 팔았는지 Units를 넣어준다.
정렬은 시트 좌측 누르면 알아서 해줌
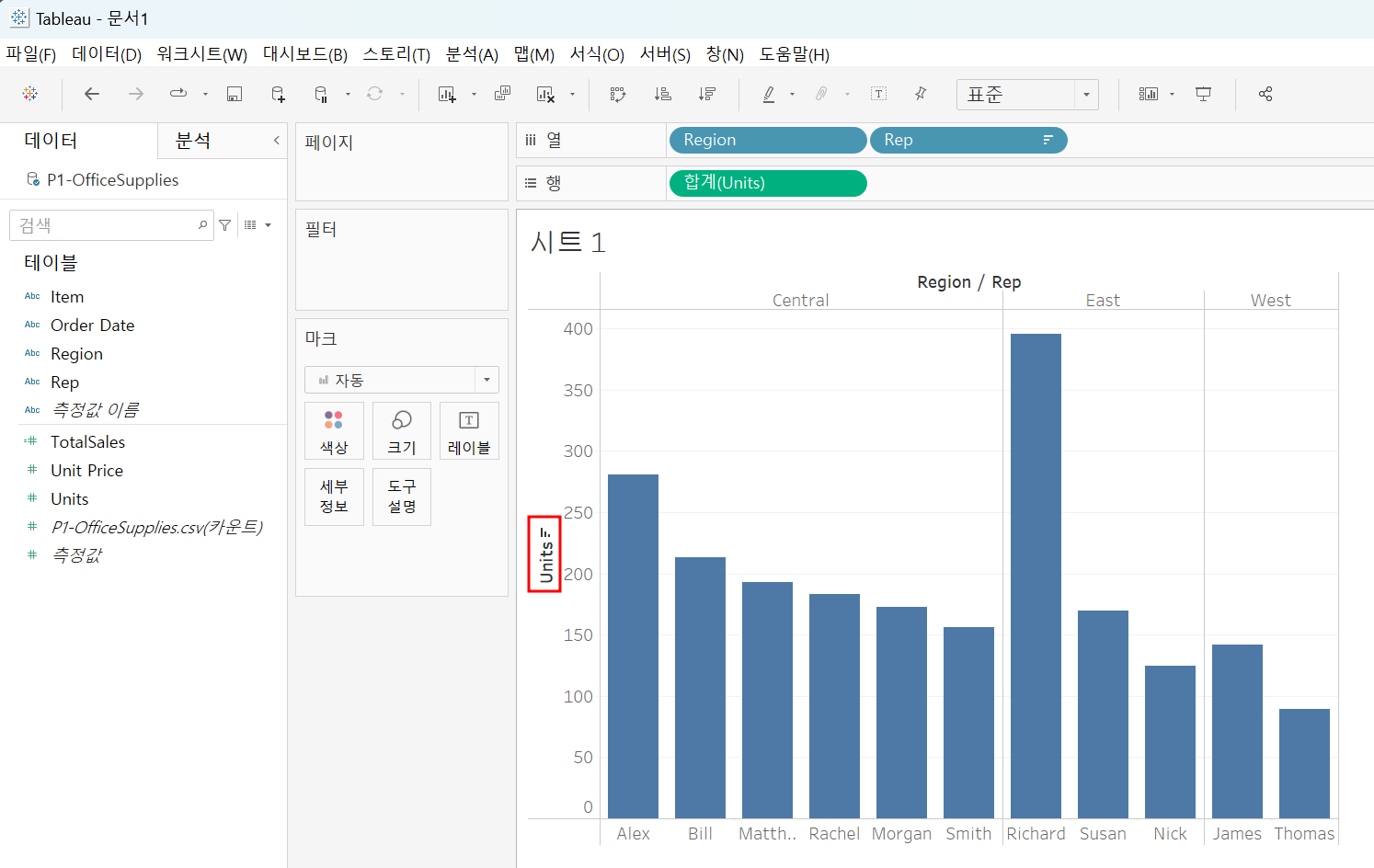
근데 여기서의 판매 순위는 각각 판매한 금액을 고려하지 않고 판매 수량만 고려한 것이기 때문에
해당 부분을 고려하여 값을 넣어줘야 하는데 지금 좌측에 보면 없다!!

좌측의 [값] 필드 우클릭 후 [계산된 필드 만들기] 선택하면 위와 같이 직접 값을 만들어줄 수 있음!
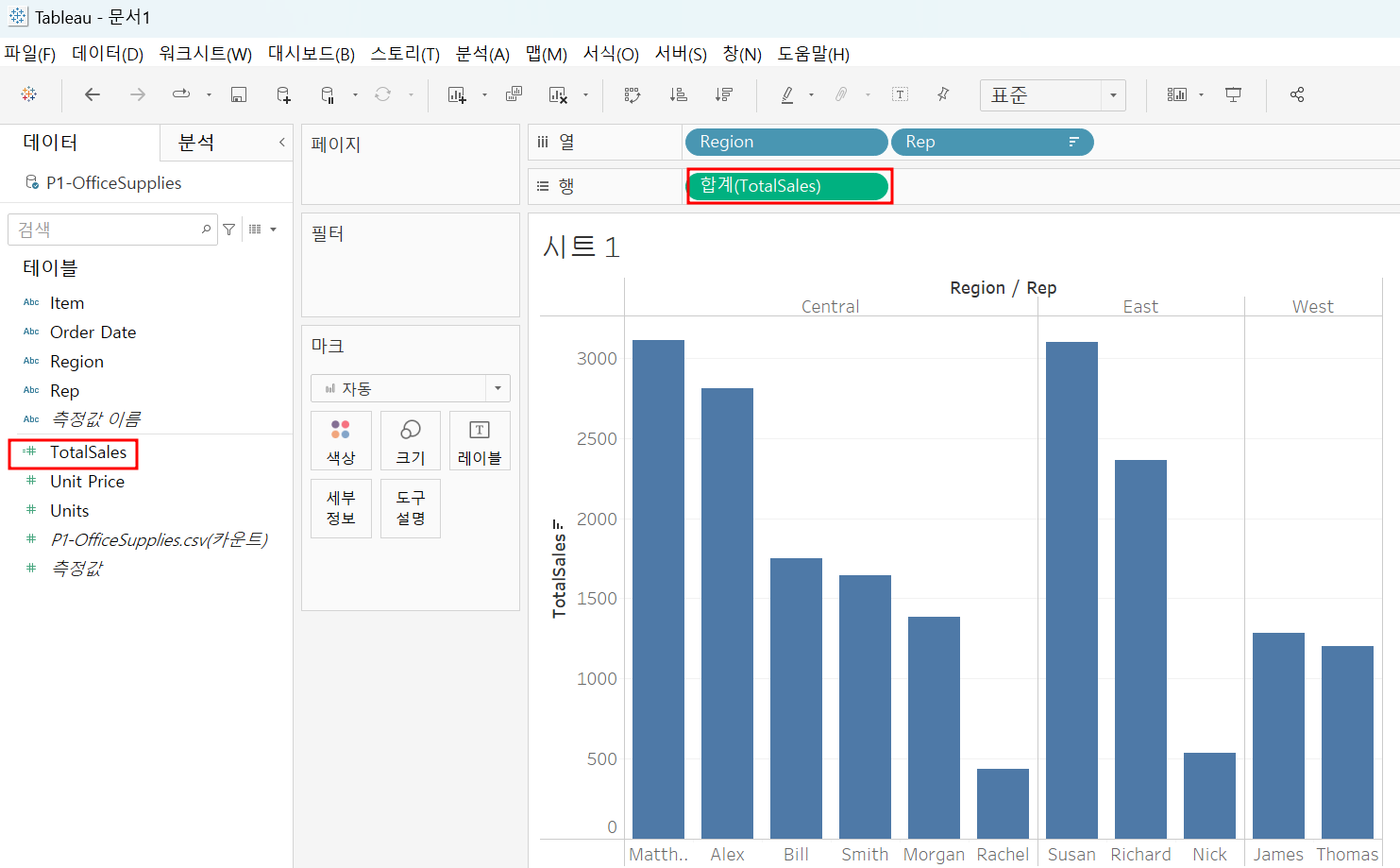
새롭게 추가한 값을 통해 정렬해보니 아까와 다른 결과!
1.2 색상
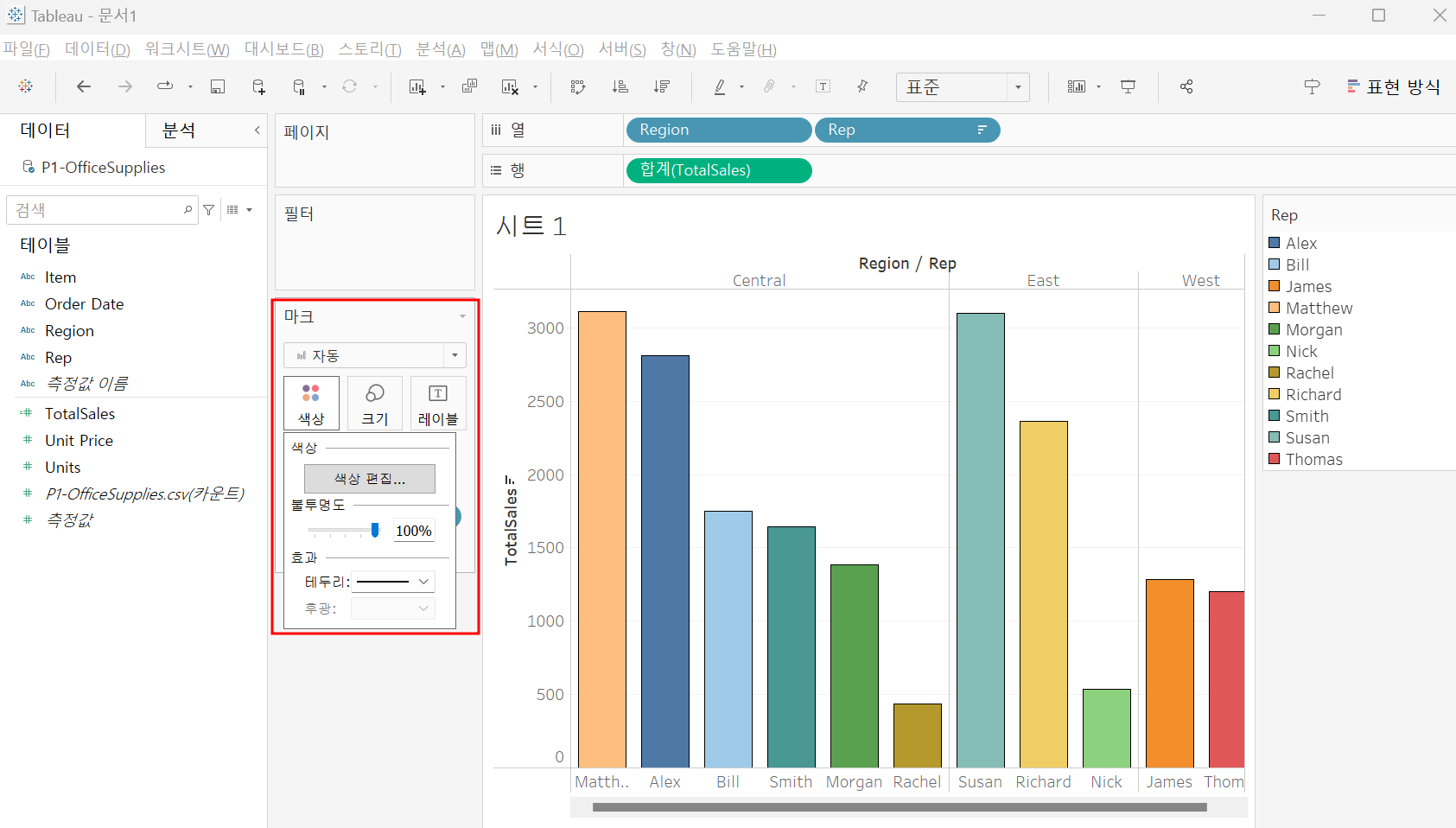
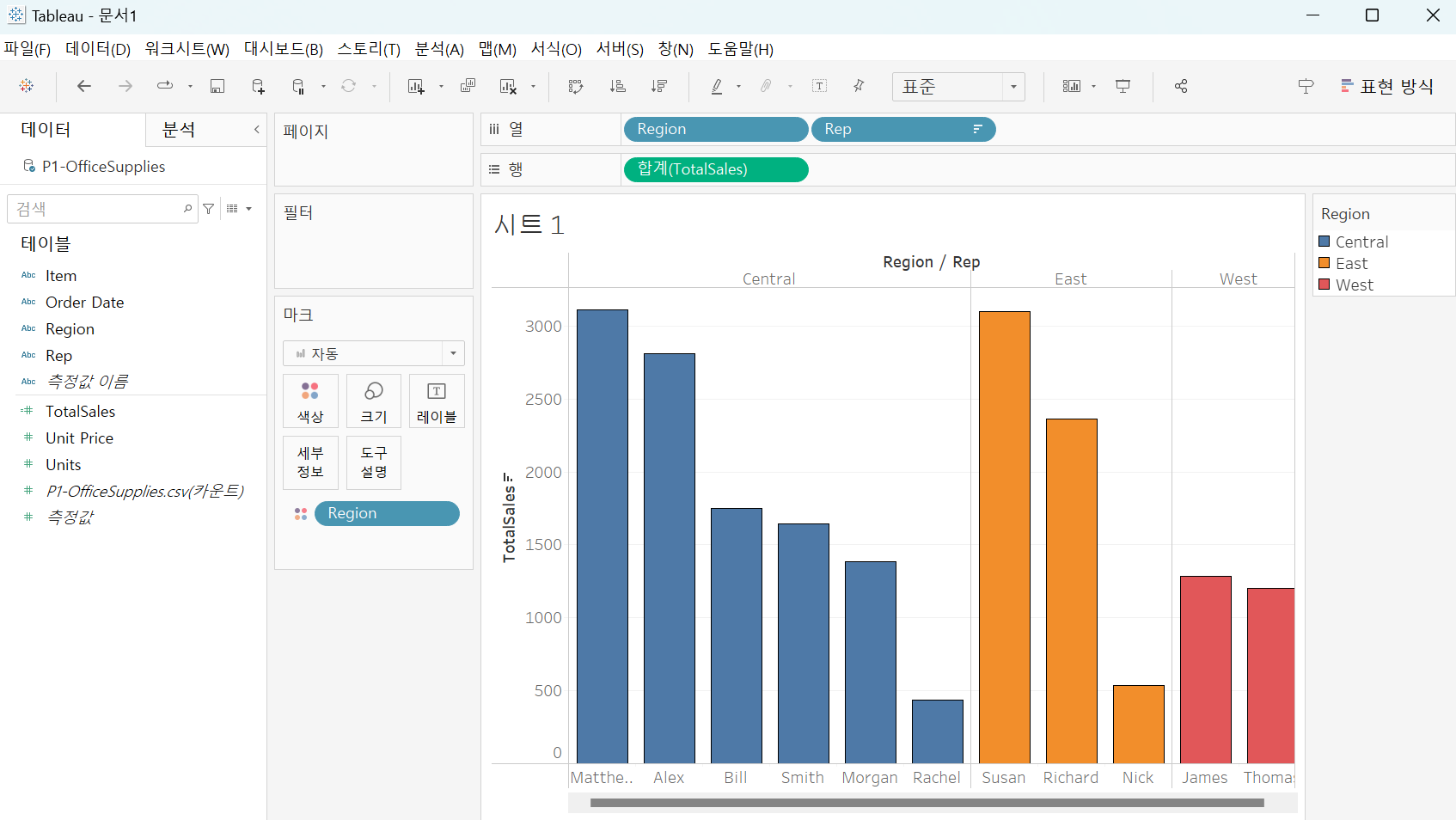
사람들 간의 데이터 크기 비교는 이미 바의 크기로 확인할 수 있으니
지역을 색상에 넣어서 지역 별로 구분
1.3 라벨과 서식 설정
(1) 라벨
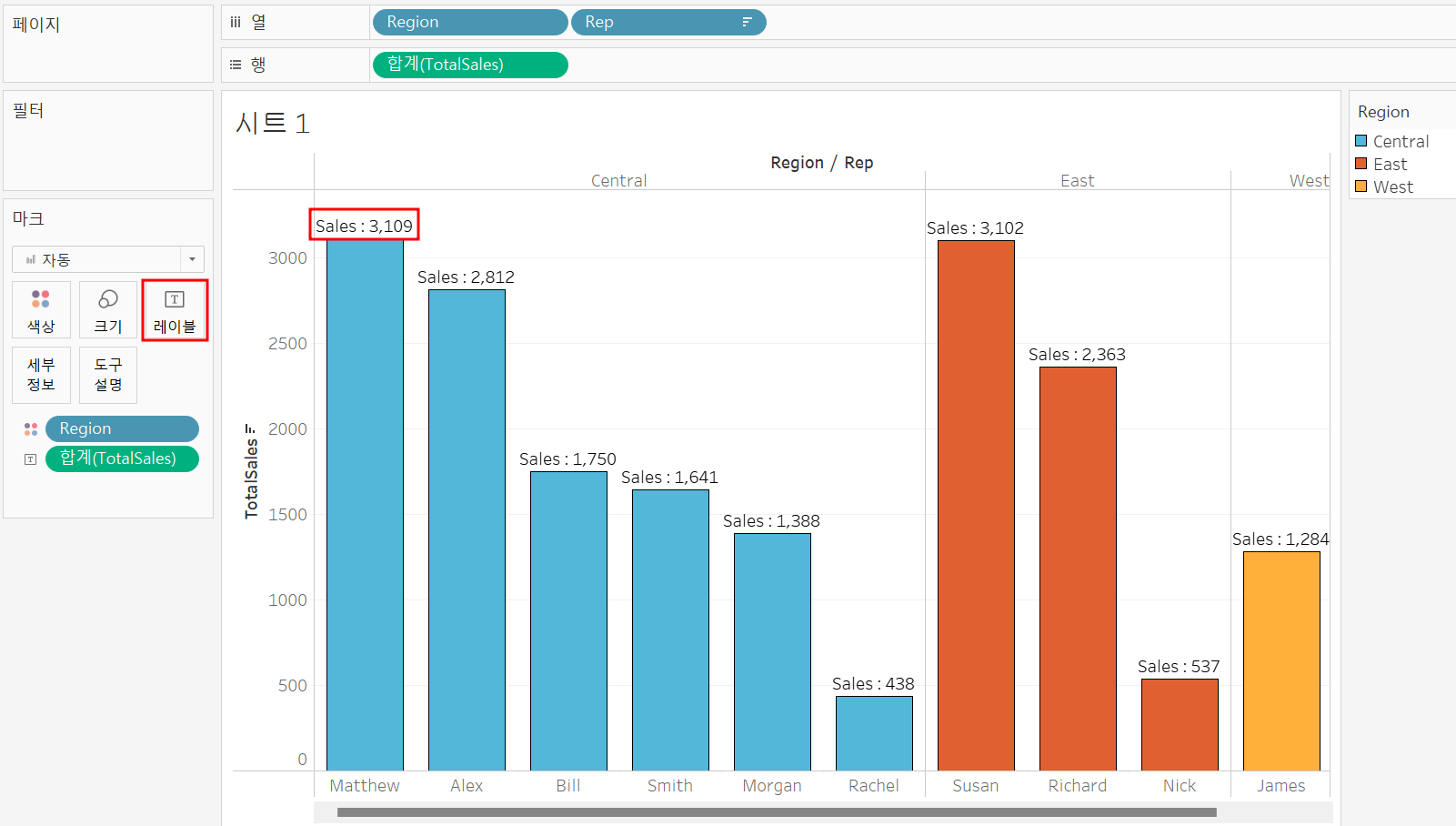
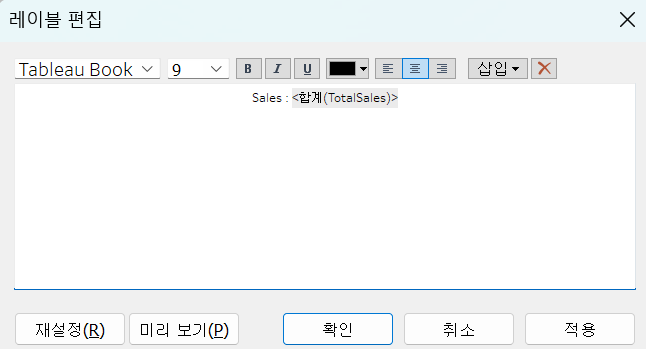
차트에 텍스트 형식의 정보를 입력하는데 사용!
세부 설정의 편집 기능을 이용하면 원하는 text를 넣을 수 있음
혹시 글자가 너무 길어서 표현이 안 되는 경우/
해당 막대 [우클릭] - [마크 레이블] - [항상 표시]
(2) 서식
라벨 [우클릭] - [서식]
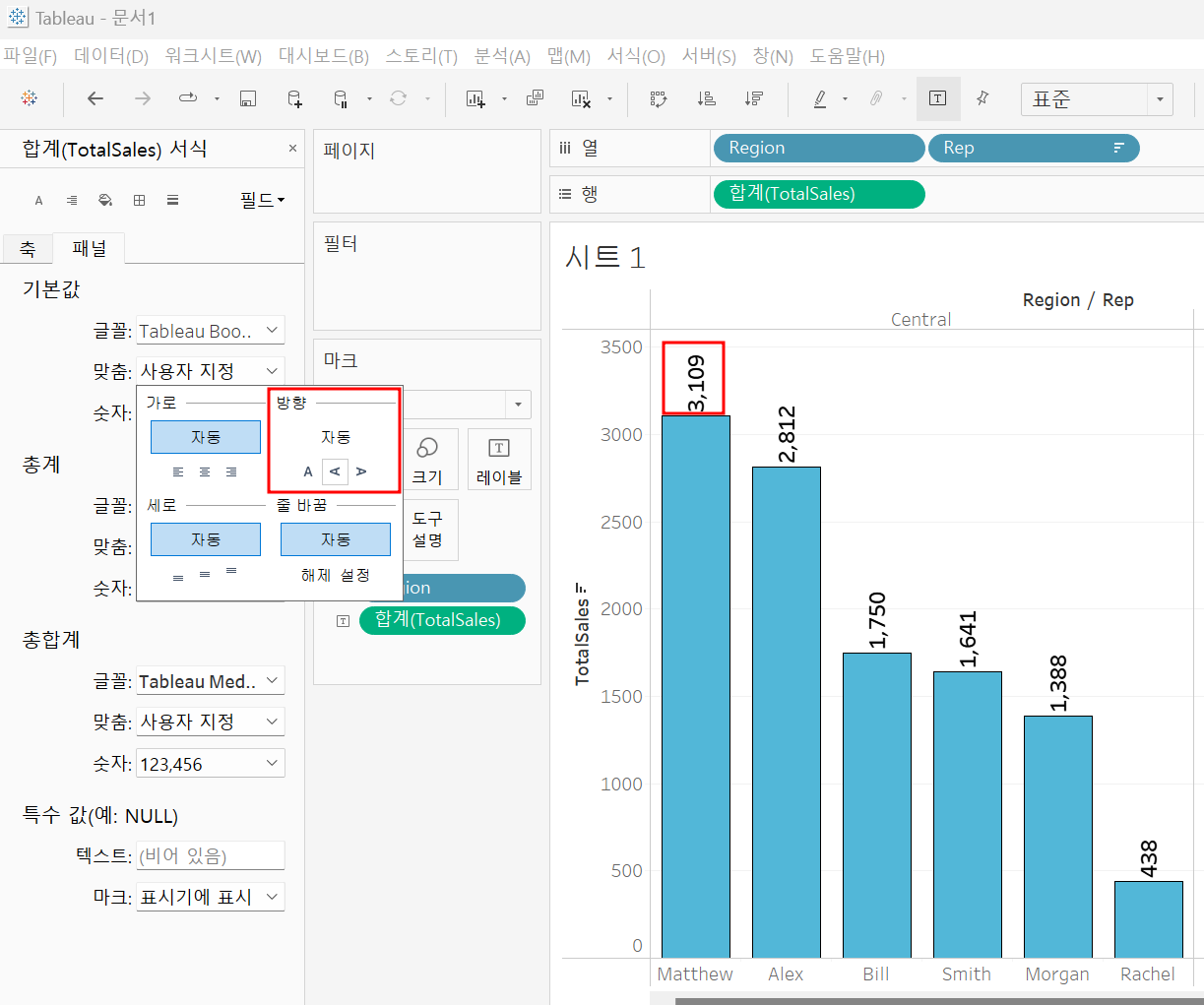
라벨 설정의 기능과 동일! but 숫자의 타입을 지정할 수 있다.
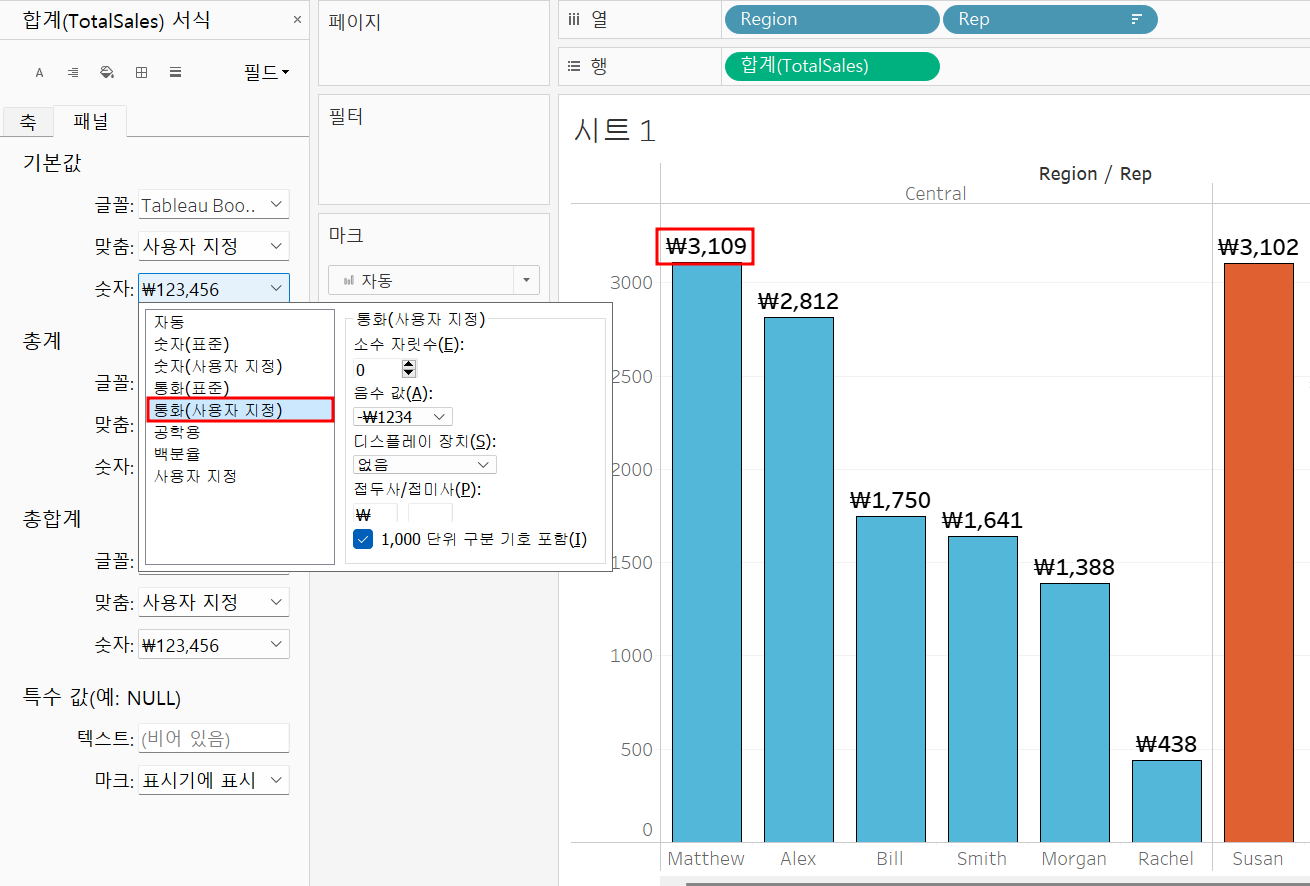
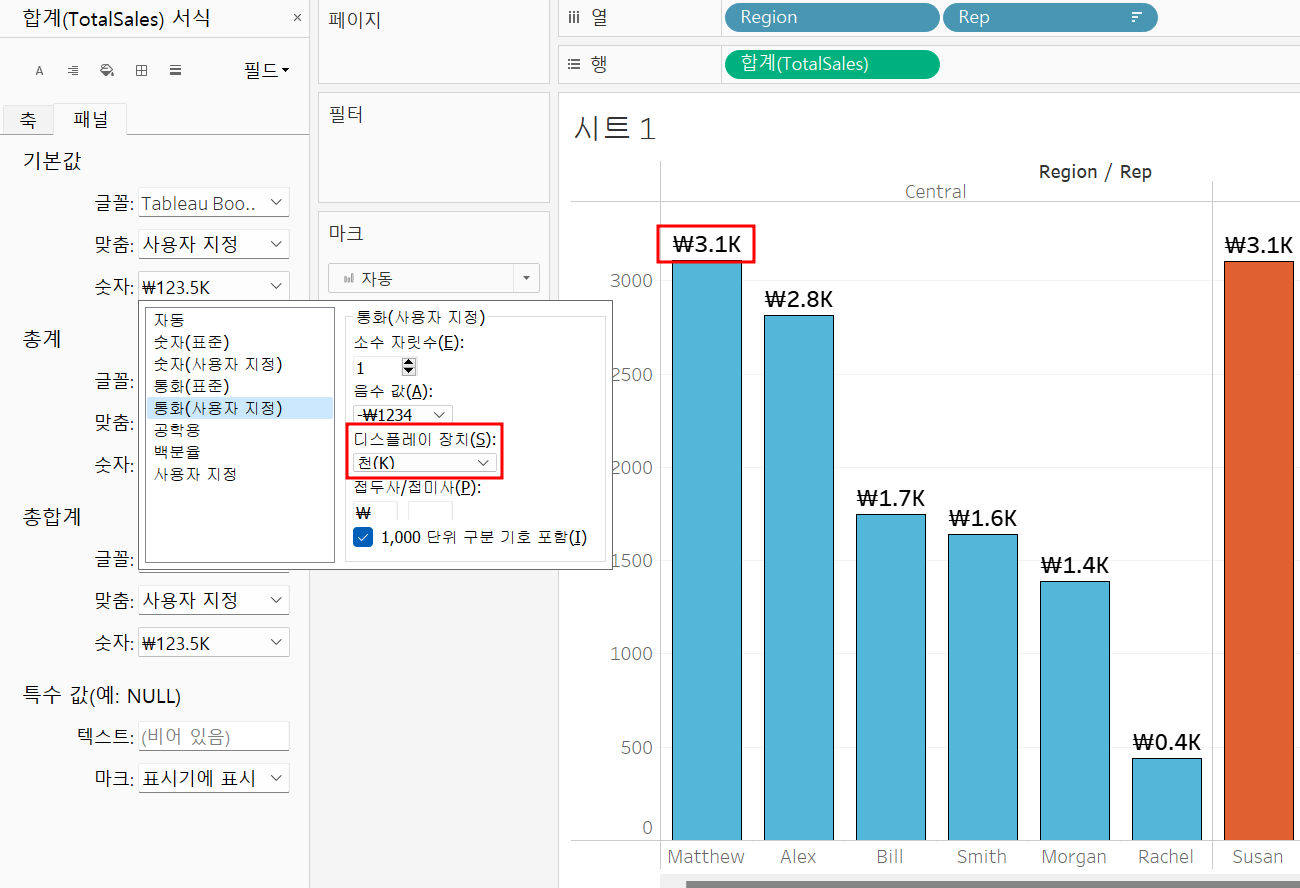
통화 설정과 단위 표현을 정의한 모습! 가시성을 챙길 수 있다.
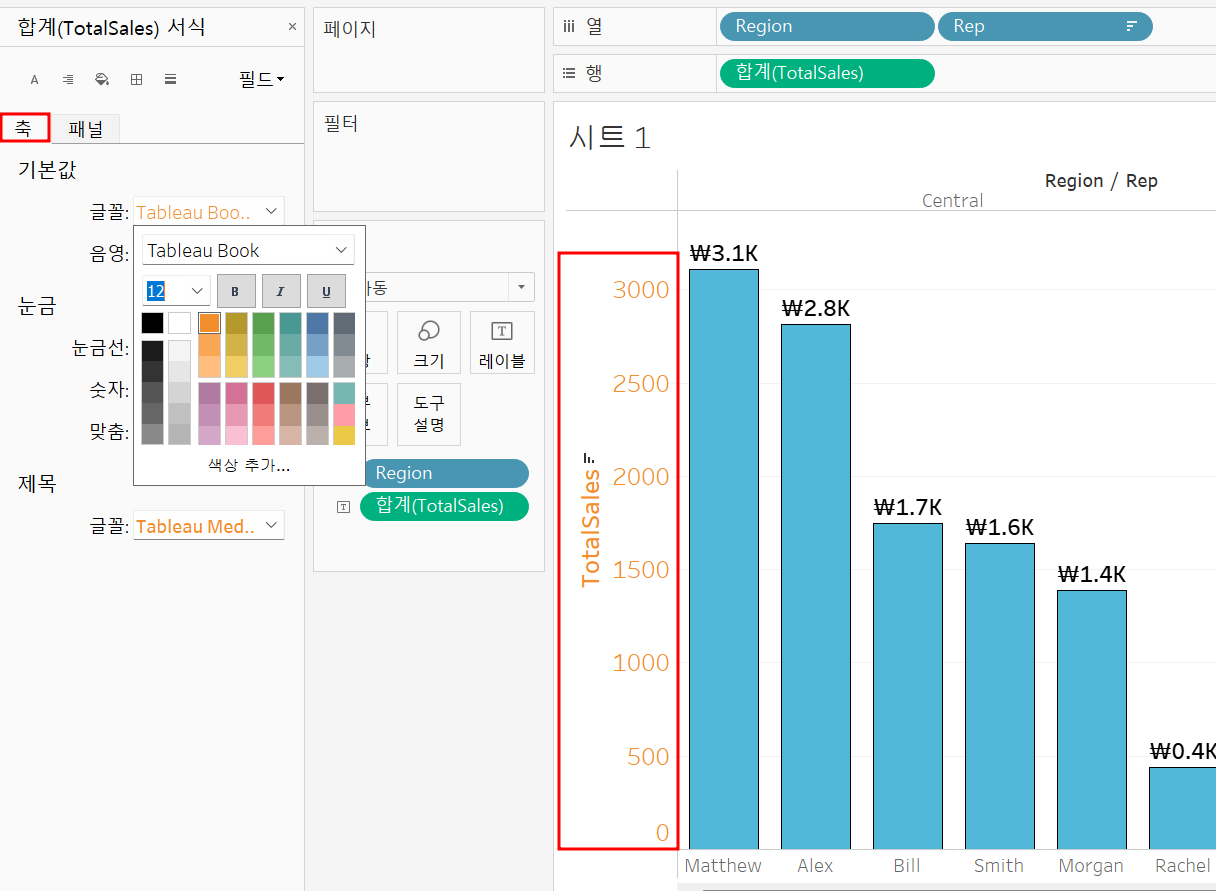
축도 서식 설정할 수 있음!
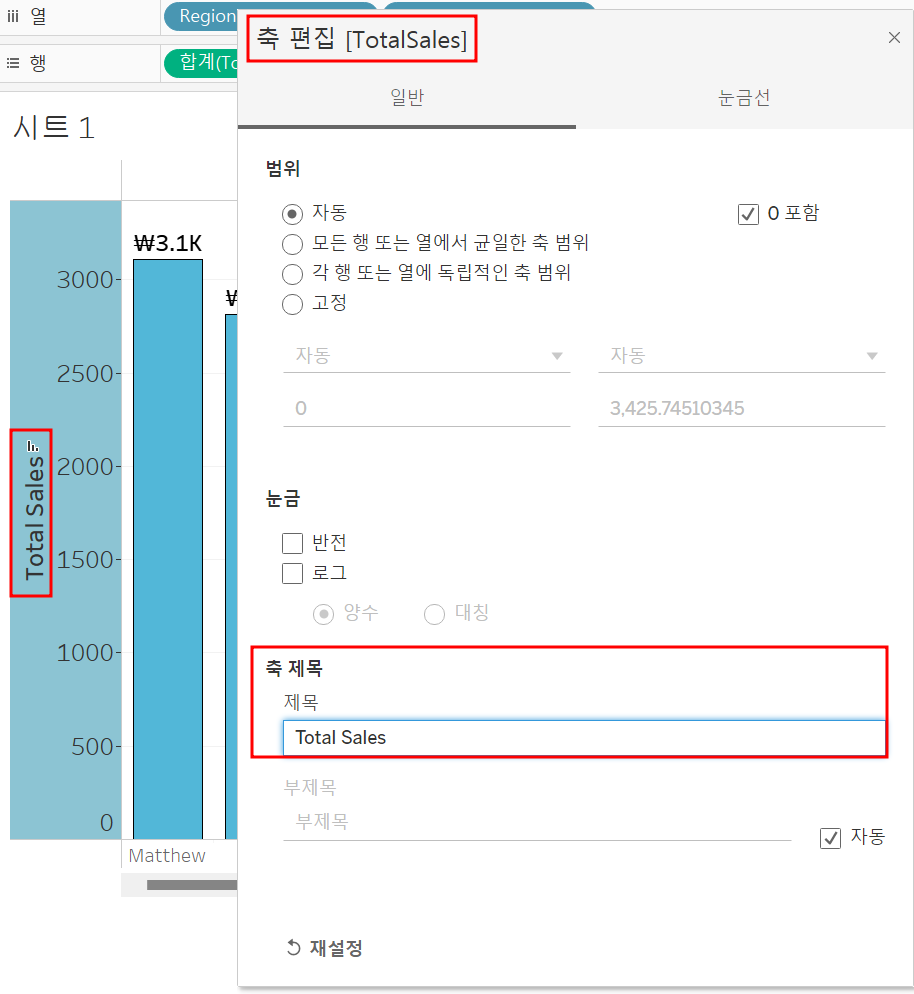
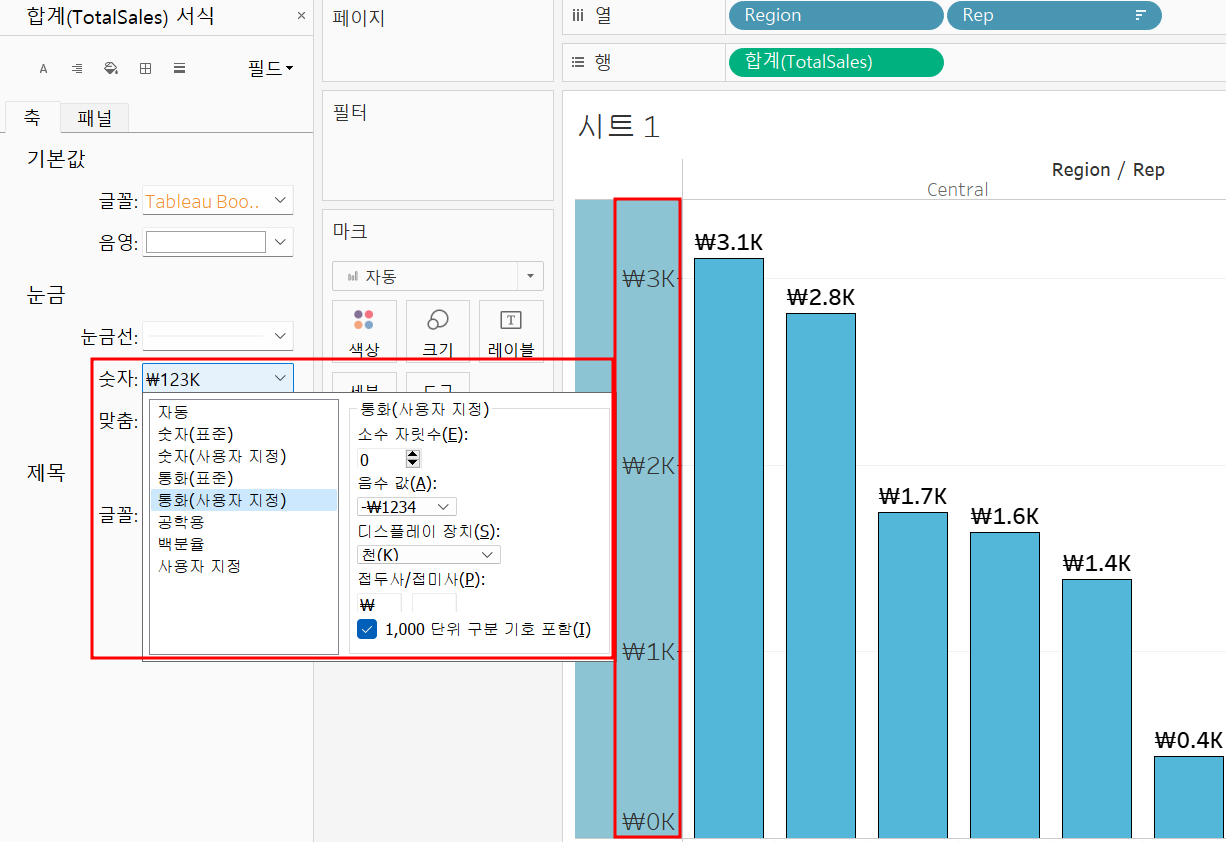
축 제목, 통화 단위 설정할 수 있다 / 축 편집은 축 우클릭하면 나옴!
1.4 워크시트 내보내기
PPT 등으로 어떻게 내보낼까
1. 워크시트 - 내보내기 - 이미지
2. 차트 우클릭 - 복사 - 이미
데이터 추출
워크 시트에서 데이터 우클릭 - 데이터 추출 - 경로 설정
추출 기능은 왜 사용할까?
수시로 바뀌는 동적 데이터 셋은 효율이 안 좋음!
일하다가 원하면 언제든 실시간 데이터 연결로 전환하거나 계속 추출된 데이터에서 작업도 가능하기 때문에
> 워크 시트에서 데이터 우클릭 - 데이터 추출 - 추출 사용 옵션 on/off
2. 시계열, 어그리게이션 및 필터
2.1 시계열 데이터
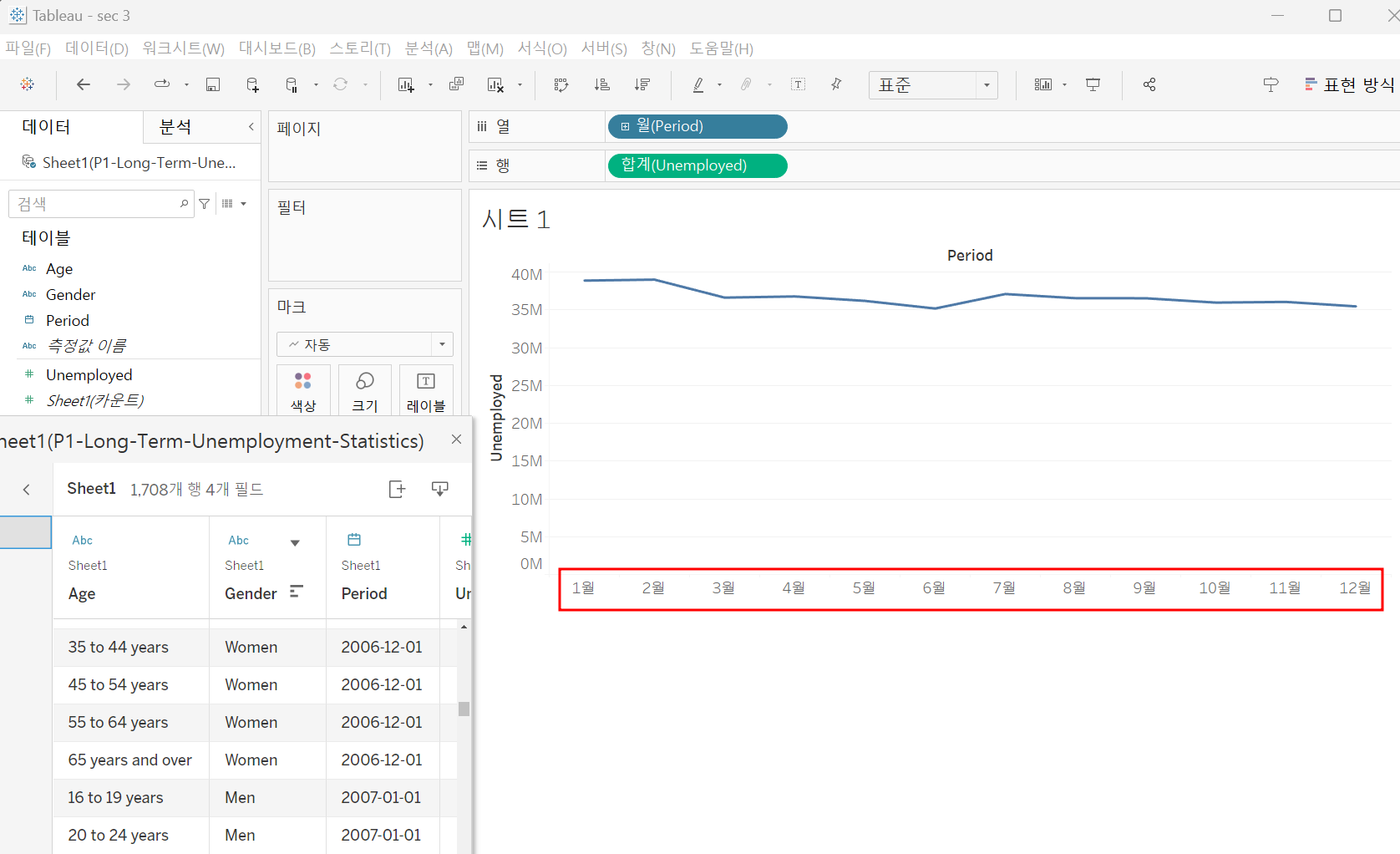
연도에 2005, 2006, 2007 ... 쭉 있음에도 열로 Month를 넣었을 때
태블로는 이걸 범주, 카테고리로 인식해서 그룹화 해서 계산해 줌 (초록색 : 값, 파란색 : 치수)
차원은 연도를 예로 들면 상위 기간을 무시하고 성별과 마찬가지로 월을 범주로 취급!
측정값은 반면 범주 취급하지 않고 적절한 타임라인을 생성
우리가 원하는 연도 별 월을 x축으로 넣으려면 어떻게 해야 할까?
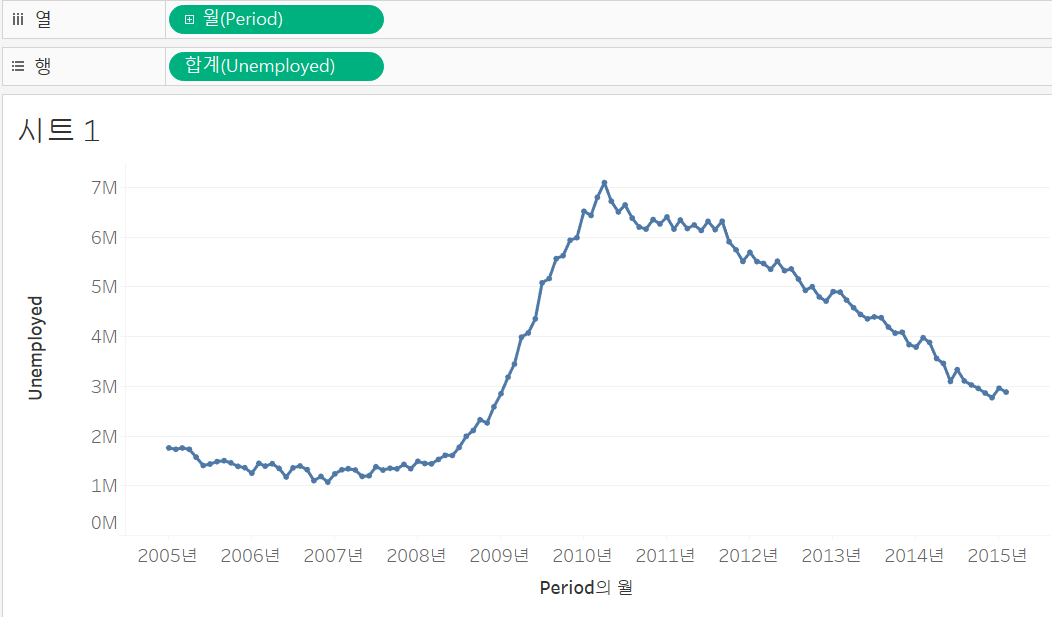
열로 들어가 있는 Period를 우클릭 후 시간 표현 영역 중 두 번째 영역의 월을 선택하면 된다.
이러면 월이 값으로써 들어감.
해서 시계열 데이터를 다룰 때에는 치수, 값 또는 카테고리 중 무엇으로 만들고 싶은지 정확히 하고 세부적으로 설정해 줄 필요가 있음
2.2 집합과 세분화
(1) 집합
태블로는 어떻게 알고 월, 연도를 묶어서 우리에게 보여줄까?
태블로는 항상 사용자가 워크시트에 올려놓은 값의 세분화 정도에 따라 집계를 낸다!
시계열 데이터를 열로 올리면 아~ 연월일시간에 따라 그룹핑해서 보고 싶어 하는구나~ 한다
요기에는 규칙이 있는데 보통 값은 합쳐지고 치수는 정보 세분화의 정도를 결정!
(2) 세분화
집계되는 것이 싫고 세분화해서 보고 싶다?
그럼 상단 메뉴바의 분석 - 측정값 집계를 체크 해제하면 된다~
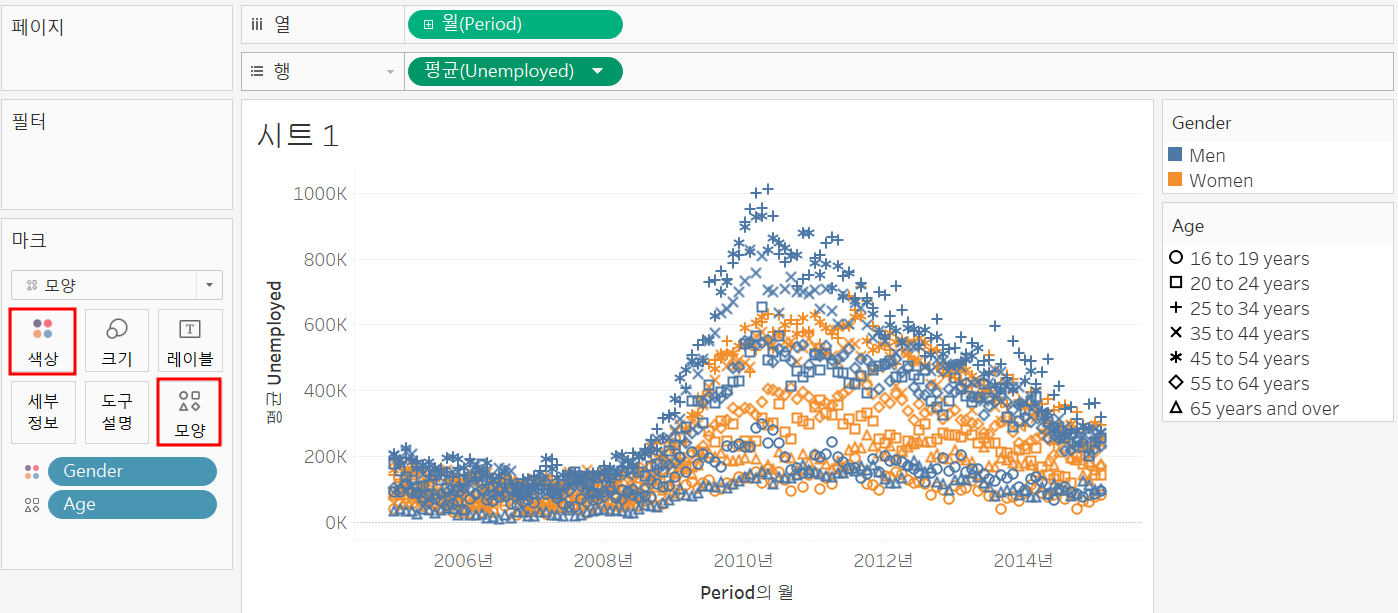
색상, 모양으로 세분화해서 확인 가능
세분화의 디테일을 높이고 싶다면 색상 하단의 세부 정보에 확인할 치수를 넣으면 됨.
2.3 강조 표시와 영역 차트 만들기
(1) 강조 표시
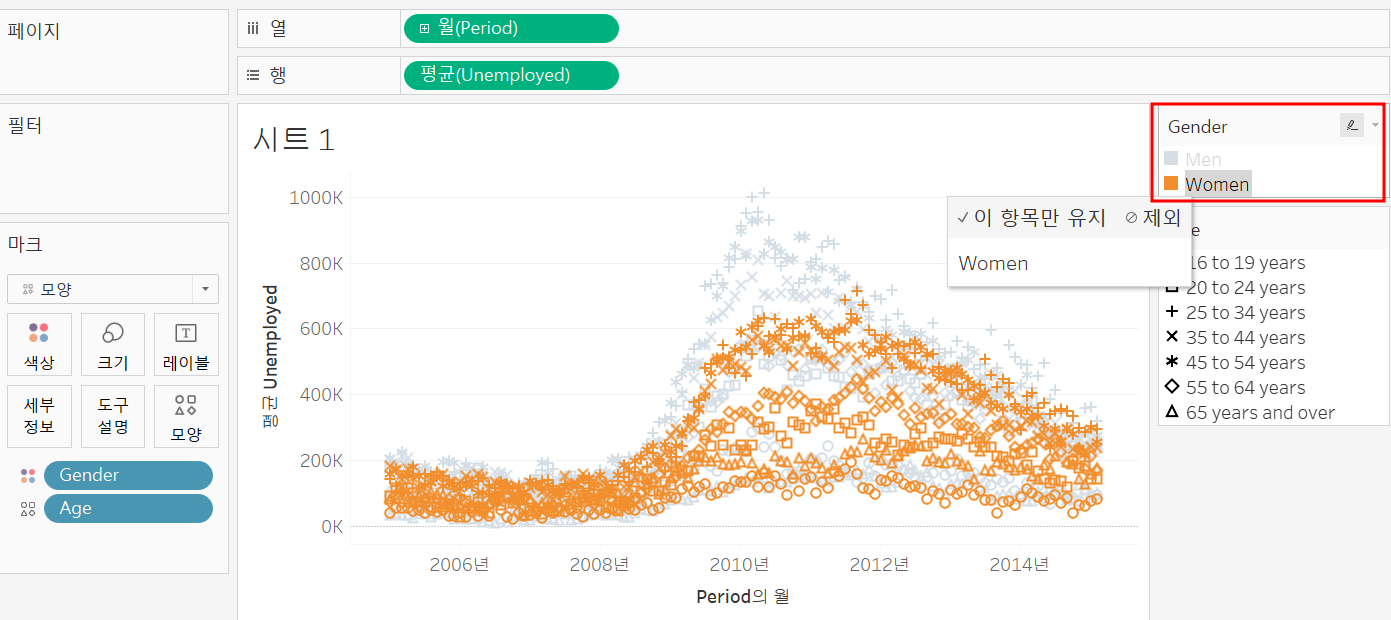
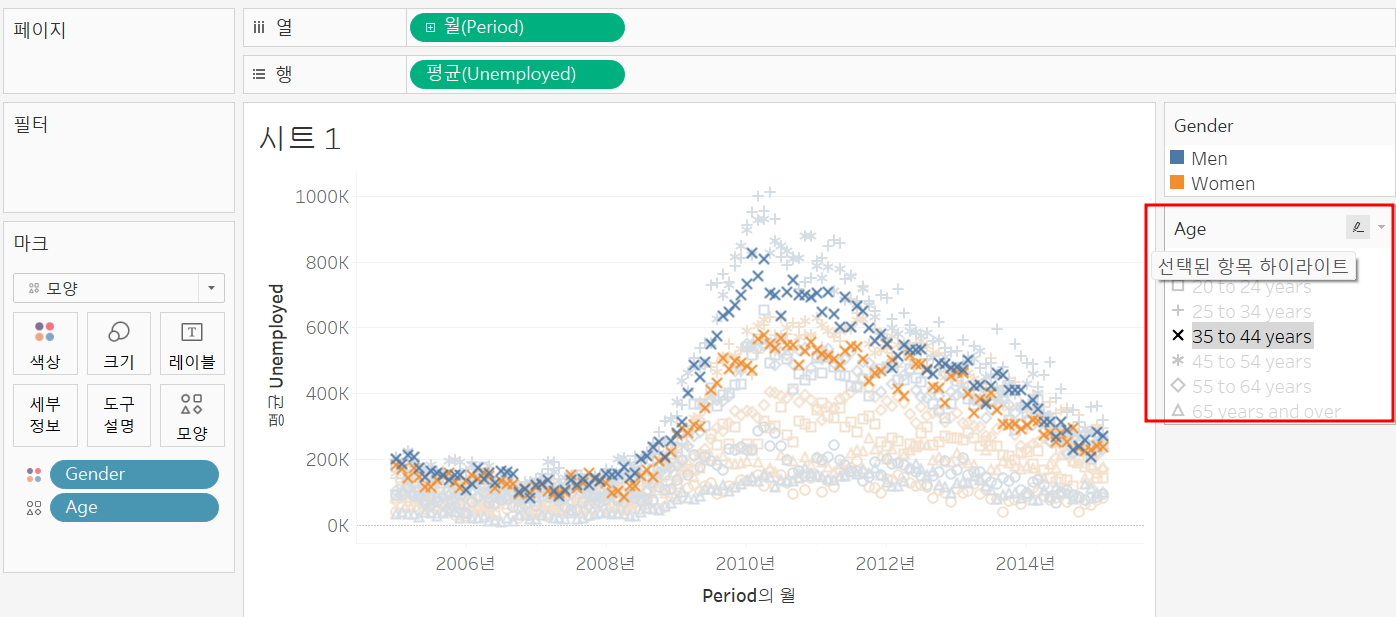
범례를 누르면 강조
(2) 영역 차트
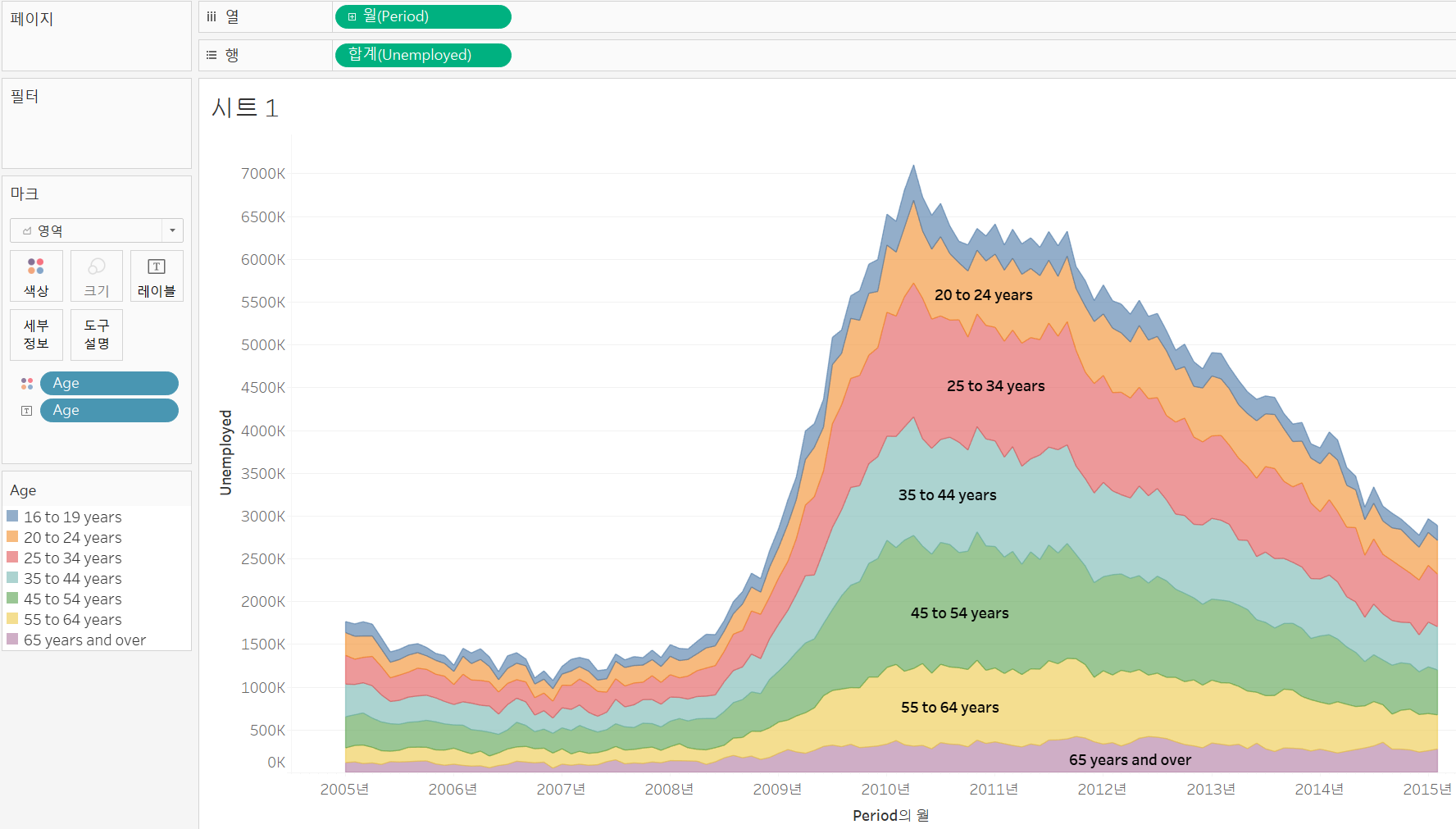
나이 별 합계를 보고 싶어 범례를 추가했는데 너무 지저분해 보인다!?
그럼 영역 차트 사용
2.4 필터 및 퀵 필터 추가하기
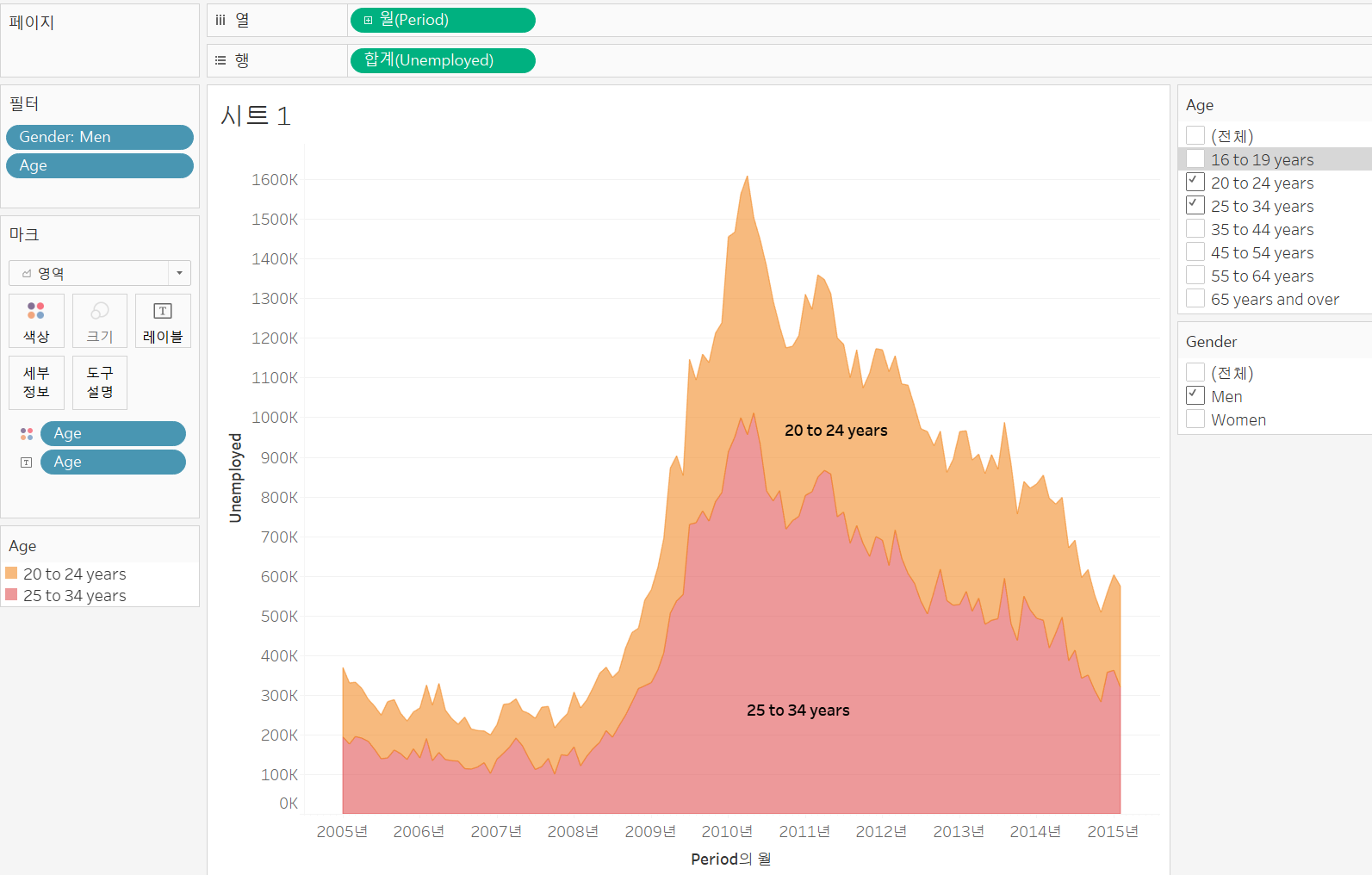
필터에 원하는 칼럼을 넣고 필터 표시 키면 원하는 대로 빠르게 분류하여 볼 수 있음
3. 지도, 산점도 및 대시보드
3.1 지도 생성, 계층 작업하기

(1) 계층 작업
계층? 같은 성질을 띄며 상하관계에 있는 feature에 대해 계층적으로 묶어버리는 기능!
묶어서 관리하기 때문에 편리하다
ex) Country (State (City))
만드는 방법은 묶을 애들끼리 그냥 드래그 드롭하면 됨
(2) 지도 생성

1. 지역에 대한 계층을 만들었다면 시트에 드래그 드롭 -> 지도 생성
2. 수치에 해당하는 녀석들을 크기, 색상 등의 마크에 넣는 것으로 분포를 확인할 수 있다.
3. 필터까지 적절히 걸어주면 최고 (데이터 셋 내에 두 개 이상의 비슷한 데이터가 있을 경우 구분하기 위해 필터 거는 게 좋다)
3.2 산점도 생성, 여러 워크시트에 필터 적용하기
잡기술 : 2개 이상의 시트에 같은 필터 집어넣기
필터 우클릭 - 워크시트에 적용 - 웬만하면 이 데이터 셋 사용하는 시트에 함께 적용
(1) 산점도 생성

Sales에 따른 Porfit을 Customer Name 별로 보고자 하면?
1. 모양 - 꽉 차게
2. 색상 - 색상, 투명도, 범위 설
3. 크기 - 적절히
4. 필터 - 이전 시트와 동일하게 연도
확보할 수 있는 인사이트?
- 년도에 따른 전체적인 분포 확인할 수 있음
- 높고 낮은 고객들을 대상으로 보완, 강화하여 액션 취할 수 있음
3.3 대시보드 생성
대시보드 공간에서는 추가적인 분석 수행 X
기존에 만들어뒀던 자료들을 보기 좋게 만드는 것
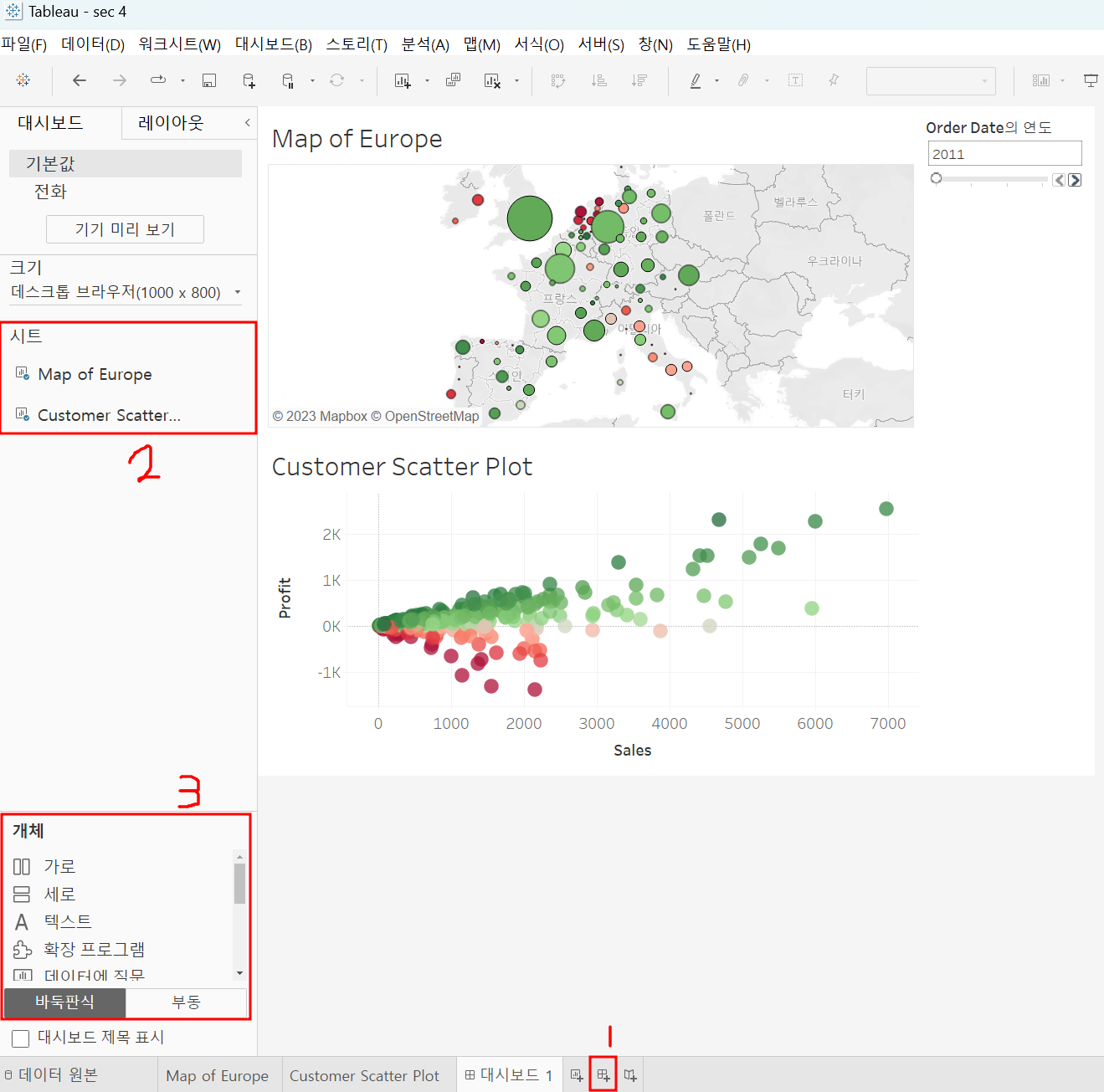
1 : 대시보드 생성
2 : 만들어둔 워크 시트 드래그 드롭으로 대시보드 구성할 수 있음
3 : 대시보드 구성에 도움이 되는 도구들
3.4 액션 기능
(1) 액션 기능?

map을 필터로 사용하게 되면 map의 특정 지역을 선택했을 때 해당 나라의 scatter plot이 동작한다.
어떠한 원리가 숨어있을까?
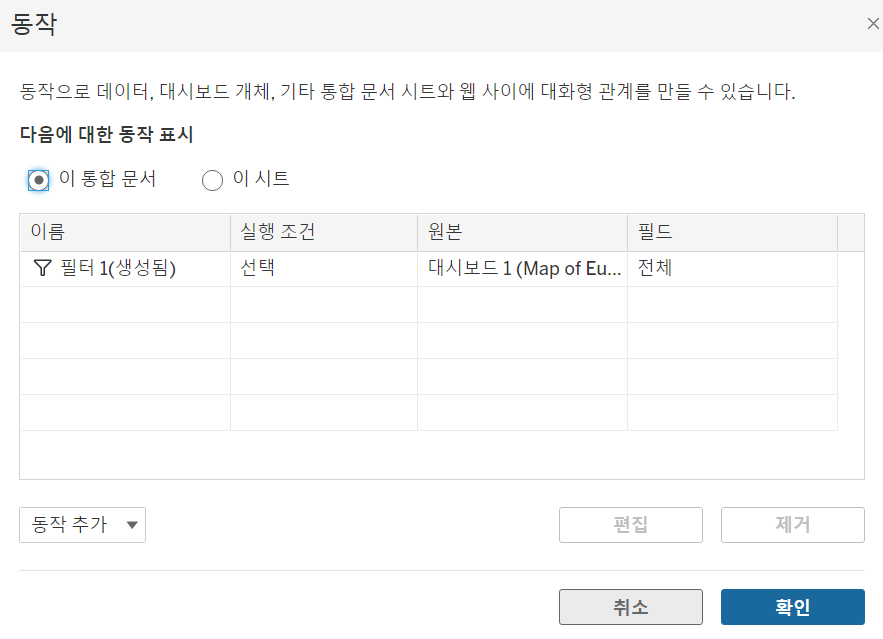
우선 액션 관리는 대시보드 - 동작에서 수행할 수 있고
위에 자동으로 추가시킨 액션이 동작하고 있는 것을 확인할 수 있다.
자세히 살펴보자
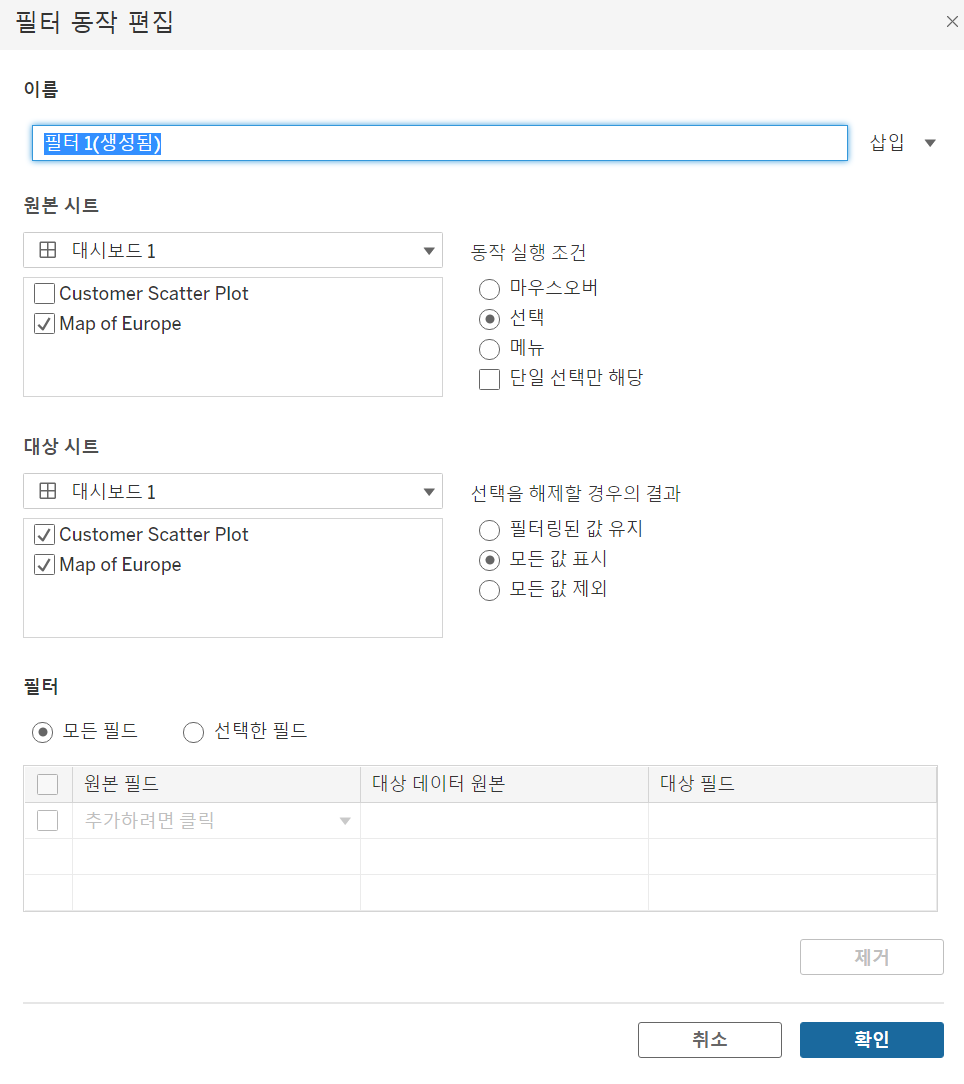
원본시트
액션의 시작점 : Map of Europe
동작 실행 조건 : 선택
-> Map of Europe을 선택하면? 해당 나라에 대응되는 데이터로 Scatter Plot이 변화
대상시트
액션 대상 : Customer Scatter Plot, Map of Europe
선택 해제할 경우? : 모든 값 표시!
-> Map of Europe 빈 곳 선택하면 액션 초기화
(2) 두 개 이상의 지역을 선택하려면?
- ctrl 누르고 선택
- 직사각형으로 드래그
- 마우스로 선 그어서
3.5 하이라이트
(1) 하이라이트?
액션 필터는 말 그대로 필터링이라 선택한 부분 제외한 정보들은 전부 제외시켜 버린다.
해서 Scatter가 선택한 지역과 관련된 정보만 뿌릴 수밖에 없게 만듦
근데 하이라이트는 관련 없는 정보를 전부 제외시키는 게 아니라
선택한 지역과 관련 있는 고객들의 정보를 띄움과 동시에 하이라이트 시켜서 사용자들에게 보여주는 것!
일단 추가해 보자
동작 - 하이라이트


지역을 선택했는데 아무 일도 일어나지 않는다! 왜?
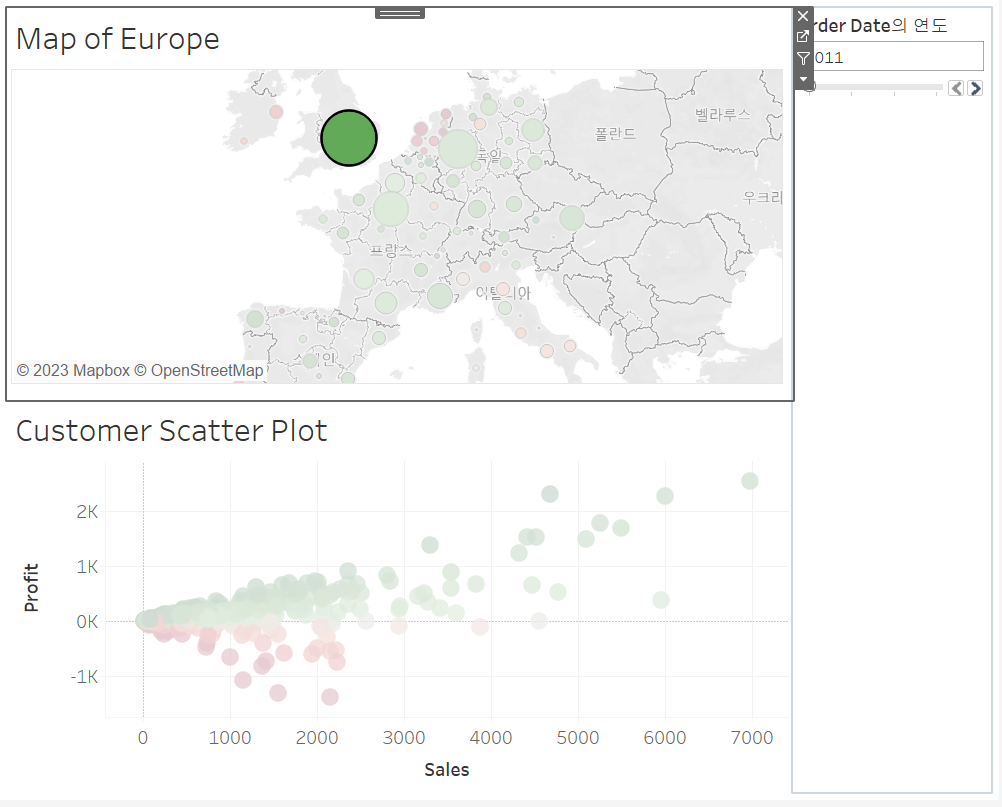
데이터 셋 내의 고객들 중 몇 명은 다른 지역 여러 곳에서 주문한 경우가 있기 때문!
EX) 프랑스에서 주문 후 영국에서 주문
이런 고객들은 특정 지역과 구각에만 묶여 있는 데이터가 되지 못한다
데이터 셋을 보면 다른 주, 국가, 도시 등에서 주문한 사람들이 있겠지~ 살펴보자
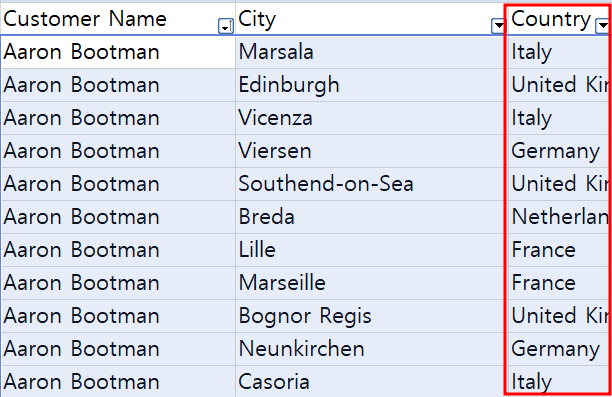
보이는 것처럼 같은 사람이 다양한 국가에서 주문을 했다는 것을 확인할 수 있다.
이렇기 때문에 특정 국가를 선택했을 때, 해당 국가에서만 주문한 고객이 하이라이트 되지 못했던 것
만약 선택 국가에 해당하는 지역을 띄워버리면 어떤 일이 발생할까?
해당 산점도는 선택 국가 이외의 국가에서 주문한 정보까지 전부 합쳐서 집계된 값을 표현! 따라서 의미가 없다
그렇기에 태블로는 잘못된 정보를 줄 바에는 하이라이트 하지 않겠다고 판단
그럼 어떻게 해야 하나?
세분화 말고는 답이 없다
Scatter plot으로 돌아가서 세부정보에 State를 추가해 주자


잘 표시가 되는 모습!
정리하면
액션 필터 : 데이터 셋을 기준으로 작동. 데이터 셋에서 직접 데이터를 거른 뒤 필요한 정보를 뿌려주는 방식
하이라이트 : 데이터 셋에서 거르지 않기 때문에 특정한 데이터만 뽑지 못함. 워크시트에서 세분화 작업해야 함 -> 데이터가 시각화되고 그 후에 작업이 적용
4. 조인과 블렌딩
4.1 조인
(1) 조인이란?
데이터가 구조화된 형식으로 저장된 플랫폼에서 사용! 다음 사진 한 장으로 정리 가능

# FULL OUTER는 ON 조건으로 일치하는 행만 결합시키고 나머지는 그대로
4.2 블렌딩
(1) 블렌딩이란?
블렌딩 : 여러 형태의 데이터를 가공해서 필요한 데이터를 만드는 것 (데이터 연결, 데이터통합)
(2) 조인 vs 블렌딩
조인 : 먼저 데이터를 결합한 후 집계
블렌딩 : 시트에서 각각 집계한 다음 결합 (시트 별로 이루어짐)
(3) 사용하는 경우?
1. 데이터 세트의 세분화 수준이 다를 때
2. 데이터 세트가 다른 유형의 데이터 소스일 때
예를 들어
A : 판매 금액 테이블 (월별)
B : 판매 목표 테이블 (분기별)
A, B 테이블을 이용해서 시각화하고 싶을 때 조인하게 되면 매 월마다 분기 목표가 붙는다.
즉, 3개의 월에 같은 분기목표로 중복! 이런 상황에 블렌딩을 활용할 수 있다
데이터를 통해 직접 해보며 더 자세히 알아보자
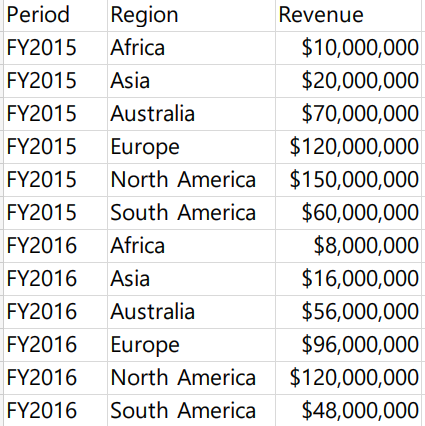
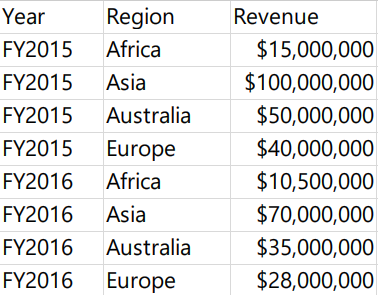
위의 A, B 데이터를 블렌딩 하고자 한다

태블로가 자동으로 A, B에 공통적으로 존재하는 Revenue를 Left Join으로 결합해서 보여준다
근데 Region에 대한 분리는 적절히 수행했지만 Period에 대한 분리는 수행하지 못하는 모습!
왜 그럴까? A에만 존재하는 컬럼이므로 태블로가 B의 어떤 컬럼에 연결해야 할지 모르기 때문
>> 연결을 만들어 해결할 수 있고 두 가지 방법이 존재한다
방법 1

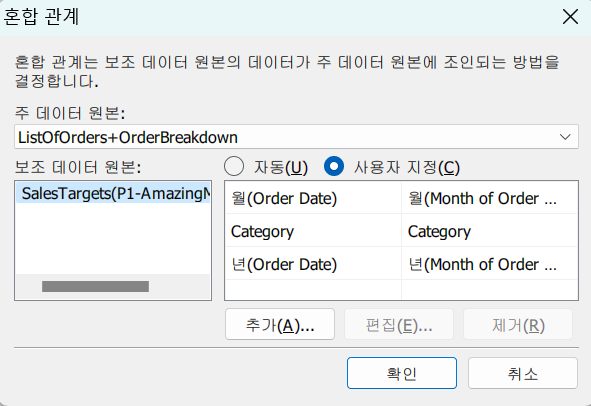
[데이터] - [혼합 관계 편집]
조인 조건 사용자 지정을 통해
A의 Period에 B의 Year을 매핑해준다!
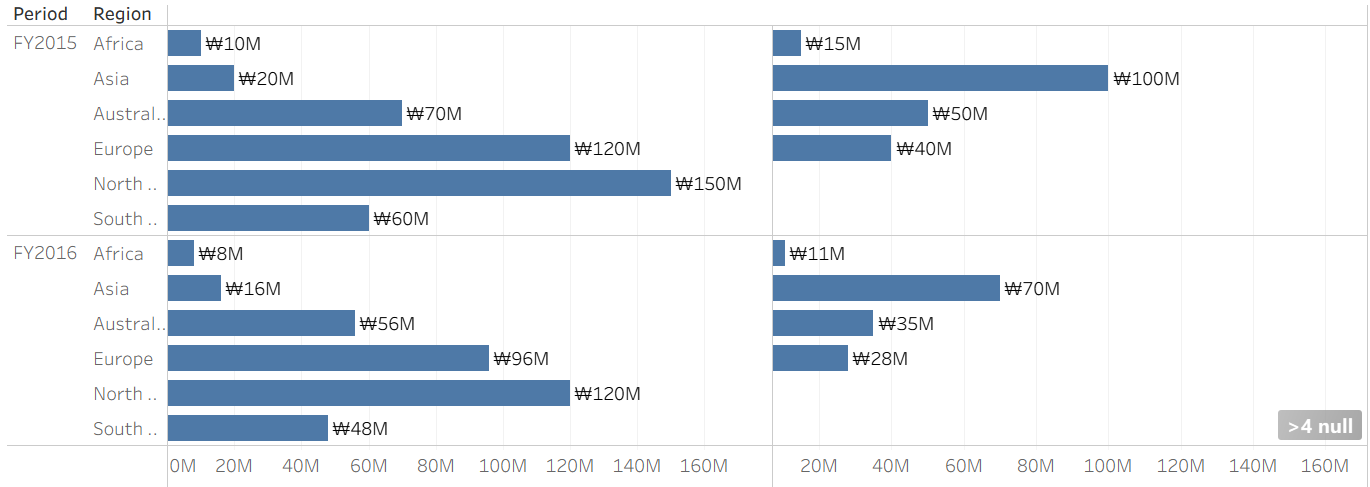
전과 다르게 A의 Period와 B의 Year이 맵핑되었기 때문에 Period에 따른 B의 데이터가 변하는 것을 확인할 수 있다.
방법 2

또 다른 방법으로는 단순하게 B의 컬럼 이름을 A와 동일하게 만들어 주면 된다
정리하면
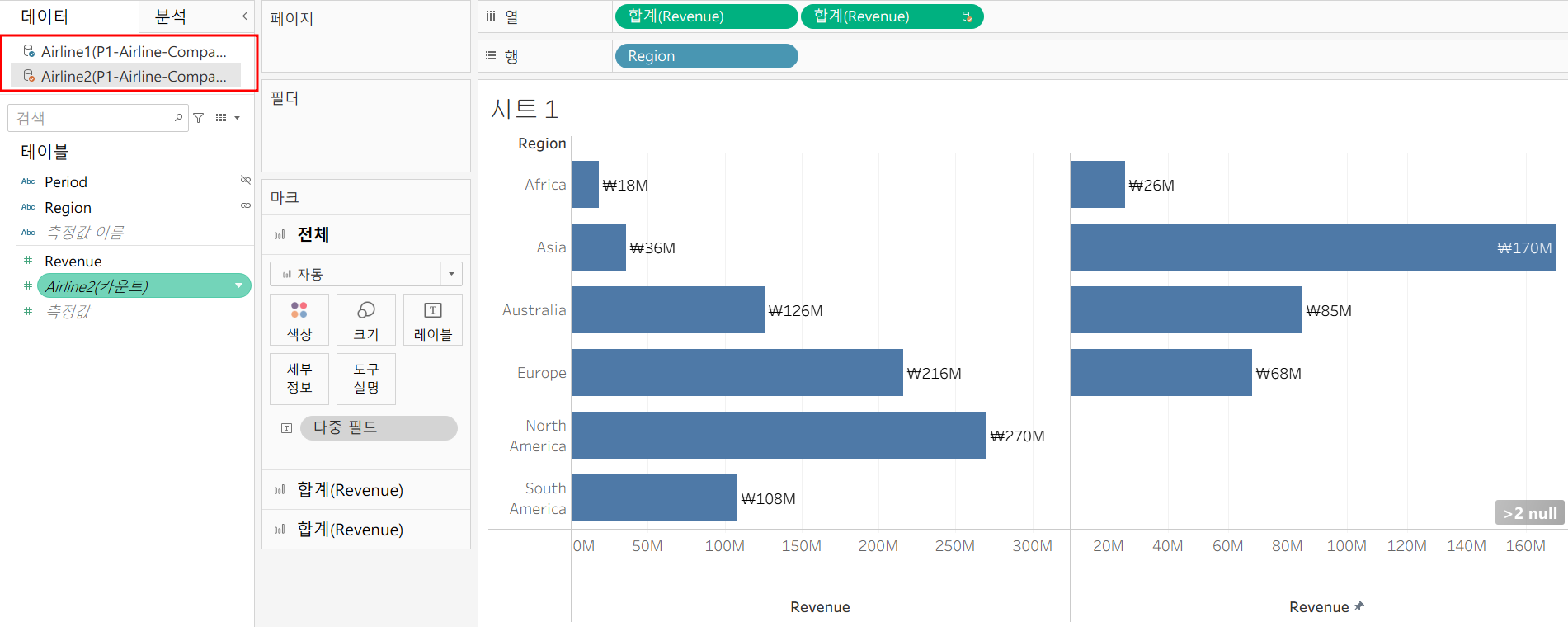
A 기준으로 B가 LEFT JOIN
A에서 현재 행으로 넣은 Region 기준으로 데이터를 뽑아오고
이후에 B에 접근해서 그 Region 기준으로 다시 데이터를 뽑아오는 것 (똑똑해!!)
데이터 베이스 보면 파랑, 주황색으로 그 관계를 확인할 수 있다.
반대로 B를 기준으로 JOIN을 시키면 어떻게 될까?
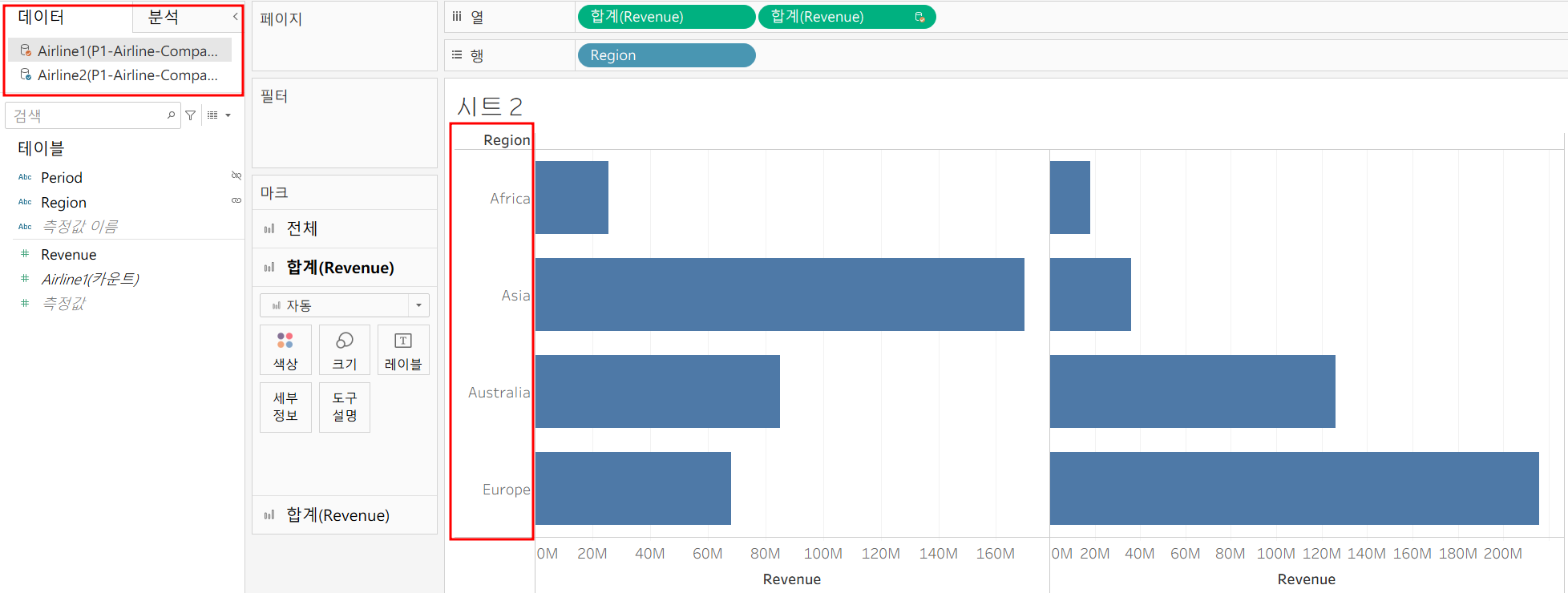
LEFT JOIN이기 때문에 B 기준으로 겹치지 않는 A의 Region들은 탈락한 모습을 확인할 수 있다.
4.3 이중 축 차트
4.2에서 배웠던 블렌딩을 활용해 시각화 해보고 이중 축 차트를 알아보자!
(1) 월별 카테고리별 매출액이 Sales Targets의 목표 매출액을 달성했는지 확인
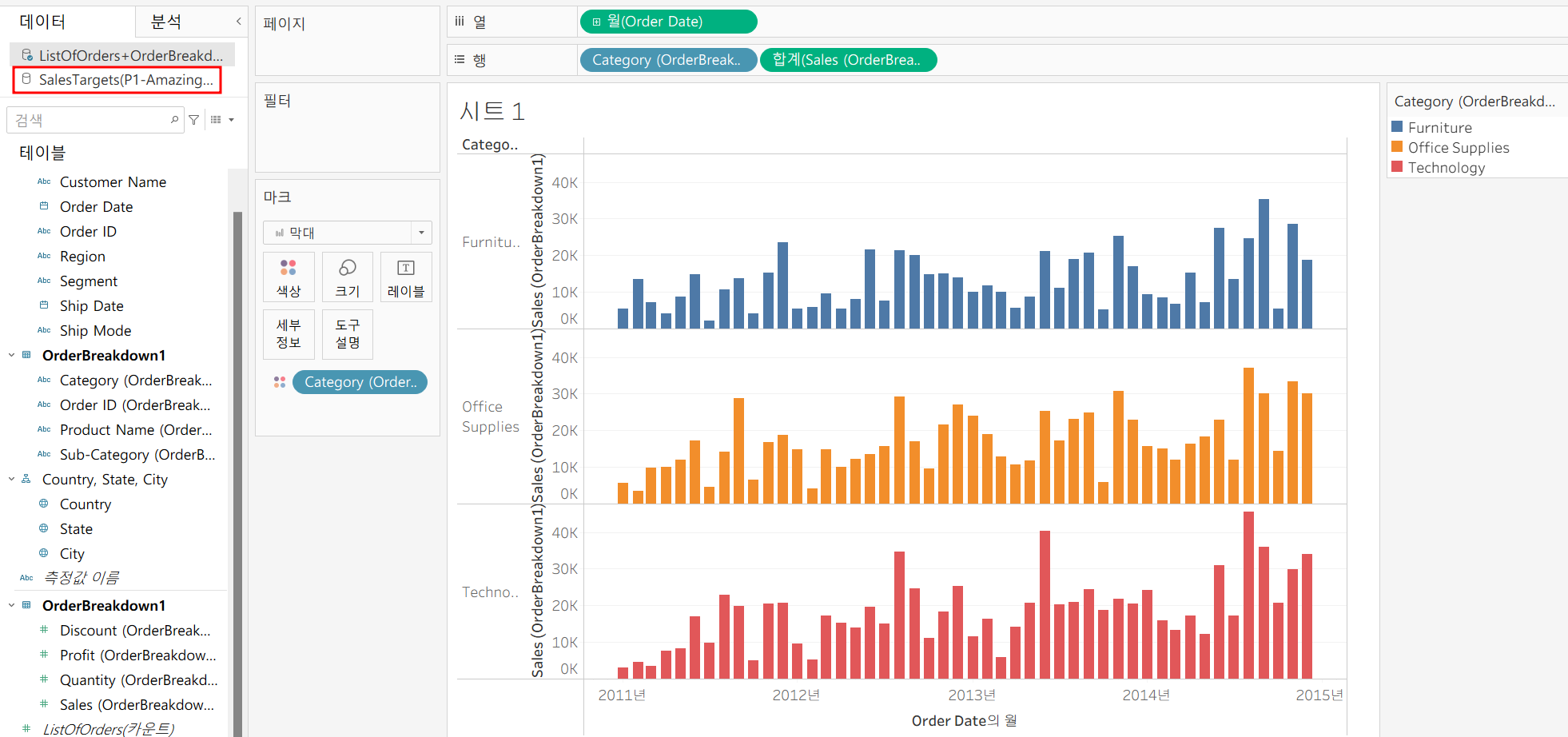
우선 월별, 카테고리별 매출액을 시각화!
그리고 목표 매출액은 Sales Targets안에 있기 때문에 따로 가져와야 함
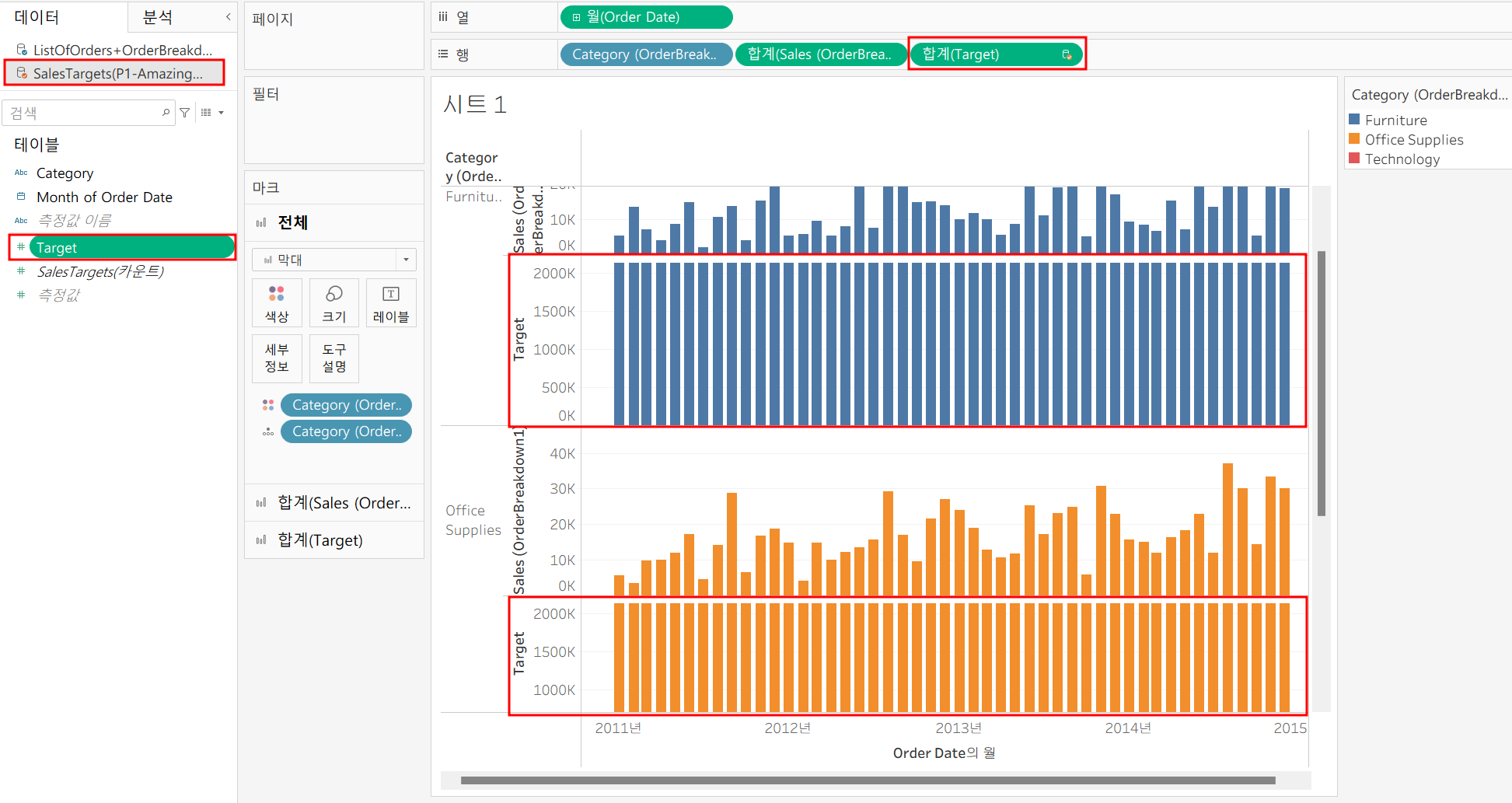

Sales Targets의 Target 컬럼을 넣어주면 태블로가 자동으로 카테고리별 매출액을 집계하여 뿌려주지
월별로 분리되지는 않는다! 여기서 월별로 분리하려면 데이터 관계를 정의해주어야 한다
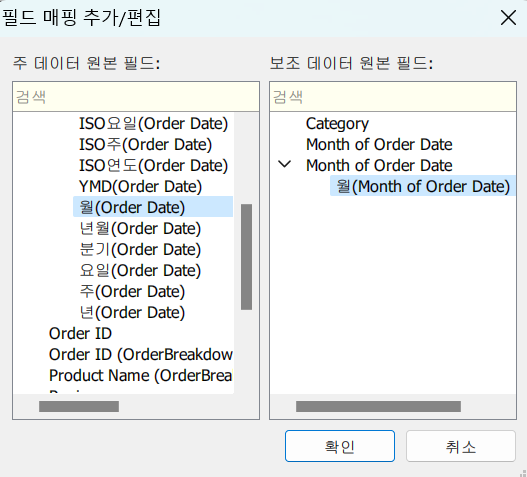
좌측 사진과 같이 월-월로 매핑해주면 된다!
근데 요게 범주형 변수이기 때문에 연-월로 분리될 수 있게 연도에 대한 맵핑도 추가로 진행해주어야 한다.
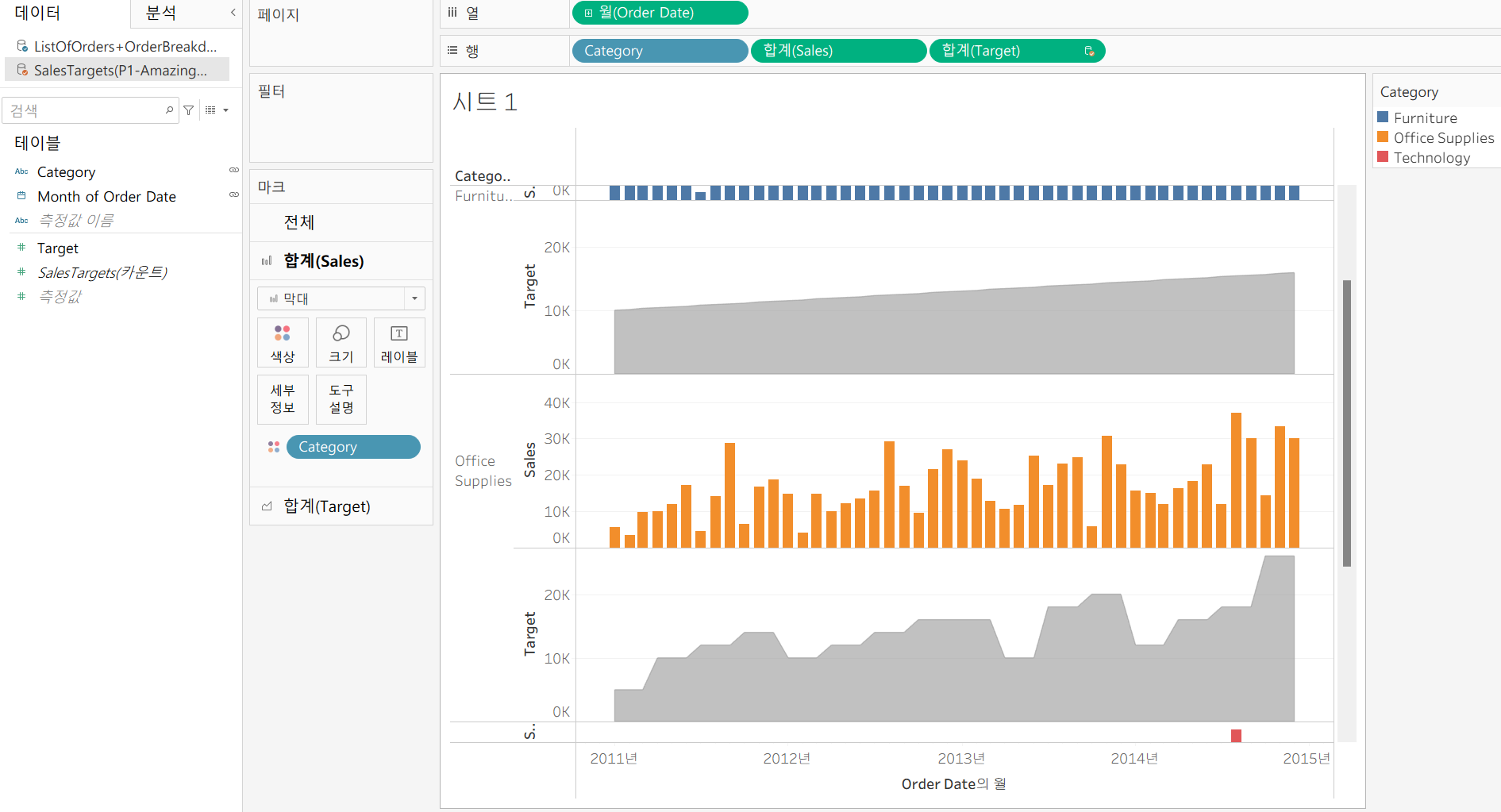
연-월 그리고 카테고리별 Targets가 잘 들어간 모습
근데 sales와 Targets를 합쳐서 확인할 수 있다면 가시성이 훨씬 좋아지지 않을까?
이중 축 차트로 만들어보자
(2) 이중 축 차트

만드는 방법은 간단하다!
1. [좌측 y축 우클릭] - [이중 축 차트]
2. [우측 y축 우클릭] - [축 동기화]
# 축 간 선-후 관계 설정은 행의 순서로 설정
4.3 블렌드에서 계산된 필드 만들기
우리가 확인해야할 목표는 실제 매출-목표 매출액 사이의 간극!
Targets - Sales를 시각화 하는 것으로 카테고리별 간극을 빠르게 확인할 수 있도록 해보자
우선 그래프가 이미 6개라 가시성이 떨어질 수 있으니
보는 사람들이 쉽게 확인할 수 있도록 Category를 filter로 만들자
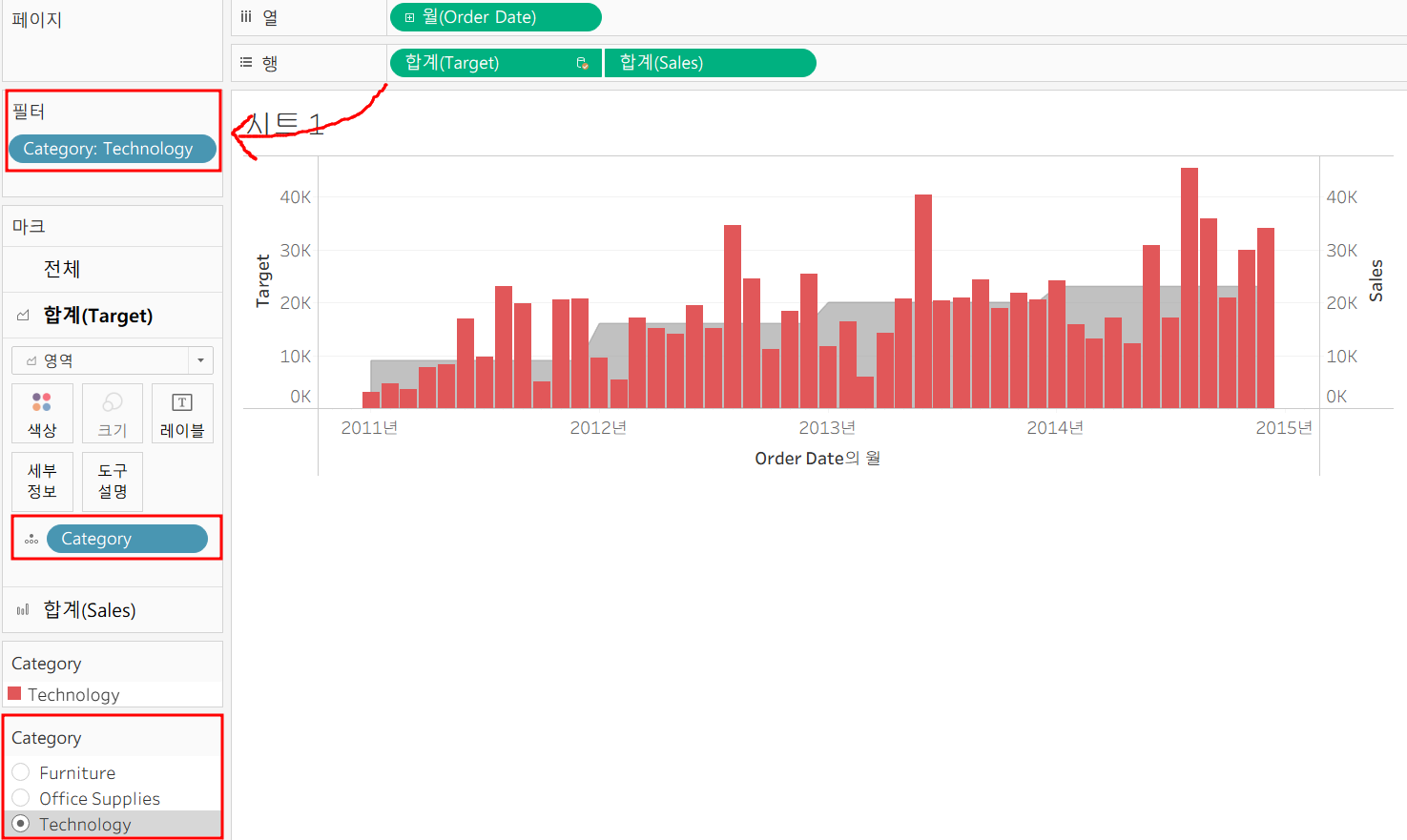
여기서 차트에 카테고리를 표현하지 않기 위해
기존에 행에 존재하던 Category를 제외하고 filter 추가했다면?
태블로는 Target 컬럼을 세분화 할 수 없기 때문에 세부정보로 넣어서 인식시켜야 한다!
그렇지 않으면 필터를 카테고리별로 나눴어도 각 차트에 전체 Target이 동일하게 들어감

그리구 이제 가시성을 확보하기 위해
목표 매출 - 판매액 계산 테이블을 생성해보자
계산 시에 Target을 우측 그림과 같이 표현하는데 이건 DB가 달라서 위치를 함께 표현하기 때문이다.
그리고 계산에 오류가 있다는 것은 Target이 sum으로 집계되어 있는 반면 Sales는 단독으로 존재하기 때문! Sales에도 Sum 추가해주자

만들고 행에 추가했는데... 오잉?
이건 특정 차트의 세분화 수준이 고려되지 않기 때문이다!!!
세부 정보로 Category를 추가해주자
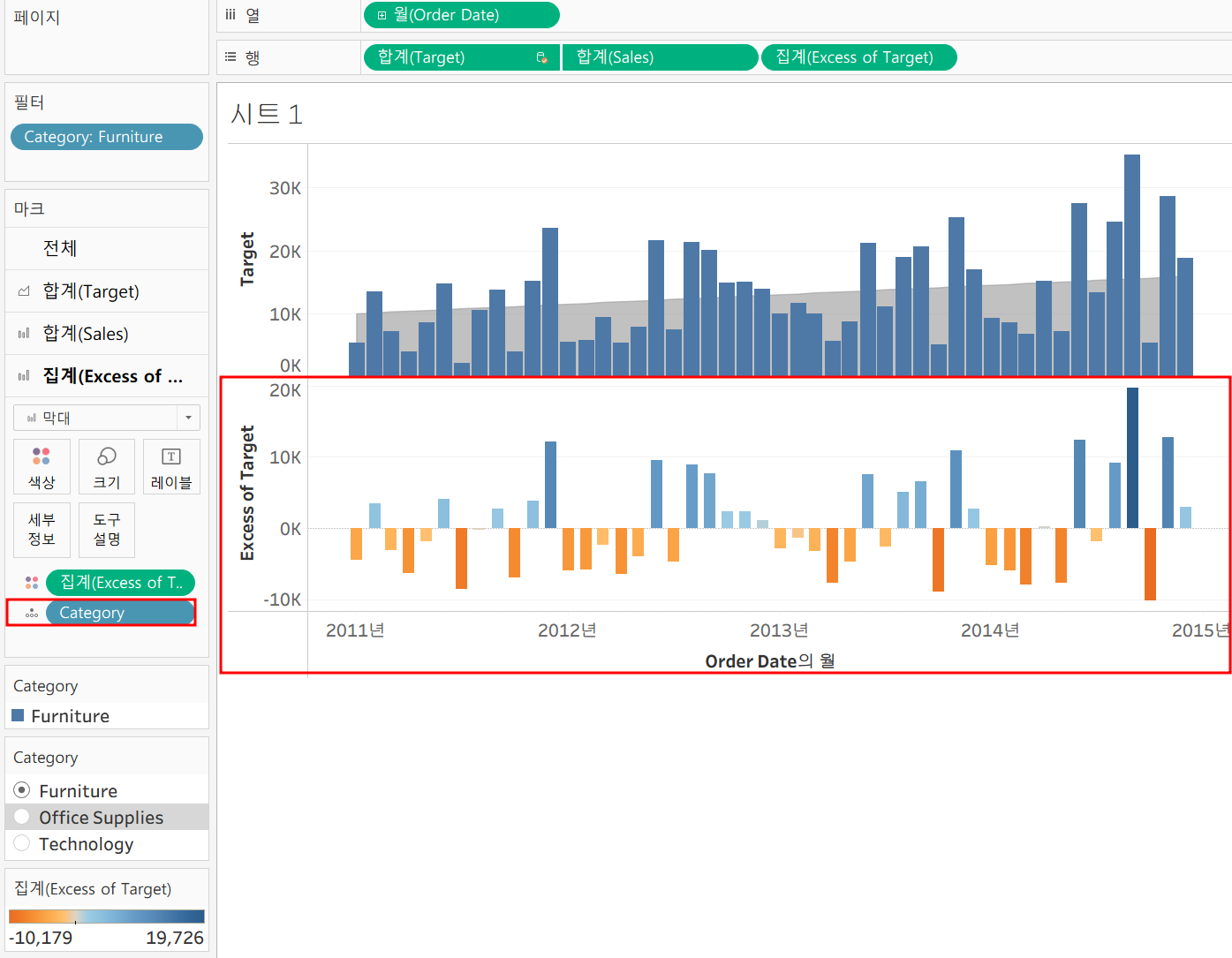
카테고리별 정확히 집계되어 나오는 모습~
그리고 Target과 Sales는 현재 동일한 크기의 y축을 공유하고 있기 때문에 우측 y축을 제거해도 무방
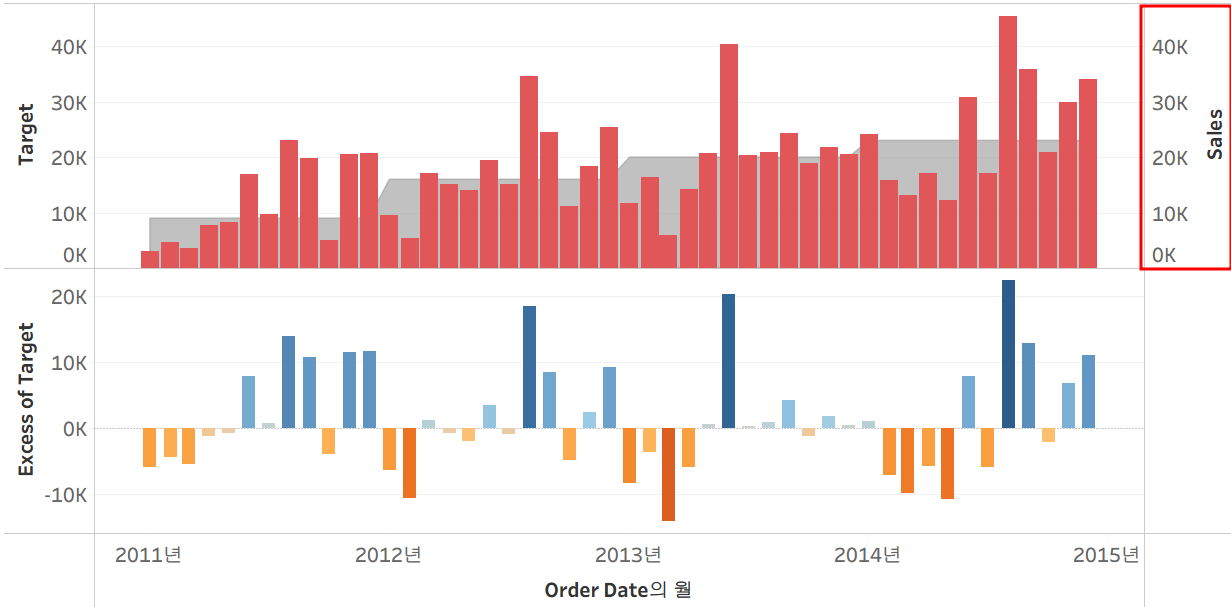

[해당 축 우클릭] - [머리 글 표시 체크 해제]
그리고 축 이름을 변경해주면 우측과 같이 시트를 깔끔하게 만들 수 있다.
5. 관계 작업 및 시각화
5.1 관계 작업
사용 데이터 : kaggle - Brazilian E-Commerce Public Dataset by Olist

시트를 보고 태블로에 데이터를 먹이는 절차를 진행해보자
조인과 블렌드를 이용해야 하는데 어떻게 적절히 사용하여 연결할 수 있을까?
특히 블렌드는 시트 당 생성이기 때문에 엄청 많은 작업을 수행해야 할텐데!

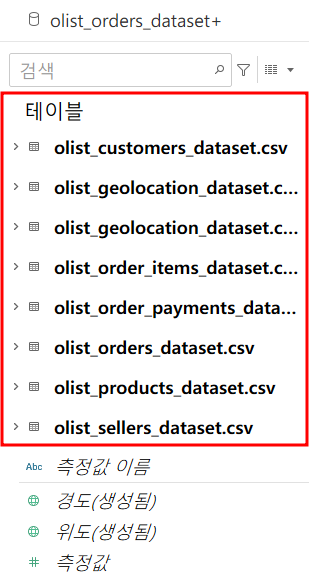
조인을 사용하지 않고 논리 계층에 던져놓는다. 합치지 않고 관계가 ~하다고 태블로에게 말해놓은 상태
5.2 시각화
만들어놓은 스키마를 통해 시각화 진행!
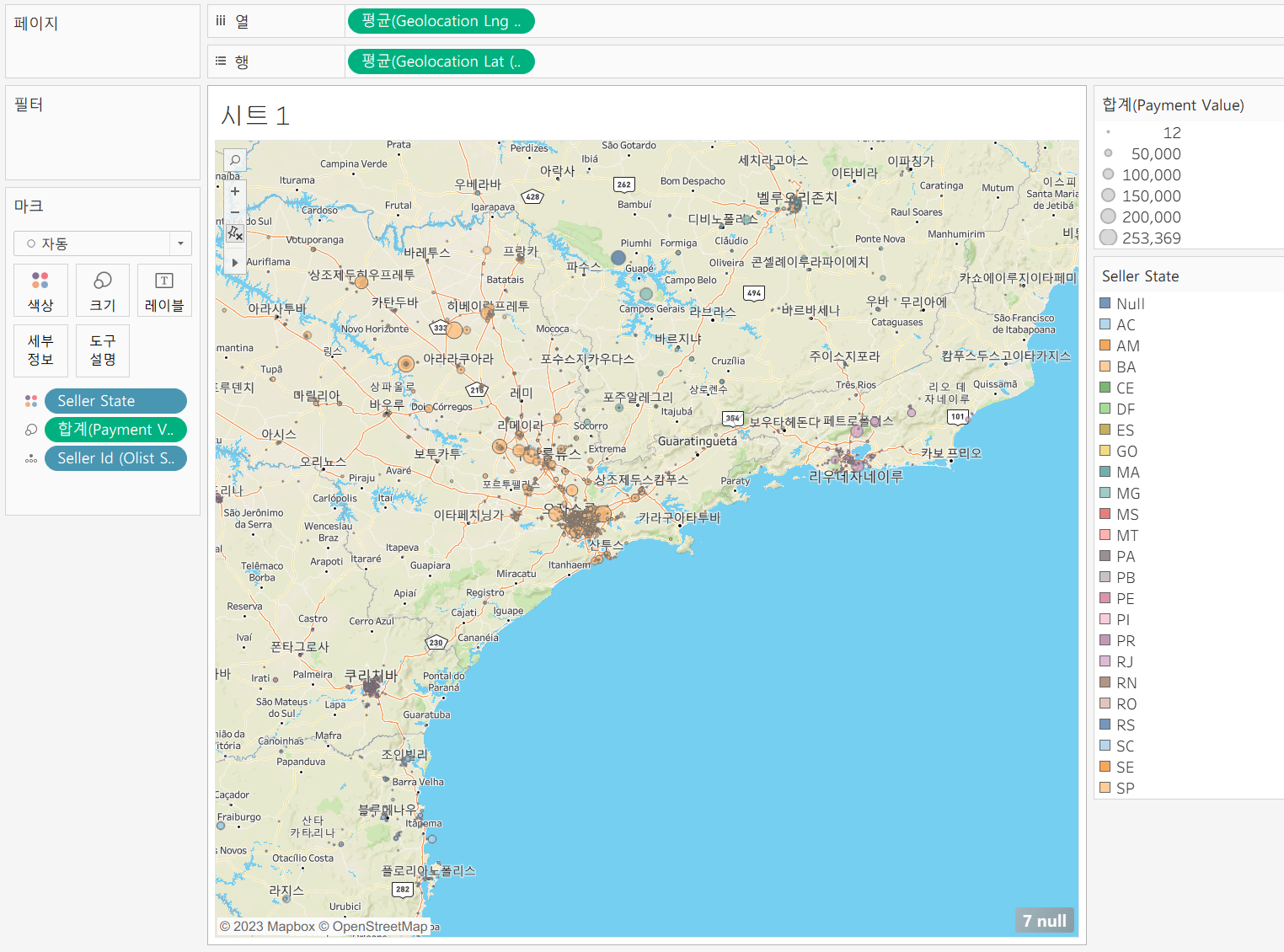
상세한 지도 표시는 상단 도구에서 [맵] - [배경 맵] - [거리] 선택하면됨

여기서 마크가 놓이는 순서는 집합의 우선 순위를 설정하는 것과 동일함! 즉, 블렌드와 비슷한 개념!
각 테이블에서 가져온 데이터들로 분류를 하게 된다.
세부 정보에 놓은 판매자들의 Id를 통해 타 테이블의 위경도 찾아 들어가 뿌리고,
seller state로 색상을 뿌리고
또 다른 테이블에서 판매 금액의 합계를 크기로써 뿌려주고
하는 식으로 구성!
이걸 블렌드로 하나하나 엮으며 구현하려면 엄청 오래걸릴텐데
관계를 정의해놓는 것으로 쉽게 엮을 수 있다.
6. 요약
1. 다양한 상황에서의 조인
- 여러 필드에서 결합하는 경우, 신경써서 조인하지 않으면 특정 메트릭 또는 매출액 등이 과하게 팽찰할 수 있다.
2. 블렌딩
- 항상 LEFT JOIN > 주요 데이터 소스(파랑), 보조 데이터 소스(주황)
- 블렌딩하고 싶은 컬럼의 이름이 다르다면 데이터 탭에서 맵핑 해줘야 함
3. 조인 vs 블렌딩
- 조인은 결합 시키고 들어가는 거고, 블렌딩은 결합 이후에 들어가는 것! 즉, 시트 당 한 유형의 블렌딩만 가능
- 조인은 행 수준에서 데이터를 조합할 때 사용
- 블렌딩은 데이터 소스가 다른 세분화 수준을 가졌을 때 사용
- 데이터 소스가 다른 시스템에서 올 때도 블렌드를 사용, ex) 엑셀-sql은 조인 불가능
4. 데이터 모델
- 데이터 모델은 논리 계층, 물리 계층으로 나뉜다
- 조인은 테이블 더블 클릭으로 물리 계층으로 들어가서 수행
- 관계는 조인보다 더 유연!
-> 뭘 사용할지 모르겠으면 관계를 사용
5. 이중축
- 축 동기화 필수
- 차트 앞 뒤로 움직일 수 있음! 열, 행 순서 변경으로
6. 블렌딩 시 계산된 필드
- 그 값들은 집합된 것! 블렌드의 성질에 따라 집합
- 알맞게 조절 필요
문제
테이블 중 하나의 조인 절에 중복 값이 있다면?
> 중복을 수용하기 위해 다른 테이블의 일치하는 행이 복제
여러 컬럼에 조인해야 하는 경우 단일 컬럼에 조인하면?
> 이유 없이 행이 중복, 잘못된 인사이트
언제 데이터 조인이 아닌 데이터 블렌딩을 사용?
> 데이터 세분화 수준이 다른 경우 (월별 vs 분기별), 데이터가 서로 다른 데이터 소스에서 제공
💪🏻 앞으로 개선해야 할 점 (추가로 배워야 할 점)
📌 태블로 너무 재밌다! 문제가 있다면 디테일한 사용법을 정리해놓고 보고 싶은데
텍스트가 길어져 깔끔하게 정리하기 힘들다
깔끔하게 정리할 수 있는 방법 고민해 보기
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] Tableau 고급 #1 (230303) (0) | 2023.03.06 |
|---|---|
| [STARTERS 4기 TIL] Tableau 기초 #2 (230302) (0) | 2023.03.02 |
| [STARTERS 4기 TIL] Design Thinking #3 (230227) (0) | 2023.02.27 |
| [STARTERS 4기 TIL] Design Thinking #2 (230224) (0) | 2023.02.24 |
| [STARTERS 4기 TIL] Design Thinking #1 (230223) (0) | 2023.02.23 |



