
ilovechoonsik
[STARTERS 4기 TIL] SQL 심화 #1 - 데이터 파악 (230410) 본문

📖 오늘 내가 배운 것
1. 환경 구축
2. 분석 프로세스
3. ERD 및 데이터셋 파악
1. 환경 구축
1. PostgreSQL
Community DL Page
Note: EDB no longer provides Linux installers for PostgreSQL 11 and later versions, and users are encouraged to use the platform-native packages. Version 10.x and below will be supported until their end of life. For more information, please see this blog p
www.enterprisedb.com
2. pgAdmin 4
pgAdmin 4를 통해 PostgreSQL이 잘 설치되었는지 확인한다!
3. dbeaver
Download | DBeaver Community
Download Tested and verified for MS Windows, Linux and Mac OS X. Install: Windows installer – run installer executable. It will automatically upgrade version (if needed). MacOS DMG – just run it and drag-n-drop DBeaver into Applications. Debian package
dbeaver.io
2. 분석 프로세스
1. 데이터 분석 프로세스
📌 전반적인 프로세스
분석 목적 설정 -> 지표 설정 및 분석 계획 <-> 데이터 추출/정제/가공/분석 -> (BI, Python, R, Spread Sheet) -> 리포트 작성 및 발표
✅ SQL은? 데이터 추출/정제/가공/분석 단계에서 사용
실제 분석은 다른 툴들과 연동하여 작업을 하게 된다! 시각화 기능이 없기 때문에 한계가 있다.
시스템들 -> DB에 데이터 쌓이고 -> ETL 통해 -> 데이터 웨어하우스로 -> SQL 및 다양한 도구 이용해서 분석 -> 발표 (시각화 보고서 대시보드 논문)
📌 SQL 및 다양한 도구 이용해서 분석 (상세히)
1. 탐색 - 데이터 관련 주제는? 데이터는 어디서 생성? 저장된 테이블은?
2. 프로파일링 - 데이터를 파악하는 단계! 데이터 정합성, 품질, 분포 등 파악 (고유값, 개수, 값의 분포/범위, 이상치, 중복값, 결측값 등)
3. 정제(전처리) - 프로파일링을 통해 확보한 잘못된 데이터, 불완전한 데이터, 결측값 처리, 형변환
4. 셰이핑 - 분석할 결과 테이블을 만드는 과정 (테이블 조인, 컬럼 선택, 집계 등)
5. 분석 - 통계, 시각화 등
2. 데이터 분석의 다양한 분야 및 목적
- 마케팅, 영업, 유통, 제품 개발, 사용자 경험 설계, 고객 지원, 인적 관리 등
- 고객의 행동과 특성 이해
- 견적
- 성과 예측
- 예산 절약
- 리스크 관리
- 제품 개발
- 마케팅 최적화
- 이상거래 탐지 등
📌 거의 모든 분야에서 다양한 목적으로 데이터 분석 활용!
📌 조직마다 특성, 분석목적이 다르고 데이터도 제각각
➡️ 조직이 속한 산업 분야의 도메인 지식과 데이터의 특성을 이해하는 것이 중요
3. 지표 설정 및 분석 계획
✅ 분석 업무는 질문에서 시작한다.
- 지난달에 비해 신규 고객이 얼마나 많이 유입? -> 고객 유입
- 월별 판매 추이가 어떠한가? -> 월별 판매액
- 이탈 고객과 충성 고객의 행동 패턴은 어떤 차이?
➡️ 질문에 답하기 위한 분석 지표 설정
✅ 질문에 답하기 위한 데이터는 어디에서 나오고 어디에 저장되는가?
- 여러 데이터 베이스가 존재하고, 이것들을 통합 관리하는 데이터 웨어하우스
4. 데이터의 종류에 따른 특성
✅ 업무 데이터 - 갱신형(실시간 갱신), 정합성/정확도(JOIN 많이 사용), 정규화
- 기업의 비지니스 결과로 생성된 데이터
- 마스터 데이터(정보데이터) : 고객정보, 상품정보, 카테고리정보 등
- 트랙잭션 데이터(행동데이터) : 구매, 배송, 리뷰작성 등 - 마스터 데이터와 JOIN을 자주 함!
✅ 로그 데이터 - 누적형, 변경 X
- 사용자의 접속시간, 클릭이벤트, IP, 기기, 세션 등의 정보를 저장한 데이터
- 사용자 행동 분석을 통해 웹/앱의 UI/UX 개선하고자 할 때 주로 사용
- 정확도는 업무데이터에 비해 낮음 (크롤러의 로그 포함 고려 필요)
3. ERD 및 데이터셋 파악
1. northwind 데이터셋 개요
전 세계에 식품을 수출하는 가상의 식품회사의 샘플 데이터
2. ERD
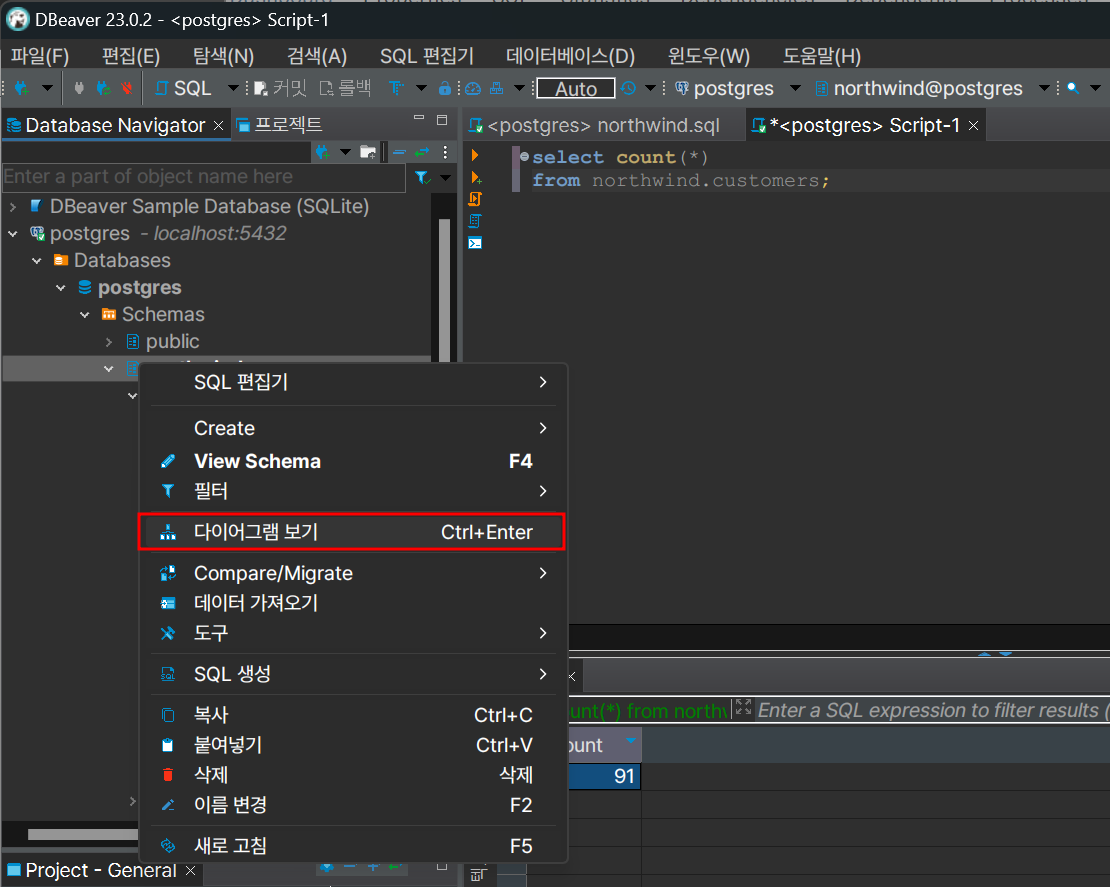

DBeaver에서는 컬럼-테이블-스키마 전부 다이어그램 확인할 수 있따!
3. ERD 표기법
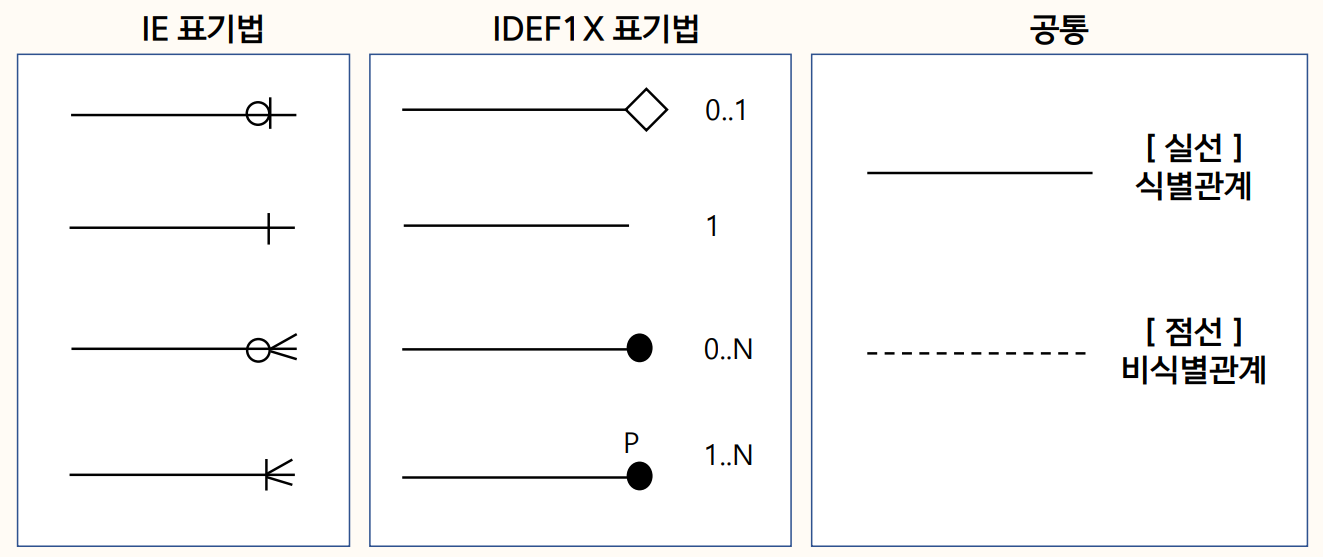
Foreignkey가 일반 속성 = 비식별관계
식별관계 : 부모 테이블의 p-key를 자식 테이블이 자신의 p-key로 사용하는 관계
부모 테이블의 키가 자신의 p-key에 포함되기 때문에 반드시 부모 테이블에 데이터가 존재해야 데이터를 입력할 수 있다
즉, 부모 데이터가 없다면? 자식 데이터는 생길 수 없음!
비식별관계 : 부모 테이블의 p-key를 자신의 p-key로 사용하지 않고, f-key로 사용하는 관계
자식 데이터는 부모 데이터가 없어도 독립적으로 생성될 수 있다
# 부모-자식이란 카테고리-서브 카테고리 느낌의 계층적 관계인 거 같다!
4. ERD 파악 연습
📌 categories와 products 관계
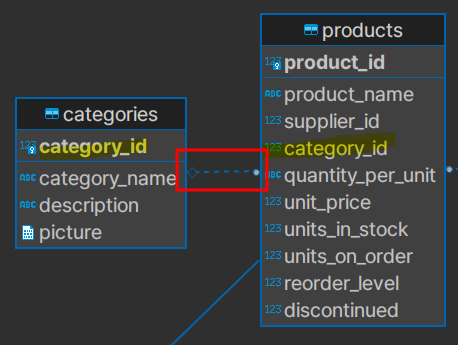
---------- = 비식별관계! 부모 테이블인 categories의 p-key를 products는 f-key로 사용한다
서로를 바라보는 시점?
categories -> products = 0..N
products -> categores = 0..1
고럼?
[categories] 0~1 <------> 0~N [products]
즉, 0~1개의 category에 0~N개의 products가 존재할 수 있다.
제품이 없는 카테고리가 존재할 수 있다.
카테고리가 없는 제품이 존재할 수 있다.
📌 order_details와 orders 관계

점선, 식별 관계 : 부모-자식 사이좋게 p-key를 나눠가지고 있다.
자식은 부모에게 종속! = 부모가 없으면 자식도 없다
서로를 바라보는 시점?
order_details -> orders = 1
orders -> order_details = 0..N
고럼?
[order_details ] 0..N <------> 1 [orders]
즉, 0..N개의 order_details에 1개의 orders가 존재할 수 있다.
주문 없는 주문 상세 목록이 존재할 수 없다.
주문 상세 목록이 없는 주문이 존재할 수 있다.
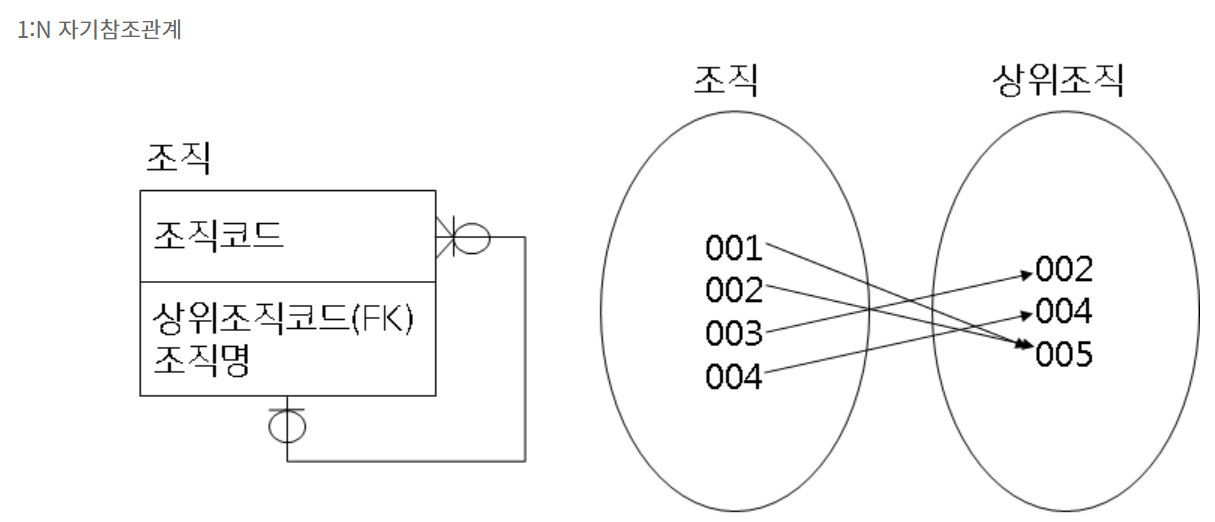
📌 employees 테이블의 자기 참조 관계

하나의 엔티티가 다른 엔티티가 아닌 자기 자신과 관계를 맺는 타입!
1:1, 1:N, N:N 다양하게 사용할 수 있지만, 주로 1:N으로 사용하고 조직도를 표현할 때 유용

위 employees 테이블 같은 경우는 repots_to column에 각 employee 들이 보고를 올릴 employee(상사)의 id가 포함되어 있다!
요건 1:N 관계
즉, employee_id는 employess 테이블의
PK이자 FK
5. 속성 (attribute, column)
테이블 관계를 보고 속성을 파악한다!
기본속성 - 업무로부터 추출한 속성 - 제품명, 제품 단가, 판매날짜
설계속성 - 모델링을 위해 생성된 속성 - 코드, 일련번호
파생속성 - 다른 속성으로부터 계산되거나 변형된 속성 - 총 주문 금액
6. 식별자
각각의 개체를 구분할 수 있는 결정자
| 대표성 여부 | 주식별자 | Primary Key로 지정 예) 사용자 id 유일성, 최소성, 불변성, 존재성 (null x) |
고객을 고객으로 식별할 수 있는 거 |
| 보조식별자 | Unique로 지정 예) 주민번호, 이메일 주소 |
||
| 속성의 수 | 단일식별자 | 하나의 속성으로만 이루어진 식별자 | |
| 복합식별자 | 두 개 이상 속성으로 이루어진 식별자 | ||
| 스스로 생성 여부 | 내부식별자 | 엔티티 내부에서 스스로 만들어지는 식별자 | Foreignkey가 식별자가 되는 경우! |
| 외부식별자 | 타 엔티티와의 관계를 통해 타 엔티티로부터 받아오는 식별자 | ||
| 대체 여부 | 본질식별자 | 업무에 의해 만들어지는 식별자 | |
| 인조식별자 | 인위적으로 만든 식별자 | 일련번호 |
요런 게 있구나~ 알아두기
7. 정규화
RDBMS에서는 왜 테이블을 분리하여 관리할까? 이걸 정규화라 부른다.
📌 정규화 이유?
- 데이터 중복 피하기 위해
- 데이터 정확성 유지하기 위해
제1 정규화 반복 그룹이 존재하면 안 된다.
모든 행은 식별자로 완전하게 구분
제2 정규화 주 식별자 항목 중 코드화할 수 있는 속성 분리
때내서 하나의 테이블로 만들 수 있겠다~ 싶은 것들!
제3 정규화 일반속성 항목 중 코드화할 수 있는 속성 분리
8. 테이블 조회
ERD 만으로 데이터에 대한 완벽한 이해가 가능할까?
없다~ 추가적으로 확인할 수 있는 자료는 테이블 정의서, 테이블 목록
조회하는 방법은?
DB에는 테이블 정보 및 제약 조건 등을 볼 수 있는 쿼리가 존재

9. 테이블 별 컬럼 조회
쿼리 쏴서 확인할 수 있다!
필요한 정보만 select 해주면 됨!
select table_name, column_name, is_nullable, data_type , character_maximum_length
from information_schema.columns
where table_schema = 'northwind'
order by table_name, ordinal_position ;
테이블 이름, 컬럼 이름, null 가능 여부, 데이터 타입, 최대 가능 길이
데이터 정의서 자료를 받는다면? 아래와 같은 정보를 받을 수 있다!

null이 있는 테이블 확인한 후 해당 테이블 컬럼 별로 쿼리를 날릴 수 있따.

# 반복 작업은엑셀에서 이쁘게 만들어서 가져오면 된다!
select count(*) - count( customer_id ) as customer_id
, count(*) - count( company_name ) as company_name
, count(*) - count( contact_name ) as contact_name
, count(*) - count( contact_title ) as contact_title
, count(*) - count( address ) as address
, count(*) - count( city ) as city
, count(*) - count( region ) as region
, count(*) - count( postal_code ) as postal_code
, count(*) - count( country ) as country
, count(*) - count( phone ) as phone
, count(*) - count( fax ) as fax
from customers;
10. 데이터 타입
숫자, 문자, 날짜가 기본적인 데이터 타입
1. 숫자형
| 데이터 타입 | 크기 | ||
| 정수 | smallint | 2bytes | |
| integer | 4bytes | ||
| bigint | 8bytes | ||
| 실수 | 고정소수점 (소수점자리 고정) |
numeric | 가변적 |
| decimal | |||
| 부동소수점 (소수점자리 가변) |
real | 4bytes | |
| double precision | 8bytes | ||
| 자동 증가 정수 | smallserial | 2bytes | |
| serial | 4bytes | ||
| bigserial | 8bytes | ||
정밀한 계산 = 고정 소수점! 1 들어와도 내가 정의한 소수점까지 찍힘 1.0000
부동 소수점 = 수학적 오류가 있을 수 있다.
2. 문자형
| 데이터 타입 | 설명 |
| carh(n) character(n) |
길이가 n인 고정 길이 데이터 타입 |
| varchar(n) character varying(n) |
최대 길이가 n인 가변 길이 데이터 타입 |
| text | 길이 제한이 없는 가변 길이 데이터 타입 (비표준) |
3. 날짜
| 데이터 타입 | 설명 |
| timestamp | 날짜와 시간 - YYYY-MM-DD HH:MI:SS.MS TIMEZONE |
| date | 날짜 (시간 미포함) - YYYY-MM-DD |
| time | 시간 (날짜 미포함) - HH:MI:SS.MS [TIMEZONE] |
| interval | 날짜 차이 - 1days, 1mon, 1year |
interval = 날짜 차이를 다루는 자료형
11. 테이블 별 컬럼 조회
테이블 별로 분석을 하며 다음과 같은 사항을 확인한다
식별자는 무엇?
연관된 테이블은 무엇?
어떤 속성으로 구성?
값의 개수/분포/범위는?
그래서 우리 고객은 누구냐!?
PK는 어떻게 생성되나?
어떤 데이터가 들어있나?
전체 레코드 수?
어떤 속성으로 구성이 되나 - 우클릭 VIEW 사용해서 확인
컬럼 별 NULL 개수
고객 직함 별 데이터 수가 어떻게 되는지
국가별 고객 수 - 주로 어떤 나라 대상으로 영업을 했나
국가 도시 별로 확인
데이터 사전 작성
예시로
CUSTOMER의 특징을 정의하면?
기업고객!
21개 국가에 분포~
국가는 USA의 고객 수가 많다
도시는 UK의 London 고객 수가 가장 많다.
오후에 할 과제가? 테이블 안에 내용들도 보고 northwind 데이터를 보고 어떤 회사인지 파악하는 것!
고객 어디에 있는지, 뭘 파는 회사인지 등등
null 개수 확인하는 것도 중요하다~
select count(*)
from northwind.customers;
# 스키마에서 테이블 조회!
select *
from PG_TABLES
where SCHEMANAME = 'northwind'
order by 2;
# 테이블 데이터 갯수 확인
# 사실 Tables를 View로 보면 다 나옴
select count(*)
from us_states t;
# customer_~ 애들 확인
select *
from categories c;
#컬럼 정보 조회 후 tablename과 ordinal_position으로 정렬!
select table_name, column_name, is_nullable, data_type , character_maximum_length
from information_schema.columns
where table_schema = 'northwind'
order by table_name, ordinal_position ;
# null 갯수 확인하려면? 전체에서 빼야 한다~
select count(*) - count(description) as region
from categories c ;
# 반복 작업은엑셀에서 이쁘게 만들어서 가져오면 된다!
# 아래는 customers의 null 갯수
select count(*) - count( customer_id ) as customer_id
, count(*) - count( company_name ) as company_name
, count(*) - count( contact_name ) as contact_name
, count(*) - count( contact_title ) as contact_title
, count(*) - count( address ) as address
, count(*) - count( city ) as city
, count(*) - count( region ) as region
, count(*) - count( postal_code ) as postal_code
, count(*) - count( country ) as country
, count(*) - count( phone ) as phone
, count(*) - count( fax ) as fax
from customers;
# employees 의 null 갯수
select count(*) - count( employee_id ) as employee_id
, count(*) - count( last_name ) as last_name
, count(*) - count( first_name ) as first_name
, count(*) - count( title ) as title
, count(*) - count( title_of_courtesy ) as title_of_courtesy
, count(*) - count( birth_date ) as birth_date
, count(*) - count( hire_date ) as hire_date
, count(*) - count( address ) as address
, count(*) - count( city ) as city
, count(*) - count( region ) as region
, count(*) - count( postal_code ) as postal_code
, count(*) - count( country ) as country
, count(*) - count( home_phone ) as home_phone
, count(*) - count( extension ) as extension
, count(*) - count( photo ) as photo
, count(*) - count( notes ) as notes
, count(*) - count( reports_to ) as reports_to
, count(*) - count( photo_path ) as photo_path
from employees e;
# 제품이 뭐 있는지 확인! 구글링 하며~
select *
from products p;
# orders 보며 언제까지 주문이 된 데이터냐 등등
# 전반적인 컬럼 속성, 데이터 구조, 안에 존재하는 데이터들이 어떤 느낌인지 파악을 하면 된다!
select *
from orders o;
select *
from employees e;
select *
from customer_customer_demo;
select *
from
# 어떤 직원이 제일 많이 실적을 내는가
select o.employee_id
, ROUND(sum(unit_price * quantity * (1-discount)))
from order_details od
LEFT join orders o on o.order_id = od.order_id
group by o.employee_id
order by 2 DESC;
# 어떤 그룹에 고객들이 많이 분포하나! or 많이 팔아주나
select *
from order_details od
LEFT join orders o on o.order_id = od.order_id
left join customers c on o.customer_id = c.customer_id
;
# 어떤 회사의 total_sales가 가장 높은지
select company_name
, ROUND(sum(unit_price * quantity * (1-discount))) as total_sales
from order_details od
LEFT join orders o on o.order_id = od.order_id
left join customers c on o.customer_id = c.customer_id
group by company_name
order by 2 DESC
# 어떤 회사의 주문 건수가 가장 많은지
select c.company_name
, COUNT(distinct o.order_id)
from order_details od
LEFT join orders o on o.order_id = od.order_id
left join customers c on o.customer_id = c.customer_id
group by 1
order by 2 DESC;
select COUNT(distinct order_id)
from orders o
left join customers c on o.customer_id = c.customer_id
# 회사 주문건수 + 주문비용
select c.company_name
, COUNT(distinct o.order_id) order_cnt
, ROUND(sum(unit_price * quantity * (1-discount))) as total_sales
from order_details od
LEFT join orders o on o.order_id = od.order_id
left join customers c on o.customer_id = c.customer_id
group by 1
order by order_cnt D, total_sales DESC;등등
💪🏻 좋았던 점, 앞으로 개선해야 할 점 (추가로 배워야 할 점)
📌 기존 수업에서 기초적인 문법들을 학습했다면,
요번 심화 수업에서는 실제 분석에 사용하는 프로세스와 주요 지표들을 추출할 때 필요한
난이도 있는 쿼리를 학습한다~
분석 프로세스도 쿼리도 전부 내 것으로 만들기 위해 노력하자!!🫠🫠🫠
#유데미, #유데미코리아, #유데미부트캠프, #취업부트캠프, #부트캠프후기, #스타터스부트캠프, #데이터시각화 #데이터분석 #태블로
'STARTERS 4기 🚉 > TIL 👶🏻' 카테고리의 다른 글
| [STARTERS 4기 TIL] SQL 심화 #3 - WINDOW 함수, employees 테이블 분석 (230412) (0) | 2023.04.13 |
|---|---|
| [STARTERS 4기 TIL] SQL 심화 #2 - 기초 복습, 매출 지표 분석 (230411) (0) | 2023.04.12 |
| [STARTERS 4기 TIL] 프로젝트 기반 태블로 실전 트레이닝 #20 - 태블로 자격증 공부 #3 (230407) (0) | 2023.04.08 |
| [STARTERS 4기 TIL] 프로젝트 기반 태블로 실전 트레이닝 #19 - 태블로 자격증 공부 #2 (230406) (0) | 2023.04.08 |
| [STARTERS 4기 TIL] 프로젝트 기반 태블로 실전 트레이닝 #18 - 자격증 공부 #1 (230405) (0) | 2023.04.08 |



